
圖片來源/Pliops
大型語言模型(LLM)是當前AI技術發展與應用中,最受矚目的熱點,經過數年的發展後,新一代LLM已擁有處理與生成長篇對話文本的能力,可以和用戶進行越來越複雜的會話(Session),產生詳細的長篇幅回覆內容。
但LLM為了能更有效率地生成長篇對話內容,用於保存推理過程Token資料的KV快取(Key-Value cache)記憶體需求,也不斷暴漲,形成LLM應用的記憶體瓶頸。
為了克服這個問題,近幾個月來,市面上湧現一批外部KV記憶體技術與解決方案,也形成AI基礎架構新興的嶄新類別。
LLM不可或缺的KV快取
LLM生成會話文本的推理運算過程,是將會話內容文字拆解為個別Token,作為基本處理單位,並依據先前計算出的Token,依序推算與產生下一個Token,最後形成完整的會話內容,而推理過程的每一次推算,都需要重新計算整個序列先前所有的Token。
而KV快取存在的目的,則是在GPU記憶體中,LLM能夠以Key-Value的形式保存先前計算出的Token,到了後續推理過程中,LLM便能依據KV快取保存的先前Token,推算出新的Token,免去每一步都需要重新計算所有Token的麻煩。
也就是說,KV快取能讓LLM「記住」已經處理過的內容,從而提供立即可用的「短期記憶」資料,藉此可帶來兩大優勢:
●節省運算資源:模型可直接從KV快取獲得先前的Token,不需要重新計算。
●近乎即時的回應:模型從KV快取獲得先前的Token資料後,便可立即產生下一個Token,回應使用者的查詢需求,省下重新計算先前Token所造成的延遲。
為了能以更有效率的方式生成長篇會話文本,KV快取資料量需求也越來越大。擁有更大的KV快取記憶體,LLM就可以保存更長篇上下文的Token資料,也就是擴展上下文區間(context window)的大小,幫助產生更精確、詳細的會話回覆。
擴展KV快取的急迫需求
問題在於,GPU的HBM記憶體容量是有限的,隨著LLM參數量的增加,模型本身占用的記憶體也持續增加,耗用數百GB記憶體已是司空見慣,這也使得GPU記憶體逐步滿載,限制了KV快取所能使用的記憶體空間,以及所能保存的Token資訊量。
另一方面,隨著LLM企圖處理的上下文內容越長,又會讓KV快取所需保存的Token資料量迅速膨脹。
舉例來說,Meta在2023年推出的Llama 1模型,只支援最大2,048個Token的上下文區間,2025年最新推出的Llama 4模型,支援的上下文區間已達到100萬個Token,處理與生成長篇會話的能力,有著飛躍性的提高,但連帶的,KV快取需求也隨之暴漲。對於當前的LLM,僅僅一次會話耗用的KV快取記憶體,可能就會達到數GB以上。
這便形成一個矛盾:GPU記憶體容量有限,但LLM的上下文窗口不斷增長,帶來KV快取需求近乎無止盡增加。同時,也意味著,KV快取已成為當前限制LLM效能的主要瓶頸。
外部的KV快取記憶體方案
要解決LLM推理過程中的GPU記憶體瓶頸問題,最有效的辦法,是引進可擴展的外部記憶體資源,作為GPU記憶體的補充與替代。
一方面,只要將KV快取卸載到外部記憶體裝置,GPU有限的內建記憶體容量,就不再成為限制KV快取的瓶頸;更進一步,還能透過外部記憶體裝置的擴展能力,因應持續暴漲的KV快取記憶體容量需求。
這也促成各式外部KV快取記憶體技術與解決方案,在近幾個月來不斷湧現,成為當前AI推理應用發展的顯學之一。

擴展KV快取的效益
LLM是透過KV快取,來保存推理過程中會話文本的Token,但KV快取耗盡後,部分Token退出快取後,當模型日後需要這些Token時,便須重新計算整個會話序列中前面的Token,導致GPU耗費大量時間,重複計算先前已經算過的Token(如上圖左),並造成整個推理過程的延遲。
而透過外部裝置來擴展KV快取,便能保存所有的Token資料,避免重複計算Token,不僅節省可觀的GPU運算時間,也能顯著減少推理過程的延遲(如上圖右)。(圖片來源/Pliops)
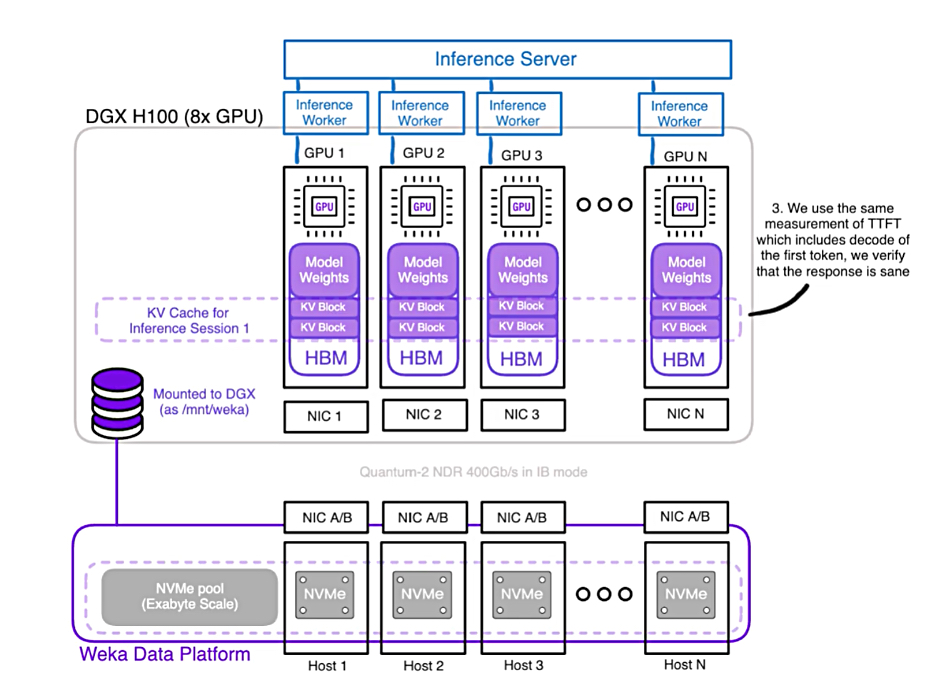
典型的外部KV快取解決方案架構
此圖是WEKA的增強型記憶體網格(Augmented Memory Grid,AMG)技術架構,WEKA的儲存平臺藉由RDMA網路連接前端的GPU伺服器,可將WEKA平臺基於NVMe SSD的儲存空間,掛載到GPU伺服器上,作為擴展的KV快取記憶體空間,從而加速推理工作。(圖片來源/WEKA)

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
