這幾年以來,Nvidia資料中心GPU已成為許多雲端服務業者爭相建置的加速運算環境,隨著下一代GPU架構Blackwell去年3月浮出檯面之後,三大公有雲陸續揭露導入計畫。
例如,微軟去年11月宣布採用Nvidia GB200 Grace Blackwell Superchip,Azure ND GB200 V6系列虛擬機器發表預覽版本,今年3月正式推出;Google Cloud今年2月初宣布採用Nvidia HGX B200平臺,A4虛擬機器發表預覽版本,3月正式推出,並在2月下半宣布採用Nvidia GB200 NVL72平臺,A4X虛擬機器發表預覽版本,5月底正式推出。
至於AWS,前年底宣布與Nvidia合作設計的AI超級電腦Project Ceiba,原本打算採用Nvidia GH200 NVL32平臺,去年3月宣布改用Nvidia GB200 NVL72平臺,在此同時,也預告將推出基於Grace Blackwell平臺的Amazon EC2執行個體服務,以及DGX Cloud on AWS服務。

在2024年12月,Nvidia與AWS宣布將推出執行個體服務P6

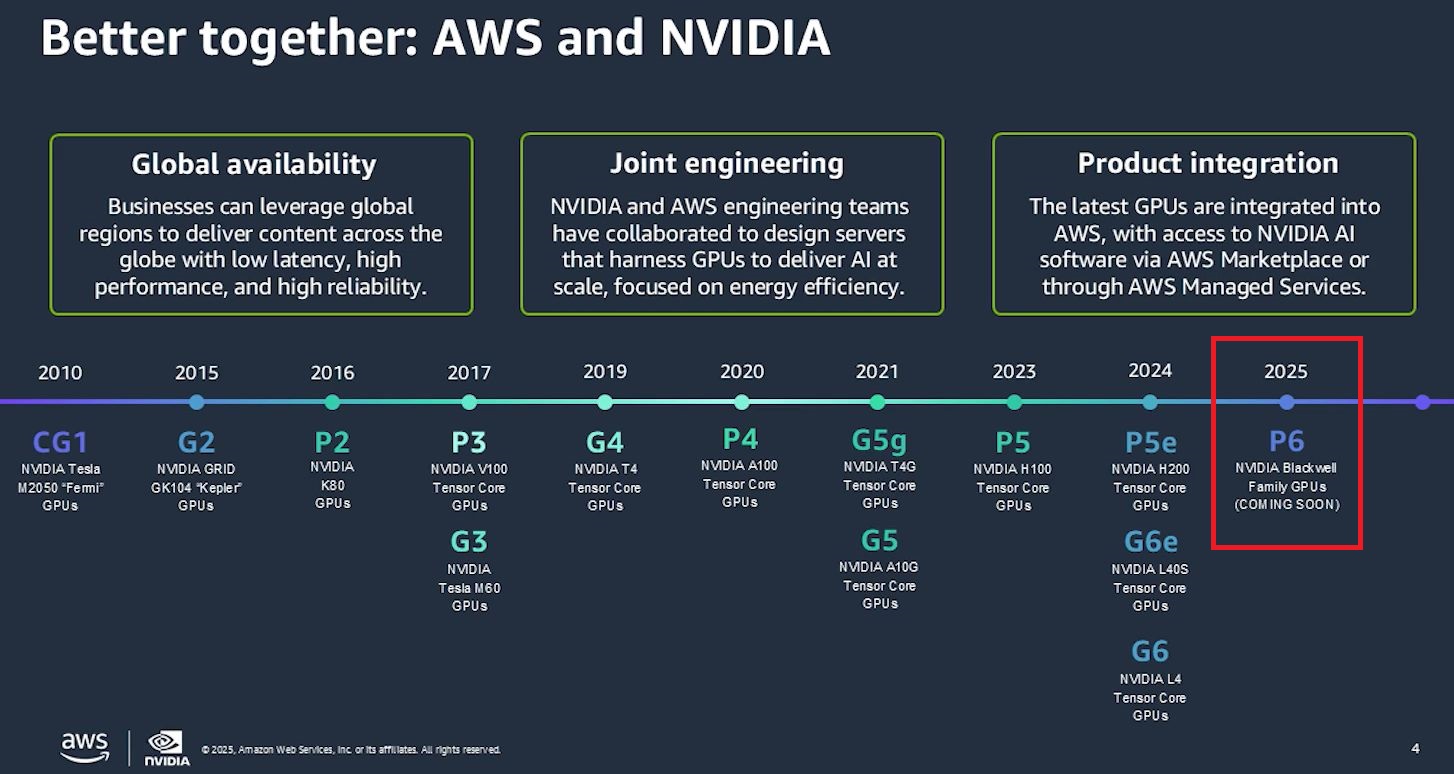

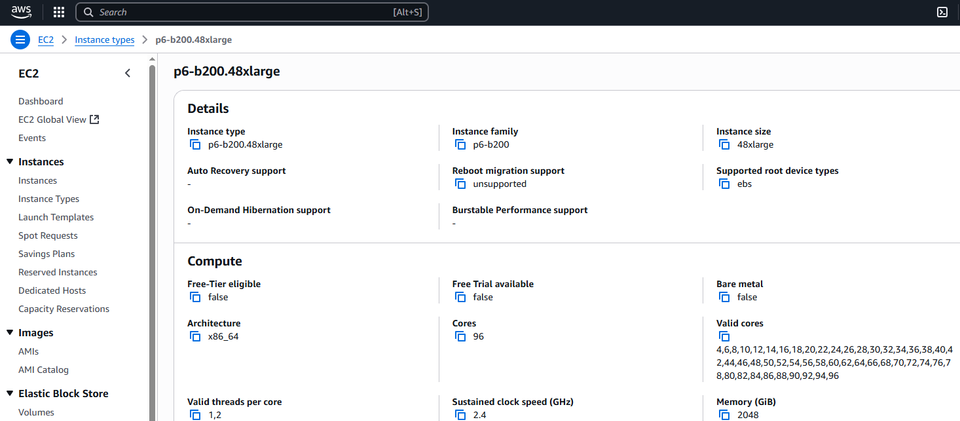
到了今年5月中,AWS宣布P6正式上線,而且,僅提供一種組態的雲端運算服務:P6-b200.48xlarge,每臺虛擬機器採用8個Nvidia B200 GPU,而且GPU之間彼此透過第五代NVLink與NVLink Switch相連,互連頻寬為1800 GB/s。
相較之下,AWS採用Nvidia H100 GPU的P5在2023年推出時,也是如此,起初僅有p5.48xlarge可用,在2024年下半,陸續增設改用Nvidia H200 GPU的P5e(p5en.48xlarge)、P5en(p5e.48xlarge)。
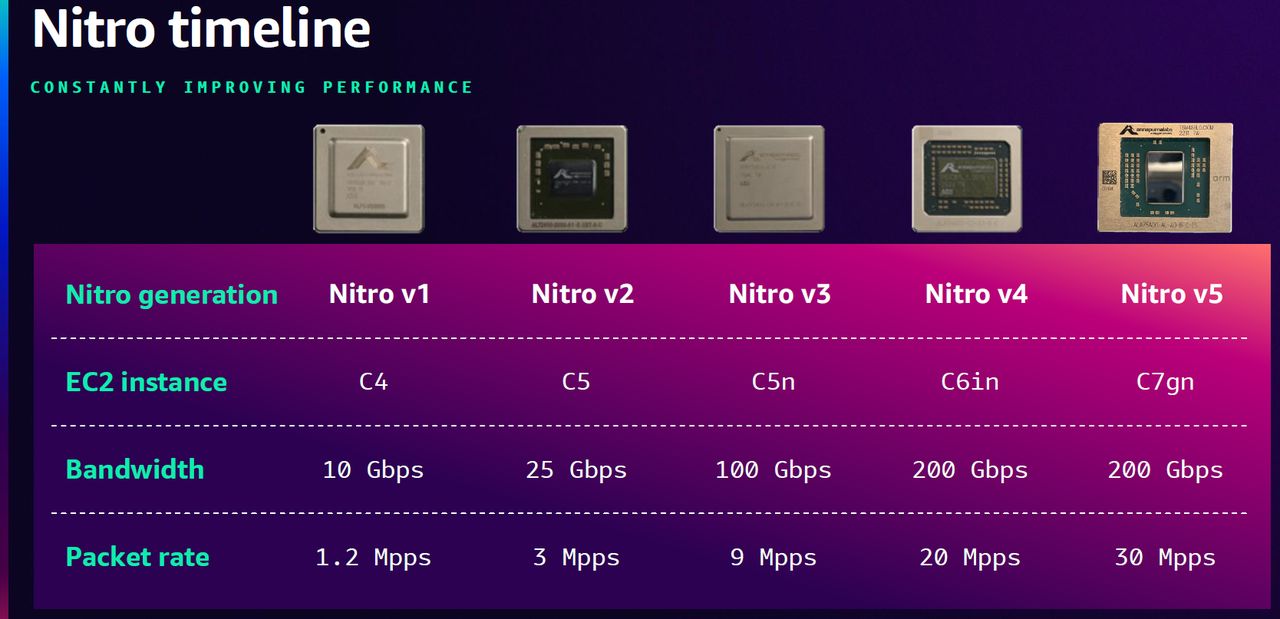
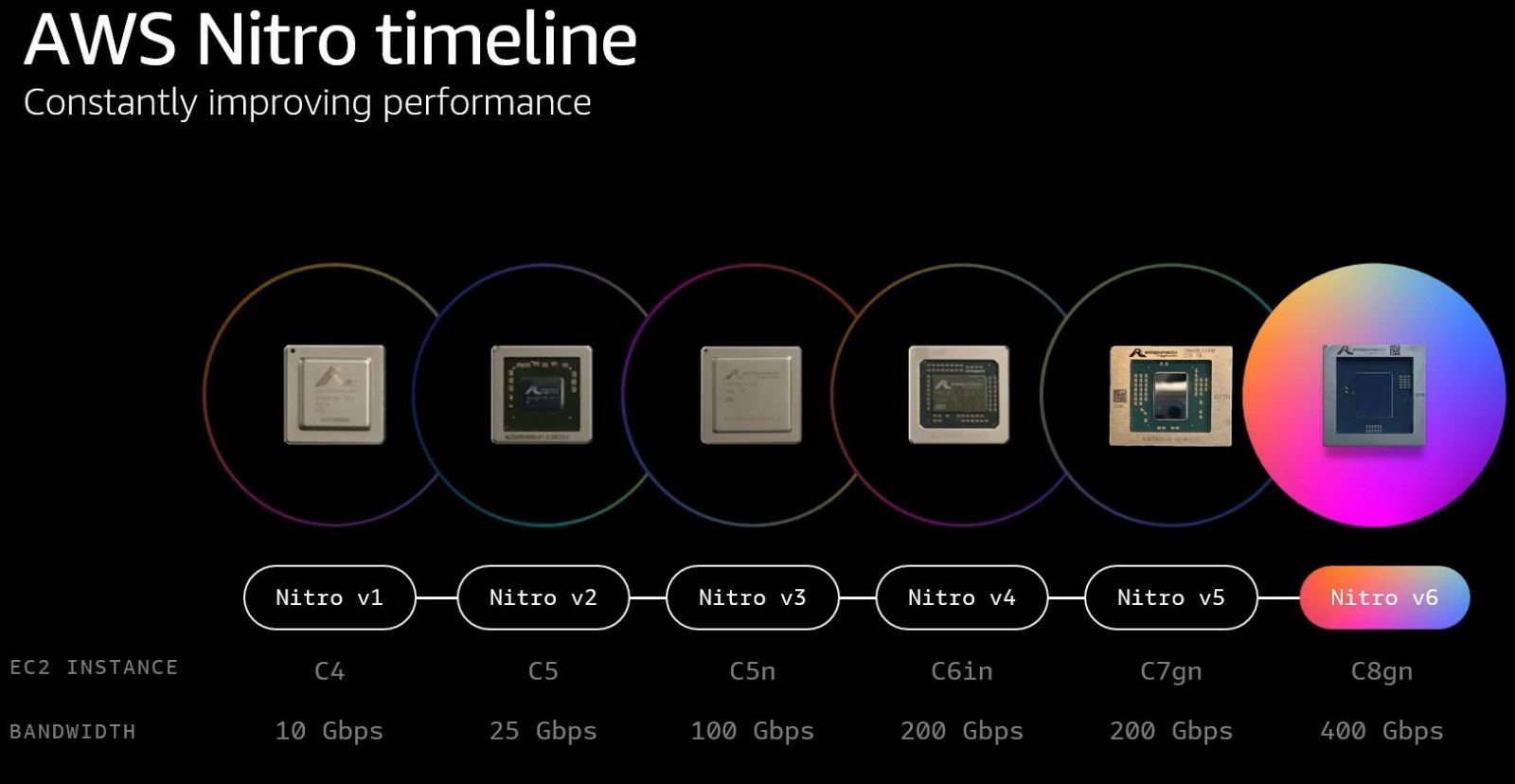
而且,P6建置在AWS雲端基礎架構,當中整合多種技術,像是提升虛擬化與安全防護的AWS Nitro System(P6-b200.48xlarge是第一款支援Nitro v6架構的執行個體,後續推出的C8gn也將支援Nitro v6);搭配8張支援400GbE網路規格的第四代Elastic Fabric Adapter(EFAv4),提供3.2 Tbps乙太網路。

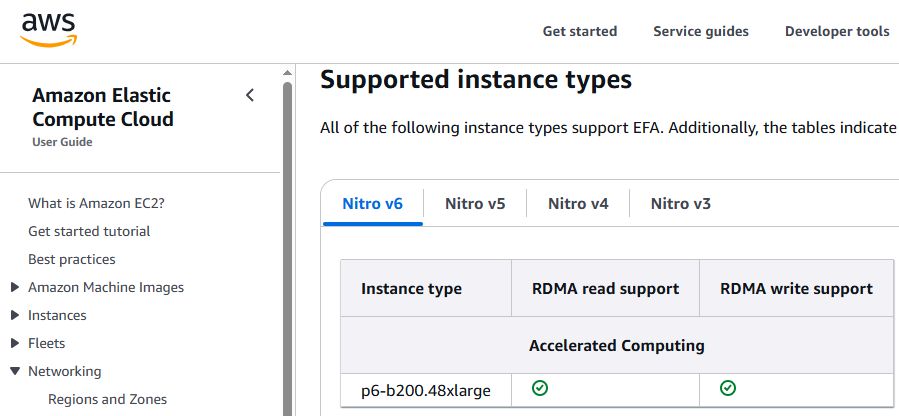
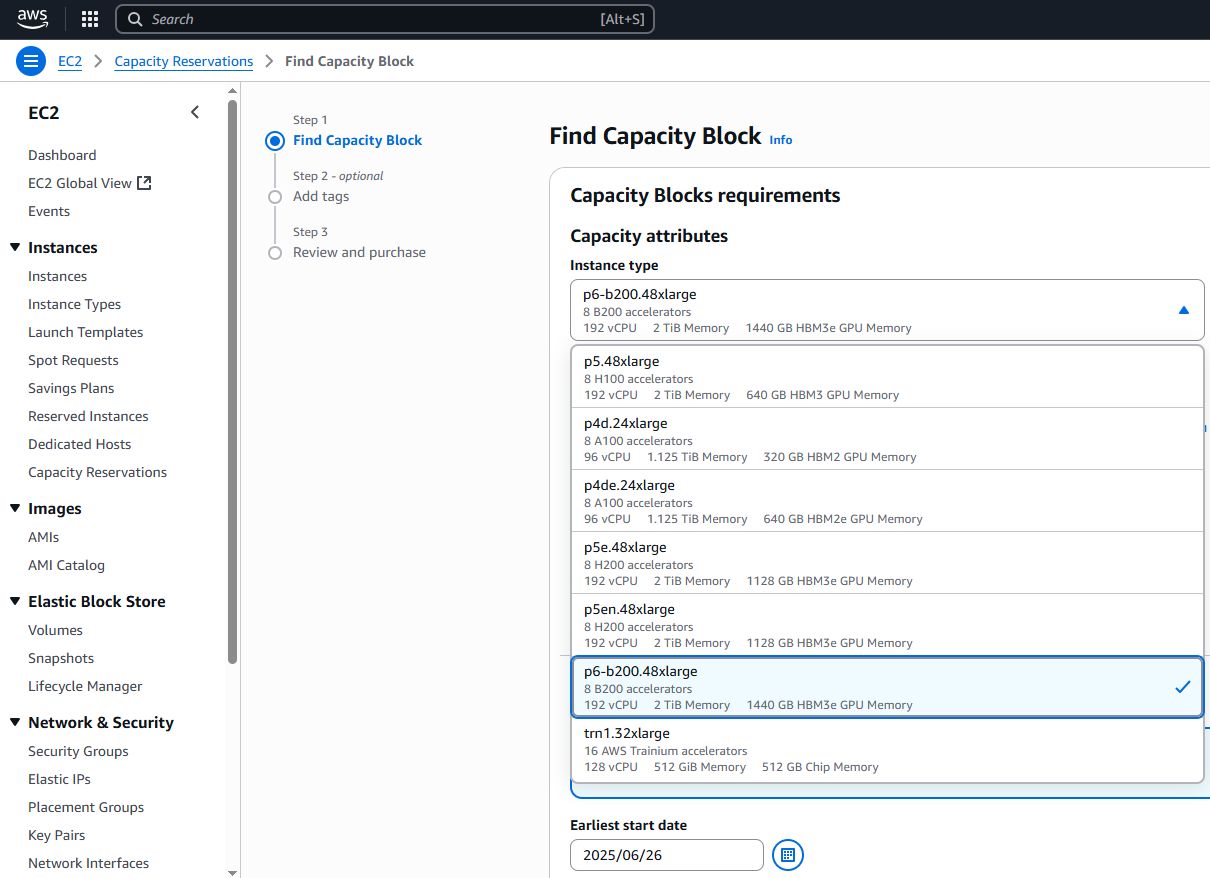
企業若要採用Amazon EC2 P6,可經由機器學習專用的EC2容量區塊(EC2 Capacity Blocks for ML)的服務模式,進行預租,截至目前為止,AWS在全球有兩個資料中心能申請使用P6-b200.48xlarge,一個是5月揭露的美國西部(奧勒岡)區域,另一個是美國東部(俄亥俄)區域,可從AWS網站的服務計價頁面、技術文件,以及用戶的AWS管理主控臺,看到這座資料中心也能租用P6。
關於使用成效,根據AWS在部落格的公告,就AI訓練所需時間與推論能力(每秒處理的Token數量)而言,以P5en為基準,P6可提供兩倍的效能。若比較兩個執行個體服務採用的GPU,以P5en搭配的H200為基準,P6搭配的B200,浮點運算領先幅度高達125%(80 TFLOPS vs. 60 TFLOPS),HBM3e記憶體容量增加27%(180 GB vs. 141 GB),HBM3e記憶體頻寬提升60%(8 TB/s vs. 4.8 TB/s)。
產品資訊
AWS Amazon EC2 P6
●原廠:AWS
●建議售價:美國西部(奧勒岡)區域,On-Demand方案每小時113.9328美元
●基礎運算規格:英特爾第五代Xeon Scalable處理器、2 TiB記憶體、30.72 TB NVMe儲存空間
●提供服務規模選擇與組態:
p6-b200.48xlarge,192顆虛擬處理器、2048 GiB記憶體、8臺3.84 TB本機儲存、8個Nvidia B200 GPU、網路頻寬為3,200 Gbps,網路儲存:使用AWS區塊儲存服務EBS,存取頻寬為100 Gbps
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23

2026-02-23