圖片來源-/WEKA
隨著GPU的發展與製程的進步,GPU的HBM記憶體容量也持續提高,例如Nvidia在20022年推出的H100,記憶體容量為80GB,到了2024年推出的H200,記憶體容量增加到141GB,但這樣的提升幅度,遠遠跟不上LLMToken處理能力增長,所帶來的KV快取記憶體容量膨脹速度——GPU記憶體頂多以幾十個百分比到倍數增長,但KV快取的容量卻幾乎是以指數幅度增長。
藉由增加GPU數量,雖然連帶也能獲得更多HBM記憶體,但這種作法顯然不合成本效益。
儘管可透過量化(Quantized)、稀疏(Sparsification)等軟體最佳化方法,減少KV快取的記憶體占用量,但這只是治標不治本,最多僅能省下幾十個百分比到數倍的記憶體資源,很快就會被LLM不斷增長的記憶體耗用需求給抵消。
要解決LLM推理過程中的GPU記憶體瓶頸問題,最有效的辦法,是引進可擴展的外部記憶體資源,作為GPU記憶體的補充與替代。
一方面,只要將KV快取卸載到外部記憶體裝置,GPU有限的內建記憶體容量,就不再成為限制KV快取的瓶頸;更進一步,還能透過外部記憶體裝置的擴展能力,因應持續暴漲的KV快取記憶體容量需求。
這也促成各式外部KV快取記憶體技術與解決方案,在近幾個月來不斷湧現,成為當前AI推理應用發展的顯學之一。
截至目前為止,至少已經有7、8家廠商發表外部KV快取記憶體技術或方案,他們對這類技術的稱呼不同,有些稱作KV快取卸載,有些稱作長期或持久性Token記憶體,還有KV快取或Token記憶體設備等說法,但基本概念與目的相同,都是利用網路連接的外部記憶體裝置,來擴展GPU伺服器可用的記憶體資源,將KV快取從GPU卸載到外部裝置上。從這類產品的應用型態與目的——引進位於GPU之外的KV快取記憶體資源來說,我們認為「外部KV快取記憶體」應是較合適的稱呼。
各廠商的目的雖然相同,但實作方式存在著很大差別。有些採用平行檔案系統結合NVMe SSD,有些是基於CXL擴展記憶體技術,還有基於專屬ASIC搭配NVMe SSD的組合,從而帶來大不相同的應用特性。
接下來,我們先依照廠商發表時間先後,逐一檢視目前已發部的幾種外部KV快取解決方案,再探討這些方案的架構特色。
WEKA的增強型記憶體網格
作為平行檔案系統領導廠商之一的WEKA,2025年1月透露,正透過結合Moonshot的LLM分散式服務架構,發展可支援LLM Token快取處理的高速儲存層。一個月後,發表用WEKApod套件幫助LLM縮短Token載入時間的概念與實測結果,藉由WEKApod掛載至GPU伺服器作為外部記憶體空間,將Llama 3模型載入1萬個Token到KV記憶體的所需時間,能因此縮短41倍。
接著WEKA便在2025年3月,正式發布與其平行檔案系統整合的增強型記憶體網格(Augmented Memory Grid,AMG)技術,宣稱可利用NVMe SSD,提供接近記憶體延遲表現的Token資料存放空間,結合分散式架構,建立可擴展的Token倉庫(Token Warehouse)。
WEKA聲稱,傳統儲存架構受限於延遲表現不足,無法提供類似的Token存放能力,他們的增強型記憶體網格技術,則能透過高效能分散式記憶體架構,提供微秒等級(µs)延遲與大規模的平行I/O傳輸能力,填補GPU記憶體與傳統儲存架構之間的效能落差,滿足即時檢索Token所需的吞吐能力,實現GPU外部的Token倉庫概念。
WEKA在GTC 2025大會中,也展出搭配NVidia Triton推理伺服器的AMG解決方案,可從GPU伺服器的HBM記憶體中卸載KV快取,並公開實測表現——處理10.5萬個Token時,相較於重新計算Token,AMG技術可將第1個Token產生時間(Time to First Token,TTFT)縮短41倍,用戶查詢回應時間也顯著縮短,從23.97秒縮短到0.58秒,因此,用戶不需為了獲得更多GPU記憶體,而被迫增加GPU數量。
焱融科技的檔案系統KV快取
中國的焱融科技(YanRong),在2025年4月中旬發表基於其YRCloudFile 分散式共享檔案系統的KV快取技術,基本目的與Weka的AMG技術如出一轍,都是利用基於NVMe SSD的平行檔案系統空間,為GPU提供可擴展到PB等級的KV快取記憶體空間,大幅提高KV快取命中率,以及上下文處理能力。
焱融科技將這種概念稱作「以存換算」,也就是藉由外部儲存設備大幅擴張KV快取記憶體容量,來換取GPU運算力的節省,從而提供高成本效益的LLM推理架構。根據他們公開的實測結果,在超過2萬Token的較長上下文條件下,可縮短3到13倍的第1個Token產生時間(TTFT);在固定TFTT產生時間下,可提升8倍的同時查詢量;在高度平行查詢下,可縮短Token產生時間達4倍。
VAST Data的VUA快取記憶體技術
另一新創分散式檔案系統供應商VAST Data,也在今年2月底推出其稱為VUA(VAST Undivided Attention)的KV快取技術,為了進一步推廣這項技術,還在4月宣布將VUA開源。
就基本概念而言,VUA與WEKA的AMG、焱融的KV快取相似,都是利用整合在檔案系統中的NVMe SSD,擴展GPU可用的KV快取記憶體空間。
VUA是透過安裝在GPU伺服器的Linux-based代理程式來運作,用於管理階層式的KV快取記憶體架構——第1層是GPU記憶體,第2層是CPU記憶體,第3層是透過RDMA網路連接的外部NVMe儲存系統。其中,外部NVMe儲存系統扮演的角色,是提供第3層KV快取,用於保存GPU與CPU記憶體KV快取滿載後、被迫撤出記憶體的Token資料,藉此大幅增加LLM可用的Token資料量。
VAST Data宣稱,VUA技術提供智慧型的前綴搜尋(prefix-search)與索引機制,可以提高快取命中率,而且,比起受限於記憶體分頁結構、只能提供區域快取的GPU與CPU記憶體,VUA技術提供的NVMe外部快取記憶體,是全域的共享空間,可在整個GPU叢集中存取,每臺GPU伺服器都能共享存取相同的擴展上下文快取空間。
但是,VAST Data也承認VUA的共享存取能力仍受到一些因素限制,目前每臺GPU伺服器只能看到各自的分層快取資料,而不能看到彼此的快取內容,所以仍有可能出現快取未命中的情況,他們正考慮發展一種全域分散式快取架構來改善。
VAST Data宣稱VUA技術能提供EB等級容量的KV快取,為LLM提供無限的上下文擴展能力,能縮短第1個Token產生時間(TFTT),也能縮短後續每個Token的平均產生時間(Time Per Output Token TPOT),並持久保存會話狀態,而且藉由將KV快取保存在GPU外部的記憶體裝置上,也能釋放GPU資源。
為了讓大家了解成效,VAST Data也公開VUA技術的實測效果。他們表示,啟用VUA技術後,在3萬個Token等級的環境中的TFTT時間表現,可提升292%。
PEAK:AIO基於CXL的KV快取
英國的新創軟體定義NAS廠商PEAK:AIO,今年5月中旬宣布,正在發展基於CXL記憶體的KV快取卸載解決方案,預定第3季開始生產。
依PEAK:AIO透露的訊息,他們的KV快取記憶體設備,應該是內含CXL記憶體擴充模組的外接式設備,透過RDMA 0ver NVMe-oF介面來連接GPU伺服器,可提供跨不同會話、模型與節點共用KV快取的能力,藉由擴展LLM的上下文區間、保存更長的Token歷史資料。
相較於WEKA、VAST Data等廠商,PEAK:AIO解決方案的最大特色,是以CXL記憶體取代其他廠商使用的NVMe SSD,藉此提供延遲更低、DRAM層級的KV快取記憶體架構,該公司聲稱,他們基於CXL記憶體的Token記憶體裝置,則能在低於5µs的延遲下,提供150GB/s的吞吐率,延遲遠低於其他廠商基於NVMe SSD的方案。
Pliops的附加介面卡記憶體方案
從時間先後來看,以色列新創儲存處理器廠商Pliops在2024年10月發布的XDP LightningAI,算是外部KV快取解決方案的先行者,當時該公司將此產品描述為「提供給GPU伺服器的額外記憶體層」,用於輔助與補充GPU的HBM記憶體,避免GPU因快取記憶體耗盡,被迫重新計算舊Token資料而導致的延遲。
XDP LightningAI本身是基於x86伺服器的外接設備,透過ConnectX-7 400GbE網路卡連接GPU伺服器,使用內含的NVMe SSD充當KV快取記憶體空間,這點和後來WEKA、VAST Data推出的KV快取記憶體方案相同。
Pliops的不同之處在於,WEKA與VAST Data的方案都是純軟體架構,硬體方面使用標準x86硬體與網路卡,搭配各自的專屬檔案系統與前端軟體。Pliops則採用專屬硬體,其XDP LightningAI伺服器內安裝有專屬PCIe卡,利用PCIe卡內含的XDP-PRO ASIC晶片,搭配安裝在GPU伺服器的Pliops KV快取外掛軟體,來執行KV快取卸載工作。Pliops KV快取外掛軟體會透過專屬API,將GPU伺服器的KV快取存取需求,經由400GbE網路發給XDP LightningAI伺服器內的XDP-PRO ASIC晶片,由後者直連底層SSD來處理存取操作。
到了今年5月中旬,Pliops正式推出XDP LightningAI,配套的KV快取外掛軟體FusIOnX,並提供更多樣化的硬體部署型式。
配套的軟體堆疊稱作FusIOnX,由GPU伺服器端的FusIOnX KVIO,與儲存端的FusIOnX KV Store組成。而在XDP LightningAI硬體方面,目前則能提供獨立外接裝置與超融合部署等2種型態,前者採用Dell 2U/24槽伺服器,後者則是將核心的ASIC PCIe卡安裝到GPU伺服器內,並使用GPU伺服器內含的SSD作為KV快取空間。
透過擴展FusIOnX軟體的功能,XDP LightningAI可適用於不同應用,目前推出的是LLM與GenAI版本,接下來還將推出RAG與向量資料庫、GNN(圖像化神經網路)與DLRM(深度學習推薦模型)等版本。
GridGain的共享記憶體方案
不同於前面幾家廠商的外部記憶體方案,GridGain是叢集共享記憶體技術,從不同的面向提供擴展KV快取的方式。
GridGain的軟體是基於伺服器記憶體、低延遲的分散式資料管理系統,開源的版本稱作Apache Ignite,可橫跨整個叢集統合所有記憶體資源,包括x86伺服器記憶體與GPU的HBM記憶體,並提供線上儲存、快取、檢索與搜尋,資料會分散到叢集內的各種記憶體資源中,藉此讓叢集內的伺服器共享記憶體資源,從而克服單一伺服器記憶體不足的問題。
同時,GridGain能擴展生成式AI的會話歷史紀錄範圍,也是其應用面向之一,LLM也能透過這種共享記憶體架構,擴展可用的KV快取資源。
為了保護記憶體中的資料,GridGain還提供多複本的分散複製,以及搭配SSD/硬碟層作為備份的功能。
開源的KV快取卸載方案
除了前面介紹的一系列新創廠商的外部KV記憶體方案外,在開源領域,也已有多種KV快取卸載軟體解決方案可用,如AIBrix、LMCache,以及Mooncake等,都能提供將KV快取從GPU卸載到CPU記憶體或外部儲存設備,克服GPU記憶體容量對LLM推理造成的限制。
不過最值得注意的是這幾個月新發布的2款開源計畫,首先是Nvidia今年3月發布的Dynamo分散式推理服務框架,可以橫跨GPU叢集,提供分散式KV快取管理功能,追蹤整個GPU叢集中KV 快取資料的狀態與位置,將推理過程中的Token需求,導引到保存相關KV快取的GPU,減少重複計算與資料傳輸的消耗。
Dynamo也導入KV快取分層卸載功能,目的是將存取頻率較低或優先順序較低的KV快取資料,從昂貴的HBM記憶體,遷移到成本更低的裝置上,例如共享CPU記憶體、本機SSD或外部網路儲存裝置,從而克服GPU HBM記憶體容量限制問題。不過,目前Dynamo的KV快取卸載功能發展還不完整,可能得等到今年稍晚,才能完全達到規劃中的階層式KV快取卸載功能。
另一值得注意的開源KV快取卸載方案,是隸屬IBM旗下的Red Hat,在今年5月成立開源專案「llm-d」,目的是發展開放標準化的LLM推理架構,開發針對LLM的分散式推理服務堆疊,其中一項核心功能便是KV快取卸載,這是基於前面提到的另一開源方案LMCache而成,可將KV快取負載從GPU,卸到CPU記憶體或網路外部儲存裝置上。
第1波外部KV快取產品初探
初步檢視過這幾個月問世的第1批外部KV快取產品後,我們可以提出幾點觀察:
首先,依據各廠商提供的測試報告,以及在多個公開場合展出的實測結果,我們認為外部KV快取產品,確實能極大提高LLM的推理效率,特別是在長篇會話、需處理長篇上下文的情況下,效益尤大,提升的幅度可以達數倍之多。
其次,目前的外部KV快取產品,通常必須在GPU伺服器端安裝專屬的代理程式或軟體,以便將KV快取需求導到外部設備上,當GPU伺服器在本機KV快取找不到Token時,藉由代理程式的中介,轉到外部KV快取、搜尋與載入Token。但是,部署代理程式的需求,也將帶來相容性與支援範圍等問題。
第三,依照外部KV快取技術使用的儲存媒體,我們可以將這些產品區分為NVMe SSD與DRAM等兩大類型,WEKA、VAST Data 、Pliops與焱融科技屬於NVMe SSD型,PEAK:AIO與GridGain則屬於DRAM型,從而帶來不同的產品特性。
DRAM型解決方案的優勢
基於DRAM的外部KV快取解決方案,最大優勢便是可達到更低的存取延遲,如PEAK:AIO宣稱他們基於CXL記憶體的技術,延遲可低於5µs。相較下,基於NVMe SSD的外接儲存裝置,透過RDMA遠端存取的延遲表現,最少也要30到100µs左右,彼此有著10到20倍的差距。
不過,我們認為,基於NVMe SSD的外部KV快取技術,延遲表現已經夠用,比起KV快取耗盡後,LLM需要重新計算Token所導致的延遲相比,存取遠端NVMe SSD面臨的幾十、上百µs延遲,可說微不足道。
NVMe SSD型解決方案的優勢
另一方面,基於NVMe SSD的外部KV快取技術,則有著成本效益、高擴展性與持久性等3項優勢。
在成本效益方面,NVMe SSD擁有絕對優勢,NVMe SSD與DDR DRAM的單位成本,有著10倍以上差距。以單位容量成本較低的NVMe SSD,來作為Token資料存放區域,可提供更經濟、功耗也更低的Token資料保存方案。Pliops便聲稱藉由引進NVMe SSD,可以HMB百分之一的單位成本,取得可擴展的KV快取空間,這是基於DRAM的方案辦不到的。
在擴展能力方面,相較於內嵌在GPU、難以擴充的HBM,基於DRAM記憶體或NVMe SSD的外部KV快取方案,都能結合分散式架構,提供高度擴展能力,組成PB等級容量的Token存放空間。但NVMe SSD的單位密度更高,成本也更低,擴展能力要比DRAM高出一籌。
最後,不同於屬於揮發性儲存媒體的HBM與DRAM記憶體,NVMe SSD是可持續保存資料的非揮發性儲存媒體。基於HBM與DRAM的Token儲存架構,都只能暫存資料,Token只是推理運算過程的暫時產物,必須依據需求不斷重新計算產生。而透過WEKA增強型記憶體網格技術,則能建立持久保存的Token倉庫,能夠存放數十億個Token資料,並在需要時經由檢索提供給LLM使用。所以LLM計算後產生的Token可以長期保存,並重複使用,不再需要每次都重新計算,這也就是WEKA提出的Token倉庫(Token Warehouse)概念。
結合DRAM與SSD的可行性
進一步來說,在外部KV快取應用中,NVMe SSD與DRAM並非相互排斥,兩種技術而可搭配運用,相輔相成。例如Red Hat的開源專案「llm-d」,Nvidia的Dynamo分散式服務框架,都打算將CPU記憶體與外部網路儲存設備,同時涵蓋在KV快取卸載應用架構。
所以,未來應該會出現一種包含GPU HBM、CPU DRAM、外部DRAM裝置,與外部快閃儲存設備都整合在內,提供階層式的共享KV快取應用架構。
邁向通用標準化的可行性
外部KV快取解決方案這個新興領域,目前的推動主力雖然是由一眾新創廠商,但憑藉LLM應用熱潮引發急迫的擴展KV快取需求,預期接下來各家記憶體與儲存大廠應該都會陸續投入,為其產品整合提供外部KV快取的功能。華為便是一個例子,其高階儲存陣列產品OceanStor A800,便已能提供KV快取應用,支援KV快取的長期記憶儲存。
隨著投入廠商的增加,也將帶來標準化的問題。目前的第1波外部KV快取產品,許多都必須搭配特定的儲存軟體平臺,甚至硬體設備使用。
要建構通用化、標準化的KV快取卸載架構,可能得依靠開源的方案,如基於LMCache的Red Hat「llm-d」,以及Nvidia的Dynamo等,從而將這項應用,推廣成為LLM通用的標準。
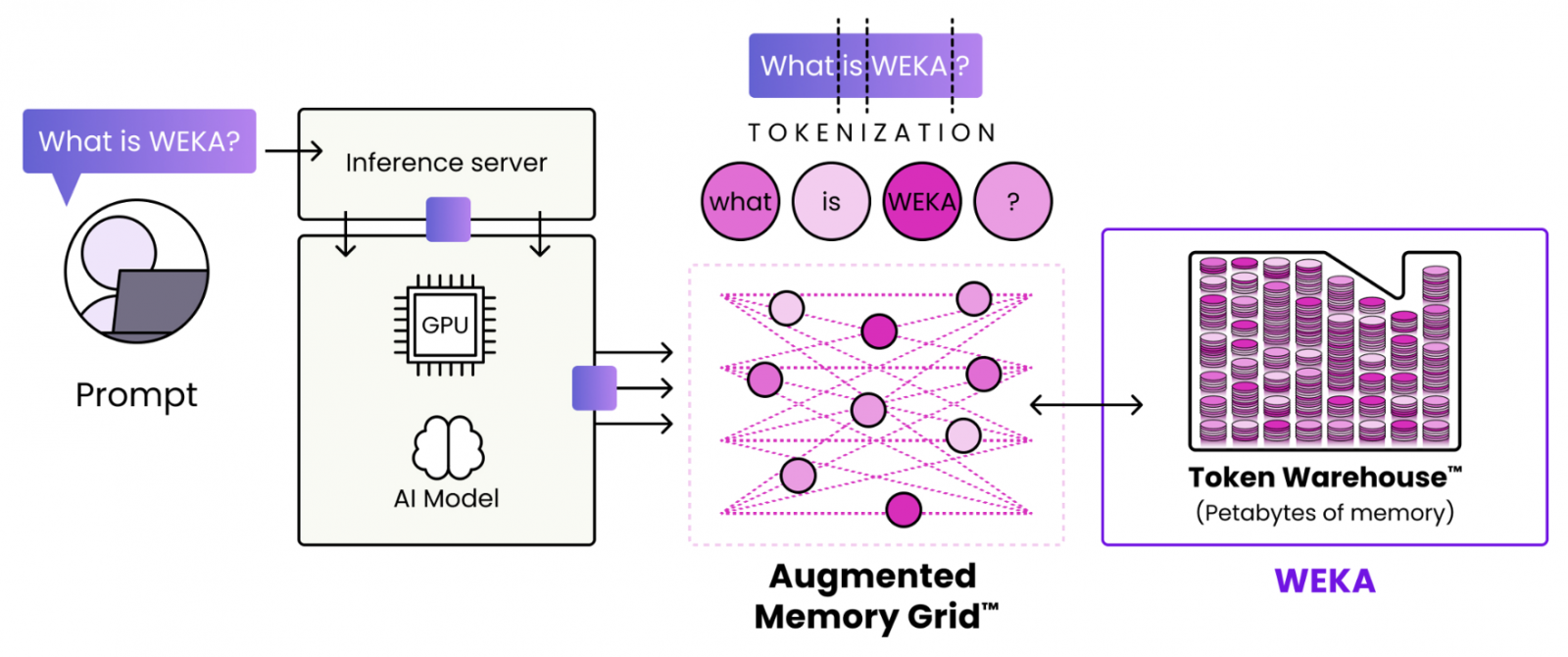
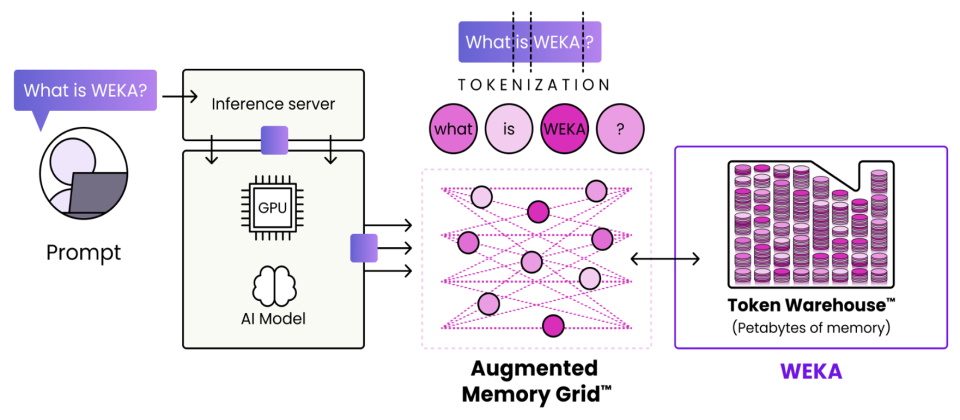
WEKA的增強型記憶體網格技術
透過增強型記憶體網格(AMG)技術,WEKA可將基於NVMe SSD的儲存空間,提供給GPU伺服器,作為長期持續可用的KV快取記憶體,結合PB容量等級的擴展能力,構成龐大的「Token倉庫」,透過持久保存大量Token資料,可經由檢索的方式提供LLM使用。(圖片來源/WEKA)
.jpg)
VAST Data的階層式KV快取架構
VAST Data的VUA(VAST Undivided Attention)KV快取技術,可透過安裝在GPU伺服器上的代理程式,管理階層式的KV快取架構,當GPU在本機HBM記憶體找不到KV快取資料時,導向到外部VAST Data基於NVMe SSD的KV快取空間中搜尋。(圖片來源/VAST Data)
.jpg)
Pliops結合ASIC與SSD的KV快取卸載方案
Pliops的XDP LightingAI也是採用經由網路掛載的外部設備NVMe SSD,作為擴展的KV快取記憶體空間,但NVMe SSD的存取是透過Pliops專屬的XDP PRO ASIC來控制,是當前少見的專屬硬體類型外部KV快取解決方案。(圖片來源/Pliops)
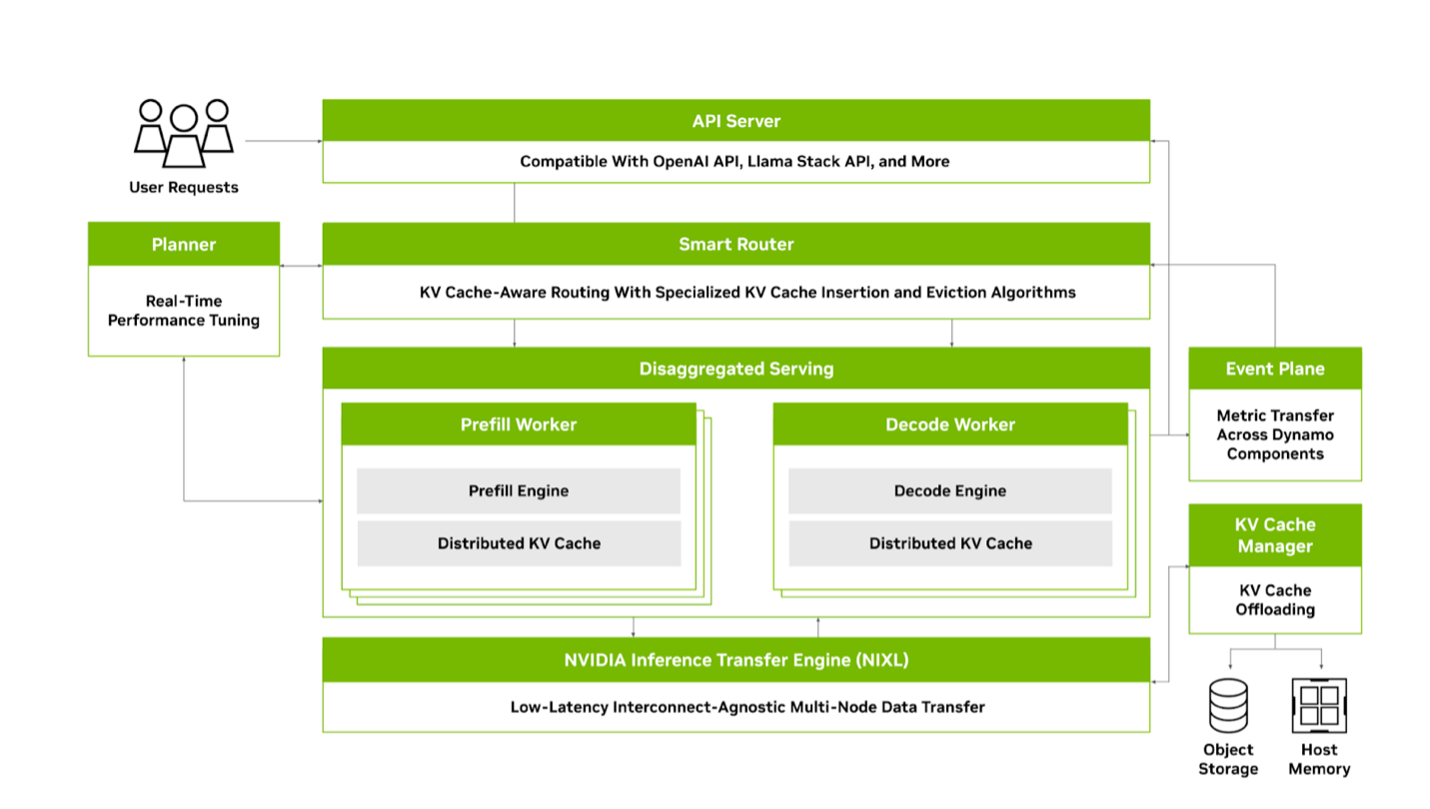
Nvidia Dynamo的KV快取卸載功能
在Nvidia的Dynamo分散式推理服務框架,主要是透過KV快取管理器提供KV快取卸載功能(圖中的右下角),目前能將KV快取從GPU HBM記憶體卸載到主機CPU記憶體,未來還能卸載到本機SSD或外部儲存設備。(圖片來源/Nvidia)

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
