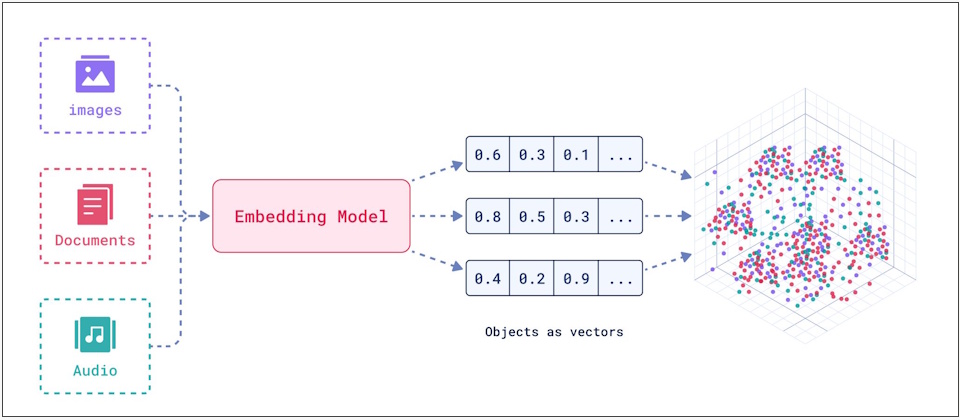
圖片來源/Qdrant
關於資料的向量化處理(Data Vectorization),已成為當前AI應用不可或缺的核心基礎,隨著大型語言模型(LLM)、多模態模型,以及語意搜尋需求的爆發式成長,文字、影像、語音等高度異質的資料,必須以一致且可計算的形式處理,才能支撐即時推論與大規模應用。在這樣的背景下,向量逐漸成為AI系統用於語意理解與相似度計算的重要資料表示方式。
隨著向量資料(Vector data)的迅速膨脹,便需要透過資料庫管理與保存,但面對大量向量資料的處理需求,傳統資料庫在索引與查詢上的限制隨之浮現,這也促使業界發展出針對向量資料最佳化的搜尋引擎,以及向量資料庫,並逐步演化出結合物件儲存的新型架構。
現代AI應用的關鍵:資料的向量化
基本上,資料的向量化處理,以及相關的搜尋與索引技術,在2010年代中、後期便逐漸成熟,但一開始的應用面向十分有限,直到2020年代,才隨著大型語言模型的興起,引爆資料向量化的相關應用。搭配大型語言模型的增強檢索生成(Retrieval-Augmented Generation,RAG)技術,便是當前最重要的資料向量化應用之一。
藉由訓練階段的預先學習,大型語言模型能夠針對多數領域的問題,提供相對合適的回覆。然而,在某些特定知識領域中,由於模型本身知識範圍與更新頻率的限制,其回應的準確性與即時性可能不足。而與大型語言模型結合的RAG技術,便是為了克服這一問題而誕生,這類架構會在模型生成回應之前,先根據使用者提出的問題,透過檢索機制從外部資料庫搜尋相關內容,並將檢索結果提供給大型語言模型整合,從而向使用者提供更精確的答案。
AI應用的基礎:資料的向量化
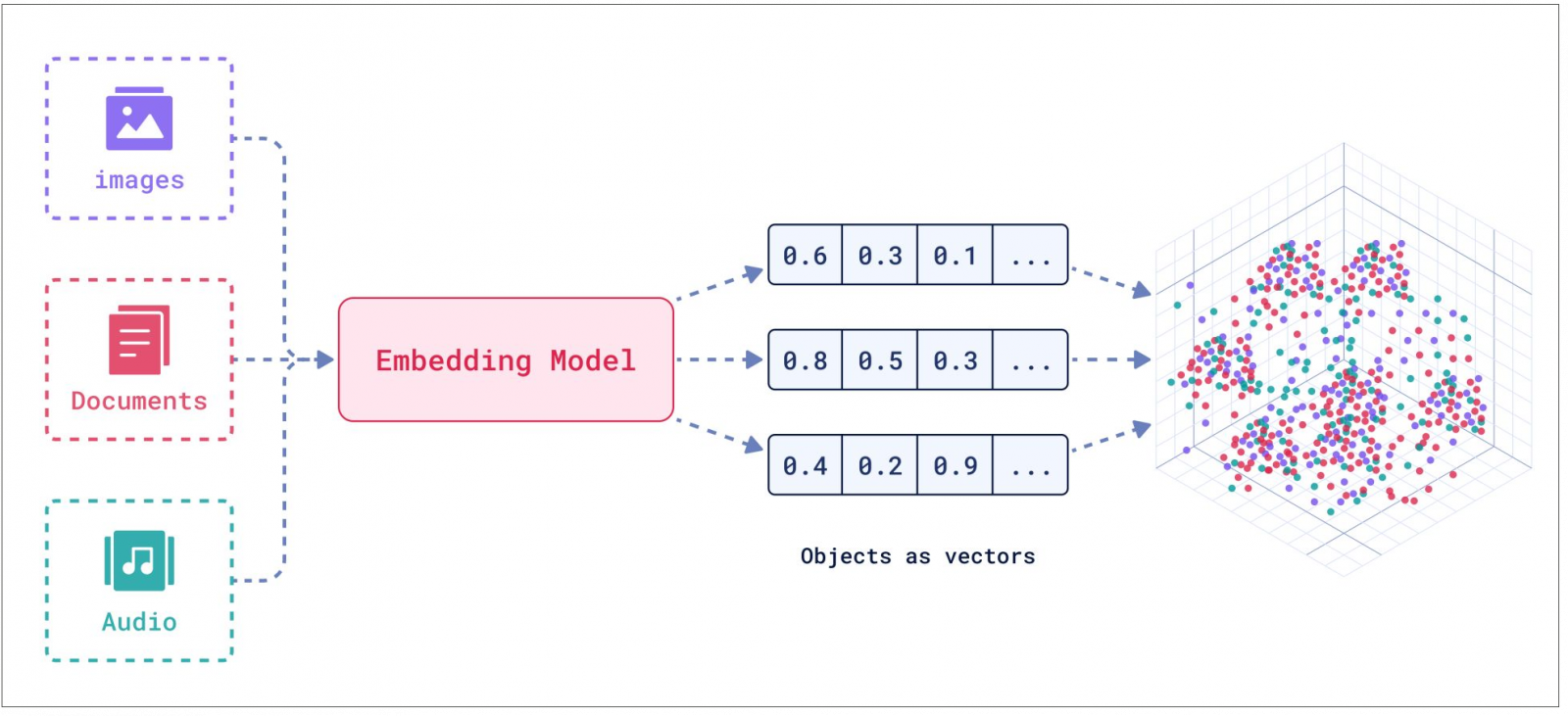
文字、影像與視訊等各式各樣資料,透過嵌入模型(Embedding Model)轉為由數值與維度構成的向量,映射到數值構成的語意空間中,從而便可利用各式各樣的近似演算法,藉由搜尋向量間的相似度,找出最接近使用者需求的回覆。圖片來源/Qdrant
在RAG應用架構中,資料之所以能夠有效率地搜尋與比對,關鍵在於資料內容先被轉換為向量的形式,此一過程稱為向量嵌入(Vector Embedding)。將資料轉為向量後,AI系統可以利用向量之間的相似度,迅速找出最接近使用者需求的內容。
RAG只是向量嵌入的眾多應用之一,當前還有大量其他類型的AI應用,廣泛使用向量嵌入技術,包括:搜尋引擎中的非關鍵字搜尋與語意搜尋、影音平臺的內容推薦系統,社群網站的貼文審核與排序,企業客服系統的AI/FAQ應用,電商網站的商品搜尋與推薦,以及影像、語音等跨模態搜尋與辨識。此外,企業內部知識庫、金融風險控管系統、履歷與人才媒合、以及AI Agent的長期記憶機制等,也都高度依賴向量嵌入作為核心技術。
藉由向量嵌入將資料轉為向量形式,能讓AI應用超越關鍵字比對的限制,深入語意層級的分析與比對,以更貼近人類理解的方式,回應使用者需求。
向量嵌入的基本概念
所謂的向量嵌入處理,是將指定的資料透過專門的嵌入模型(Embedding Model)進行編碼,轉換為數值與維度(Dimension)構成的向量,從而映射到高維度的數值空間,使原本彼此難以比較的資料內容,能藉由數學的方式進行相似度計算與搜尋。
而每一個向量中的維度,代表模型在訓練過程中所學習到的抽象特徵,我們可粗略地將個別的維度,理解為資料對象蘊含的某些特徵或屬性(例如:文字向量可能含有某些主題訊息,影像向量則可能表達顏色、形狀或物體特徵),但這些維度並非人工定義,且個別維度通常不具備直觀、可理解的語意內涵;而維度的數值大小,則代表向量在這個維度上的位置。向量之間在整體空間的相對位置,特別是距離或方向上的差異,能夠反映資料在語意或特徵上的相似程度,用於衡量資料間的相似度。
理論上,向量的維度越高,所能承載的特徵資訊也越豐富,有助於描述較為複雜的資料對象,在實務中,向量的維度通常可達到數百,甚至上千個。然而過高的向量維度,也會帶來運算成本上升、耗用儲存空間增加,以及搜尋效率下降等問題,因此,實際的向量維度設計,通常需在特徵表現能力與系統效能之間取得平衡,並且依照具體應用場景而有所取捨。
藉由將資料轉換為向量形式,AI系統能夠透過向量之間的相似度計算(例如基於向量距離或方向的相似度指標),從大量向量資料中,找出語意上最接近使用者需求的內容,並生成最終回應。
而大量非結構化的文字、影像或其他資料,經由嵌入模型編碼為多個數值所組成的向量資料後,將累積形成大規模的向量集合,若僅以檔案或簡單儲存方式管理,將難以支援高效率的相似度搜尋與即時查詢,因此,需要透過具備索引與查詢能力的資料庫系統,加以保存與管理。
向量資料庫的興起
高維度向量資料的相似度搜尋,在計算的複雜度與資料的規模上,大大不同於以條件比對與索引查詢為主的傳統結構化資料查詢模式,而且,傳統資料庫處理大量向量資料比對時,往往存在明顯的效能瓶頸,難以同時滿足搜尋速度,以及系統擴展性的需求。
因此,業界逐漸發展出專門的向量資料庫,以及配套儲存系統,進而在當前以語意搜尋與生成式AI為核心的應用中,構成不可或缺的關鍵單元,其在索引設計、搜尋效能與系統擴展性上的表現,將直接影響AI系統的回應速度、準確性與實際可用性。
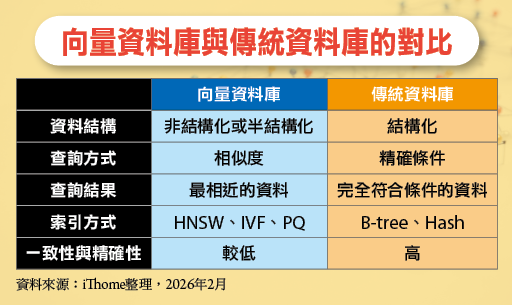
傳統資料庫 vs. 向量資料庫
傳統資料庫與向量資料庫在資料型態與查詢機制存在顯著差異,適用情境也不盡相同。
舉例來說,傳統資料庫基於表格與欄位的概念來管理資料,資料型態為欄位中的值,如數字、字串或日期等,每個欄位皆有明確涵義。資料查詢依據在於判斷資料是否符合使用者指定的條件,屬於以邏輯判斷為基礎的精確查詢。
相對地,向量資料庫是基於座標空間的概念來管理資料,主要資料型態為高維度向量,用以表示資料在數值空間中的位置。向量資料庫運作的核心假設在於:語意或特徵相近的資料,會在向量空間中彼此接近,因此資料查詢時,並非以條件比對為核心,而是依據向量之間的距離或相似度進行排序。
另一方面,傳統資料庫擅長提供精確查詢結果,能依據明確條件找出完全符合的資料,並具備良好的一致性與交易保障,因此適用於結構化資料,以及嚴格要求正確性的應用情境,例如:金流處理、庫存管理與各類交易系統。
向量資料庫大多用於相似度搜尋,通常依據「近似最近鄰搜尋(Approximate Nearest Neighbor,ANN)」技術,在可接受誤差範圍內,提供「最相近的若干筆資料」。因此,向量資料庫不適合在要求嚴格精確性與一致性的應用擔任主資料庫,但適合語意搜尋、推薦系統、文件檢索,以及技術核心為語意分析的AI應用。
傳統資料庫並非無法儲存向量資料,主要限制在於無法有效率地進行向量搜尋,其索引架構(如B-tree或Hash Index)並不能因應高維向量的距離排序需求,當進行相似度查詢時,往往只能透過全表掃描或計算所有向量距離,導致運算成本極高、效能表現不佳,僅適用於資料量較小的場景。
因此,當向量資料的規模成長至一定程度時,便必須依賴專門的向量資料庫系統。這類系統通常針對高維向量的近似最近鄰搜尋(ANN)技術,進行最佳化設計,在搜尋效率、擴展性與搜尋結果品質(誤差範圍)之間取得平衡。
向量資料庫的構成
基本上,向量資料庫是以向量搜尋引擎(Vector Search Engine)為核心,結合資料持久保存、索引管理、查詢介面與系統管理機制的資料庫系統。
向量搜尋引擎可透過各種ANN演算法,如HNSW(Hierarchical Navigable Small World)、IVF(Inverted File Index)、IVF-PQ(Inverted File Index with Product Quantization),以及用於小規模或基準測試的Flat演算法,對大量高維向量建立索引並進行相似度計算,找出與查詢向量在語意空間最近的一組資料(如文件片段或其他資料實體)。
然而,僅有向量搜尋引擎通常難以單獨支撐完整的生產系統,仍需搭配外部的資料庫與儲存系統來管理資料與支援系統運作。在2010年代與更早期的一些資料向量化應用中,大多採用「向量搜尋引擎+第三方資料庫」的架構來運作。
到了2019年前後,隨著資料向量化應用逐漸普及,Zilliz、Weaviate等廠商陸續推出第一批以「向量資料庫」為定位的產品。這類產品以向量搜尋引擎為核心,並整合一系列資料庫與系統層能力,包括metadata管理、安全性與權限控管、索引管理、結構化條件篩選、分散式處理與儲存機制、高可用性與資料複製,以及API與SDK,從而構成可用於生產環境的資料庫系統。
當前的向量資料庫產品底層,通常會支援一或多種向量索引與搜尋機制。例如知名的開源向量資料庫Milvus,即可搭配多種ANN索引機制,如基於FAISS的IVF/PQ索引、HNSW,以及DiskANN等。在實務應用中,開發者仍然可以選擇僅使用向量搜尋引擎(如Meta的FAISS),再自行整合第三方資料庫或儲存系統,以滿足特定需求。
縱覽主要的向量搜尋引擎與資料庫
目前有數十種向量搜尋引擎與資料庫產品,涵蓋開源、商用,以及雲端平臺原生等類型,以下簡要介紹常見產品。
開源的向量資料庫
包括FAISS、Milvus、Qdrant、Weaviate、Apache Lucene、OpenSearch 、Elasticsearch等,大致分為三種類型:單純的向量搜尋引擎、具備向量功能的搜尋系統,以及完整的向量資料庫。
如Meta的FAISS是單純的向量搜尋引擎,Apache Lucene是提供向量搜尋能力的搜尋引擎核心函式庫,OpenSearch與Elasticsearch則是可以提供部分資料庫功能的分散式搜尋系統,Milvus、Qdrant與Weaviate是完整的向量資料庫。
Milvus是目前使用最廣泛的開源向量資料庫之一,並提供商用版本Zilliz Cloud。Qdrant在RAG應用相當常見,Weaviate則以原生整合嵌入模型為其特色,後兩者亦分別提供商用版本Qdrant Cloud與Weaviate Cloud Service。
商用的向量資料庫
較知名的這類產品,包括:Pinecone Systems的Pinecone,DataStax的Astra DB Vector,還有Zilliz Cloud、Qdrant Cloud、Weaviate Cloud Service等。
與開源版本相比,商用版向量資料庫的主要差別,不僅在於支援更大規模的應用,還在於功能完整性、可靠性、管理能力與支援性等方面。
關於功能,商用版通常支援更多索引與搜尋的類型、更複雜的篩選條件,部分產品亦提供GPU加速處理的能力。
在應用規模上,開源版本理論上亦可支援大型向量規模,但往往需要用戶自行投入大量建置與維運成本;商用版則能以託管方式提供大規模擴展能力。
在可用性上,開源版本需由使用者自行建置高可用與災難備援架構,商用版則多半內建高可用性、資料複製,甚至跨區域備援。
就安全性與管理性而言,商用版通常提供完整的存取控制、管理介面、監控儀表板與日誌機制,可降低整體運維門檻,而面對開源版本的使用,企業通常只能透過CLI命令與API來操作。
雲端平臺原生向量資料庫
主要雲端平臺亦陸續在向量資料管理與搜尋方面,推出相關服務,例如AWS的OpenSearch Vector Engine,還有最近新增向量功能的DynamoDB,Microsoft Azure AI Search,以及Google Cloud的Vertex AI Vector Search。
從產品的定位來看,這類服務除了提供向量搜尋相關功能,更重要的目的,是將向量搜尋能力整合進既有的雲端服務。像是OpenSearch Vector Engine、Azure AI Search與Vertex AI Vector Search都偏向於向量搜尋服務,DynamoDB則是在鍵值資料庫上,加入向量搜尋能力。相較於Pinecone、Weaviate等向量資料庫產品,這些雲端原生服務的優勢,在於能深度整合雲端平臺既有管理架構與生態系,讓原本使用該平臺的用戶能快速導入,無須額外建置或搬移資料。

下一代架構:向量資料庫結合物件儲存
隨著AI應用規模持續擴大,向量資料的數量與複雜度,進入快速成長的狀態,也使得向量資料庫的使用成本不斷攀升。事實上,向量資料庫的計費,通常依節點數量與硬體資源(CPU、記憶體、SSD)評估,但也有部分服務,亦會依據查詢或掃描的次數收費。當向量數量增加、維度提高,而且,同時還要求高精度索引與低延遲搜尋時,對硬體資源的需求將顯著上升,進而推高企業的整體擁有成本。
為了能夠緩解上述問題,近來市面上,又陸續出現「向量資料庫結合物件儲存系統」的新架構,這樣搭配的核心概念,在於資料的冷熱分離。
向量資料庫結合物件儲存
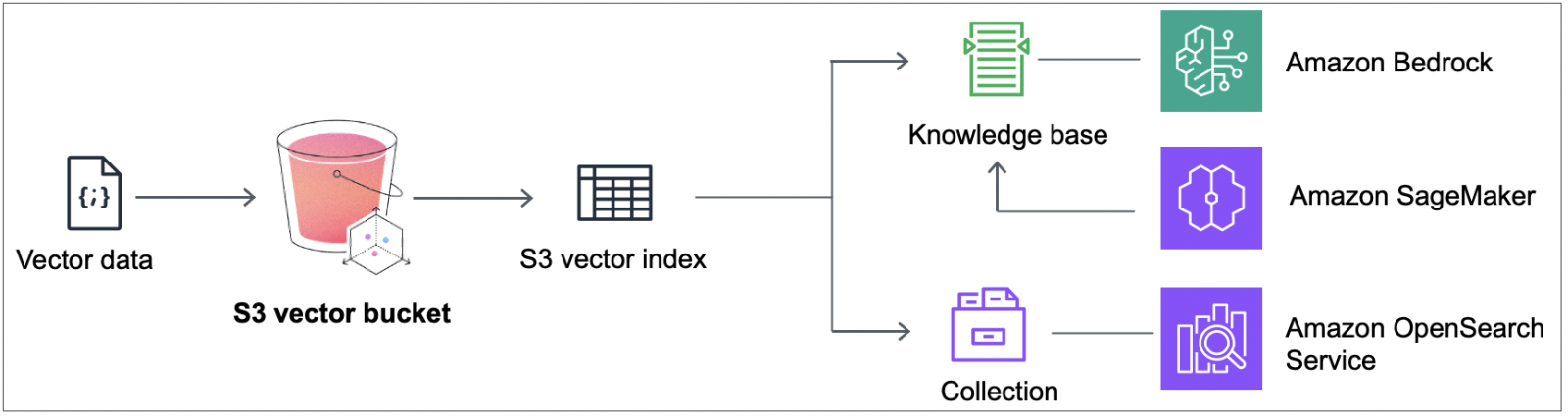
為緩解資料量增加、導致向量資料庫使用成本大幅上升問題,近來出現物件儲存結合向量資料庫的分層架構,將不常存取的資料置於物件儲存區,從而節省成本。上為AWS的S3向量儲存桶,可提供低成本向量儲存空間,並與AWS其他AI應用整合,例如OpenSearch向量搜尋引擎,Bedrock知識庫與SageMaker機器學習服務等。圖片來源/AWS
在傳統向量資料庫的架構裡面,包括向量資料、索引、metadata,甚至部分原始資料片段,通常都集中存放於資料庫節點上。
而在向量資料庫結合物件儲存的架構下,向量資料庫主要扮演搜尋加速層的角色,只存放活躍的向量資料與索引;至於佔用大量空間的原始資料、大型資料集,以及查詢頻率較低的向量資料,則存放於低成本、且可大規模擴展使用規模的外部物件儲存系統中。
這種新架構不僅能顯著降低整體儲存與運算成本,也提升了系統的彈性。例如,當需要更換向量資料庫或重新進行向量嵌入與索引時,原始資料仍保留於物件儲存中,避免被特定資料庫綁定。
不過,採用這種架構的前提是,使用者能接受部分資料存取時增加的延遲。當查詢結果所對應的資料位於外部物件儲存環境時,系統需額外進行一次讀取,通常會因此增加數十毫秒等級或更多的延遲。所以,這種架構不適合對延遲極敏感或檢索頻率極高的應用場景,例如即時推薦系統。
目前已有多家廠商推出基於此概念的解決方案,例如Cloudian透過其HyperStore物件儲存平臺,整合Milvus向量資料庫,提供可擴展至PB乃至EB等級的AI資料平臺;AWS則為其S3物件儲存服務,新增擁有向量資料處理能力的新版S3 Vector,強調快速上線、且能整合AWS既有AI生態系(如OpenSearch、Bedrock知識庫)。
隨AI應用進化的向量資料基礎架構
最後,我們回頭檢視資料向量化應用的發展歷程,可以發現此一領域是在最近三、四年,才從原本的特定領域應用擴展至多個AI領域,並迎來爆發期。
資料向量化與相似度搜尋的理論基礎,早在2000年代前後便已打下基礎,主要用於資訊檢索、機器學習與資料探勘,以及電腦視覺特徵比對等領域。到了2010年代,向量搜尋引擎逐漸成熟,但資料向量化仍缺乏跨領域、通用型的殺手級應用,主要用於推薦系統與部分自然語言處理任務。
2019年後,第一批向量資料庫產品問世,但整體應用仍相對有限。直到2022年以後,隨著大型語言模型的快速普及,才真正點燃向量嵌入技術、向量搜尋與向量資料庫的全面發展。
而資料向量化應用的基礎架構,從最初僅有向量搜尋引擎,演進為完整的向量資料庫,再進一步發展為結合物件儲存的新架構,正反映出AI語意分析應用不斷擴展與深化的趨勢。在可預見的未來,向量搜尋、向量資料庫與相關技術,也將成為連結AI模型與實際資料之間,不可或缺的關鍵基礎設施。


熱門新聞



2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13