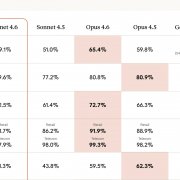
在C++裡,用單引號包含的文字不一定是字元,用雙引號包含的文字也不一定是字串,在只有ASCII時,char可以代表字元,而為了支援Unicode,有了wchar_t、char16_t、char32_t等型態,區分字元碼點與編碼,是搞清楚一切的不二法則。
字元?多位元組字元?
在C++中可以用char來儲存字元,就現今來說,這句話非常模稜兩可。
一般而言,char用來儲存字元資料,sizeof(char)是1,容納ASCII字元是沒有問題,然而,並沒有規範char如何儲存字元。事實上,絕大多數編譯器儲存ASCII字元時,都對照ASCII編碼,而ASCII並沒有區分字元集與字元編碼,或者說它既是字元編碼,也是字元集。
在表示ASCII中的字元時,char確實就代表字元,然而,可以將一個中文字元指定給char嗎?char t = '林'會引發編譯錯誤,必須使用char text[] = "林"才可以,那麼strlen(text)傳回值會是多少?
這要看原始碼儲存時的編碼及編譯時設定的選項而定,舉例來說,使用g++編譯不加上任何選項,當原始碼是Big5時,答案會是2;原始碼是UTF-8時,答案會是3;編譯時加上-fexec-charset=BIG5,答案又會是2了。
因為char用來儲存字元資料,然而沒有規範char如何儲存字元,對於char text[] = "林"的情況,應該將text中每個索引位置的char,當成是位元組或者是碼元(code unit),這時char就不是字元了,因為使用多個char來表示一個字元,在C++被稱為多位元組字元(multibyte character),即使用雙引號,"林"確實就是一個字元,而不視為一個字串,技術上來說,是用數個char組成字元,如何組成就要看採用哪種編碼了。
如果採用Big5編碼,那麼"林"是個Big5字元,如果採用UTF-8編碼,那麼"林"是個Unicode字元,現代程式設計鼓勵用UTF-8,若要固定使用UTF-8編碼字串,C++ 17可以在""前置u8,例如char text[] = u8"林",這麼一來,text就會是用UTF-8編碼的char組成的多位元組字元。
擴充字元
如果真要將一個char當成是字元,那就只能表現一個位元組可容納的字元,例如ASCII字元。
為了支援Unicode,C++提供了wchar_t型態,也就是擴充字元(wide character),例如,wchar_t ch = L'林',L'林'寫法是擴充字元常量,wchar_t其實是個整數型態,用來儲存碼點,就現今來說,基本上是指Unicode(不過wchar_t不限於Unicode),也就是說,ch儲存了整數26519,這是「林」的Unicode碼點。
類似地,可以使用wchar_t text[] = L"林信良"來建立擴充字元字串,此時,若透過strlen的wchar_t版本wcslen來計算text的長度,結果會是3,因為有三個Unicode字元。
一般而言,C++開發者經常搞混擴充字元與多位元組字元,它們是兩個不同的東西,這麼說好了,L'林'這個擴充字元儲存了Unicode碼點,若要以UTF-8實現,我們可以使用u8"林"這個多位元組字元。
若搞清楚兩者之間的關係,我們自然就能區別wchar_t與char的差異,也就會知道,所謂wchar_t與char之間的轉換,並不是型態轉換的問題,而是碼點與編碼實現之間的對照。此時,就知道這個問題的理解,基本上涉及Unicode碼點要轉換至哪個編碼,Big5?UTF-8?
在談到wchar_t與char轉換的文件中,經常涉及locale的使用,這是因為,要從locale中得知採用哪個編碼的資訊,如果知道怎麼將碼點轉換至編碼,不用透過locale,也可以實現wchar_t與char之間的轉換,例如在〈字元陣列與字串〉(https://bit.ly/34U8CxF)中,就實現了toCodePoint與toUTF8函式。
wchar_t並沒有規定大小,只要求須容納系統中可使用的字元數量。此外,C++ 11制定了char16_t與char32_t,這會讓人誤以為它們用來儲存編碼。
其實,它們依舊是儲存碼點,只不過char16_t可以儲存的碼點範圍,必須要能夠涵蓋UTF-16編碼可表現的全部字元,使用的字元常量或字串常量前,需加上 u,例如char16_t ch = u'林',char32_t大小必須能涵蓋UTF-32編碼可表現的全部字元,使用的字元常量或字串常量前,要加上U,例如char32_t ch = U'林'。
C++ 20預計會有char8_t,大小必須能涵蓋UTF-8編碼可表現的全部字元,使用的字元常量或字串常量前,要加上u8。
程式庫的支援
char text[] = "林"是C風格的寫法,C++標準函式庫鼓勵使用string,類似地,string name = "林",由於"林"是個多位元組字元,若採用UTF-8編碼,name.length()會是3,代表位元組或碼元的長度,而不是有幾個字元。
雖然不鼓勵C風格字串,不過,C++仍可以透過包含cstring標頭來使用C風格的字串處理函式,其中也都有對應wchar_t的版本,通常是將str前置名稱改為wcs就可以了,wcs就是wide-chararater string的縮寫,而標準輸入輸出,有對應的wscanf、wprintf可以使用,C++的cout也有wcout版本,若要正確地顯示字元,必須搭配正確的locale設定。
至於string程式庫,也有與wchar_t、char16_t、char32_t與char8_t對應的版本,分別是wstring、u16string、u32string與u8string。
接著,我們如果要在string與wstring間轉換,可以使用wstring_convert,其中定義了Unicode與UTF-8/UTF-16間的轉換,例如,將Unicode碼點轉換為UTF-8編碼時,可寫為:
wstring_convert<codecvt_utf8<wchar_t>> utf8; wstring ws = L"良葛格"; string s = utf8.to_bytes(ws);
cout的本質就是輸出串流資料,若終端機是UTF-8編碼,cout << s就可以看到正確的中文,不一定要透過wcout。
然而,為了設定locale,我們在Windows上若使用MinGW-w64,locale loc("cht")後,再進行wcout.imbue(loc),會發生名稱不正確的問題,若透過以下方式建立loc,再wcout.imbue(loc),就可以解決:
ios_base::sync_with_stdio(false); locale loc(std::locale(), new codecvt_utf8<wchar_t>);
區分字元碼點與編碼
在C++中,char過去會被視為字元,是有其歷史上的原因。
就現今來說,char應該被看成是位元組或者是碼元,至於「字元」這個詞,定義一直都很模糊,目前,我建議,大家談到字元時,就是指Unicode字元,這也就是為何Go要定義rune之目的(可參考先前專欄〈從Go學Unicode、UTF〉)。
只要能清楚掌握wchar_t(char16_t、char32_t與char8_t)就是儲存碼點,由多個char組成的多位元組字元,就是字元編碼實現,在這之後,我們面對原始碼編碼、字元字串常量、編譯參數、程式庫,或者是自行實現編碼轉換等的選擇上,就不會迷失方向了。
專欄作者

因在網路上經營「良葛格學習筆記」(openhome.cc)而聞名,曾任昇陽教育訓練中心技術顧問、甲骨文教育訓練中心授權講師,目前為自由工作者,專長為技術寫作、翻譯與教育訓練。喜好研究程式語言、框架、社群,從中學習設計、典範及文化。閒暇之餘記錄所學,技術文件涵蓋C/C++、Java、Ruby/Rails、Python、JavaScript、Haskell等多個領域。
熱門新聞

2026-02-20
2026-02-20


2026-02-20

2026-02-18

2026-02-18