
圖片來源/VAST Data
我們前面檢視了當前新一代平行檔案儲存平臺的生態,包括主要產品與供應商的概況,這些平臺雖然同樣以提供超大規模擴展能力、高傳輸效能為目的,但技術路線大相逕庭,這也形成各產品的特色所在。
實現目標的不同路線
以平行檔案系統的基本概念而言,是大規模儲存叢集,與用戶端平行存取架構的結合,由儲存節點組成的叢集,提供了可靈活擴展的儲存環境;平行存取架構則透過匯聚多條I/O路徑,提供了高傳輸效能。如今,在兩者結合之後,便能提供AI與HPC應用所需的龐大資料儲存空間,與資料吞吐能力。
因此,所有平行檔案系統都能提供極龐大的叢集擴展能力,並匯聚出極高的傳輸效能。以我們這次介紹的新一代平行檔案系統為例,除了Qumulo叢集規模較小外(最大265節點),其餘都能提供非常龐大的叢集擴充能力,例如VAST Data、Weka、Quobyte的叢集最大規模,原則上沒有限制,上千節點是可行的,Hammerspace雖然規格上只支援最多64臺資料服務節點,但該公司表示叢集的節點數量實際上沒有硬性限制。
然而,在前述共通的基本概念之上,不同產品之間、在叢集的組成與管理方式,以及用戶端採用的平行存取架構形式等方面,則有著不同的選擇。
叢集組成型態
平行檔案系統的叢集形態,目前是以「無共享」(shared-nothing)架構為主流,另有少數平臺採用「分解」(Disaggregated)式架構。
「無共享」是最常見的叢集架構,每臺節點都擁有獨立的處理器、記憶體與儲存空間,各節點都能獨立回應前端的I/O存取需求。這種架構的優點是叢集組成較為單純,只需部署與管理1種節點,缺點是擴充較不靈活,無法單獨擴充運算或儲存資源,任一節點失效時,會同時損失該節點的運算與儲存資源。
至於所謂的「分解」式架構,則是將運算與儲存功能分解,各自經由獨立的運算與節點承擔,運算節點負責I/O傳輸與存取處理,儲存節點提供儲存空間。優點是可提供更精細的管理粒度,可視需要個別擴充運算與儲存節點,任一節點失效的影響也較小,只會損失該節點角色的運算或儲存資源。缺點則是後端網路連接架構相對複雜許多,必須讓所有運算與儲存節點彼此互連。
在新一代平行檔案系統中,絕大多數都是採用無共享叢集架構,包括Weka、Quantum、Quobyte與Qumulo等。
VAST Data的「分解與共享一切」(DASE)叢集架構,是分解式架構的代表,沿用VAST Data核心平臺的HPE Alletra MP for File Storage,也屬於這種架構。其他只有DDN新推出的Infinia,也採用類似的分解式架構。
metadata管理架構
對於採用叢集架構的平行檔案系統,由於每個檔案都被分割、分散存放在不同節點上,檔案系統則透過metadata來記錄資料實體儲存位置,因此所有存取作業都必須透過查詢metadata,來確認資料實體位置,所以在平行檔案系統的存取作業中,metadata查詢操作占有很高比重,如何存放與處理metadata,也就成為平行檔案系統的一大重點。
平行檔案系統的metadata管理,可分為分散式與集中式等兩大類型,各有利弊,各有支持者,老牌平行檔案系統中,IBM GPFS是分散式metadata的代表,Lustre則是集中式metadata的代表。
集中式的metadata管理架構,是將metadata管理交由獨立的metadata節點負責,可讓資料I/O存取操作,與metadata查詢作業各自分離,兩者互不干擾。不過metadata節點本身也會形成效能瓶頸,並有單點故障問題,一旦metadata節點失效,整個叢集也會跟著無法運作。因此metadata節點本身也需要組成高可用性叢集,以便分散負擔、並相互備援,但這又會增加複雜性。
分散式的metadata架構,則是將metadata管理作業分散到所有儲存節點上執行,沒有單點故障困擾,但連帶也會增加各節點的負荷,且由於資料I/O與metadata查詢彼此混雜,也存在彼此干擾的問題。除此之外,由於metadata是由各個節點共同維護,因此也必須處理各節點間的同步與一致性問題,導致節點間面臨很大的metadata溝通流量。
新一代的平行檔案系統中,metadata管理是以分散式為主流,包括Weka、VAST Data、Quantum、Quobyte與Qumulo等。採用集中式metadata管理架構的平臺,只有Hammerspace與Pure Storage的FlashBlade//EXA。
用戶端存取架構
平行檔案系統實現用戶端平行存取的關鍵,是用戶端能發出跨多條I/O路徑的平行存取要求,常見的標準檔案存取協定如NFS、CIFS/SMB等,並不提供這樣的功能,所以,過去的平行檔案系統是透過專門的用戶端軟體,來提供這項能力,但用戶的應用程式也須配合這些非標準化的用戶端軟體調整,因而成為以往使用平行檔案系統的困擾之一。
而跟著NFS 4.1一起問世的平行(Parallel)NFS架構(pNFS),則為平行檔案系統的用戶端存取作業,提供可行的標準化架構,pNFS除了提供平行存取操作能力,也採用metadata與資料I/O分離的架構,metadata查詢是在用戶端與獨立的metadata伺服器之間進行,讀、寫等I/O存取操作則直接在用戶端與儲存節點間進行。
不過,在新一代平行檔案系統中,目前只有Hammerspace與Pure Storage的FlashBlade//EXA的用戶端存取,是基於pNFS協定,也對應這兩種平臺的集中式metadata管理架構。至於其餘大多數平臺(多為分散式metadata架構),仍是採用各自專屬的用戶端軟體。
專門的AI加速功能
針對當前最熱門的AI應用,當前的平行檔案系統也引進了專門的存取加速功能,最重要的是這兩項:GPUDirect Storage直連傳輸,以及用於大語言模型token的KV Cache快取記憶體功能。
Nvidia的GPUDirect Storage傳輸架構,目的是改善GPU伺服器與儲存設備間的傳輸效率,讓儲存設備與GPU直連傳輸資料,無須伺服器主機CPU的中介,從能顯著減少延遲與CPU負荷。目前新一代平行檔案系統多數都已支援GPUDirect Storage,包括VAST Data、Weka與Hammerspace,還有Quantum的Myriad。Qumulo雖然還未支援,但表示可以很快實現這一目標。唯一例外是Quobyte,該公司認為這項架構的影響不大,更重要的是RDMA傳輸架構。
今年3、4月間,幾家平行檔案系統廠商先後發表用於大語言模型token的快取加速功能。包括Weka的增強記憶體網格(Augmented Memory Grid)功能,以及VAST Data與中國炎融科技(YanRong)的KV Cache技術,基本概念是在平行檔案系統建置基於NVMe SSD的KV Cache快取區域,為前端GPU伺服器提供額外的KV Cache快取記憶體容量,存放更多數量大語言模型token,改善運作效能並節省GPU記憶體消耗。
VAST Data發展獨特的分解式叢集架構

大多數平行檔案系統都採用無共享叢集架構,每臺叢集節點都包含完整的控制器與儲存裝置,VAST Data則率先採用分解運算與儲存功能的「分解與共享一切」(DASE)架構,由專門提供資料服務與I/O處理的運算單元,以及專門提供儲存空間的NVMe儲存機箱,相互搭配成叢集。圖片來源/VAST Data
Hammerspace採用集中式metadata架構
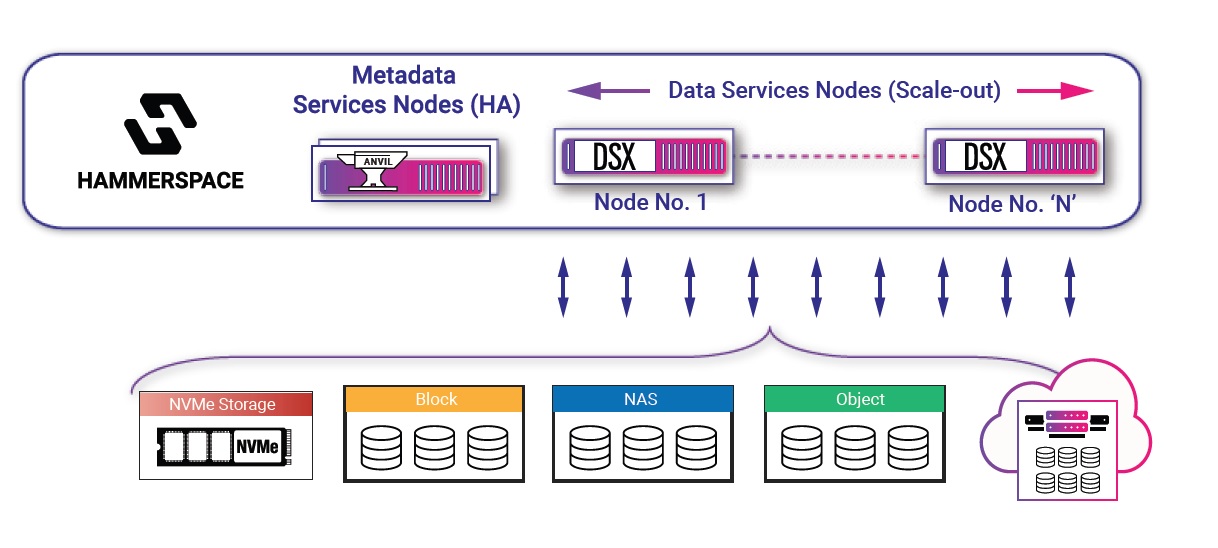
多數新一代平行檔案系統都採用分散式metadata架構,將Metadata管理分散到所有儲存節點上執行。Hammerspace與Pure Storage則是採用集中式metadata的少數派,由獨立的metadata服務節點來執行Metadata管理工作。圖片來源/Hammerspace

熱門新聞
")
2026-02-09
")

2026-02-06

2026-02-06

2026-02-06


2026-02-06

2026-02-06