在2020年上半發表新一代GPU架構Ampere之後,Nvidia陸續推出採用這項技術平臺的產品,以資料中心等級GPU為例,有A100、A40,以及用於專業繪圖處理領域的RTX A6000,以及消費型獨立顯示卡GeForce RTX 3090/3080/3070。
到了2021年上半,他們於1月發表GeForce RTX 3060,到了4月舉行的GTC大會,又發表了更多Ampere架構的產品,例如,在桌上型電腦專業繪圖GPU,有RTX A5000 與RTX A4000;筆電專業繪圖GPU的部分,有RTX A5000、RTX A4000、RTX A3000、RTX A2000,我們在先前報導RTX A6000時,已約略介紹;而在資料中心等級GPU的產品線,則新推A30、A10、A16,則是我們本次報導的重點。
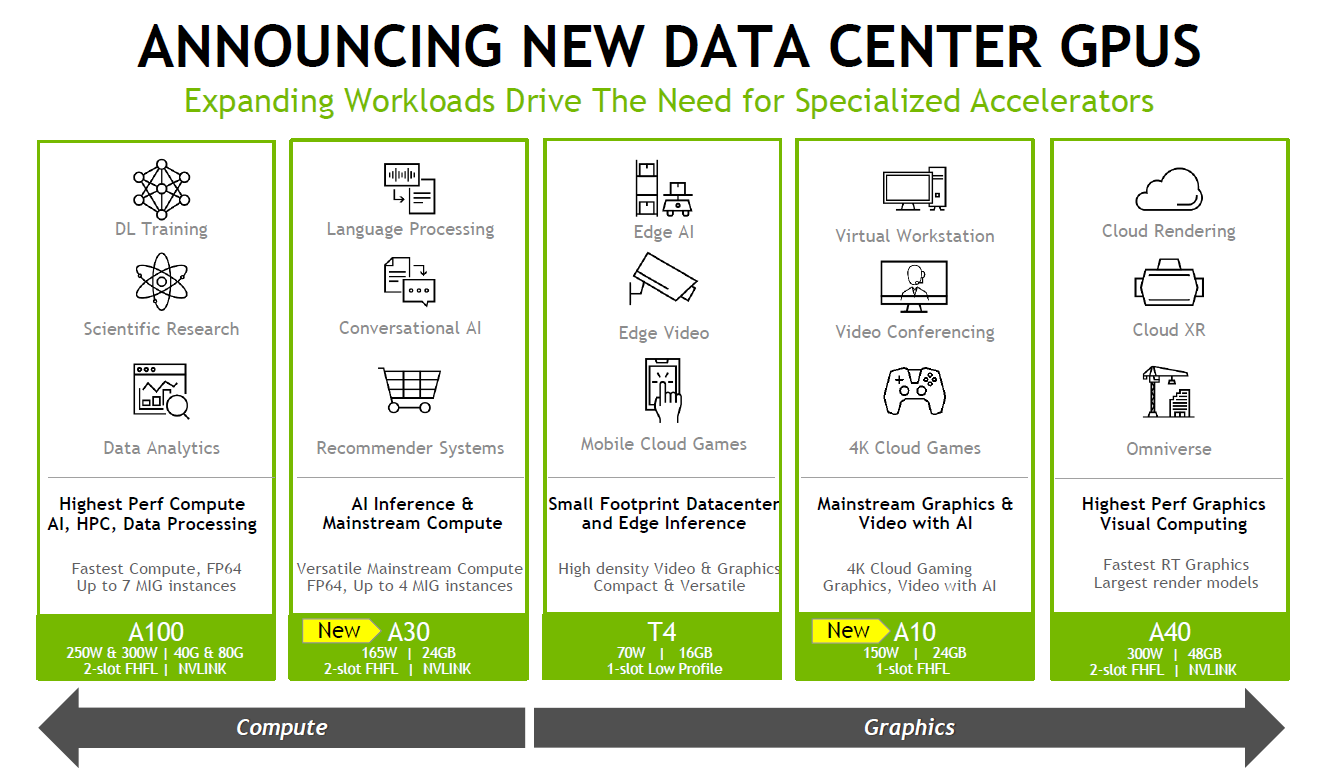


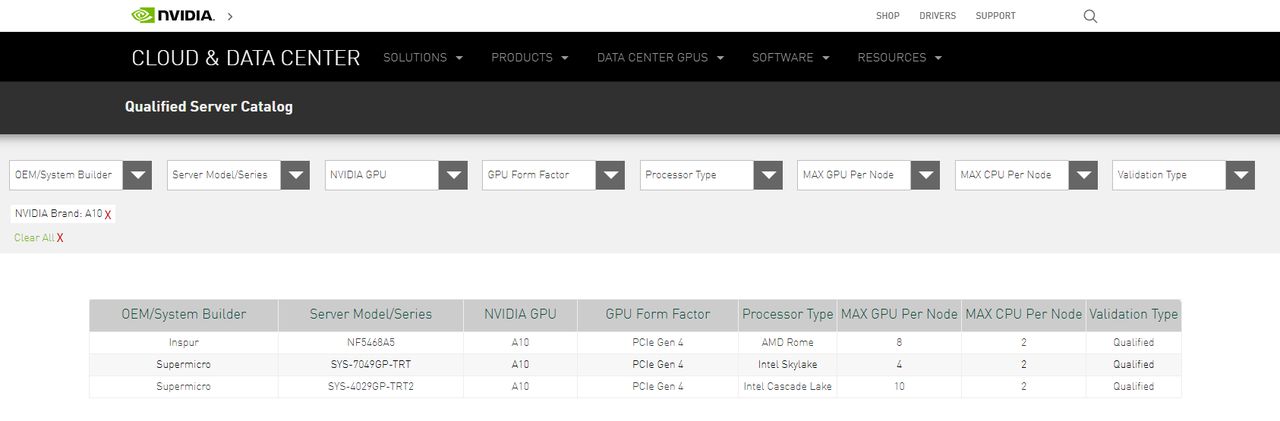
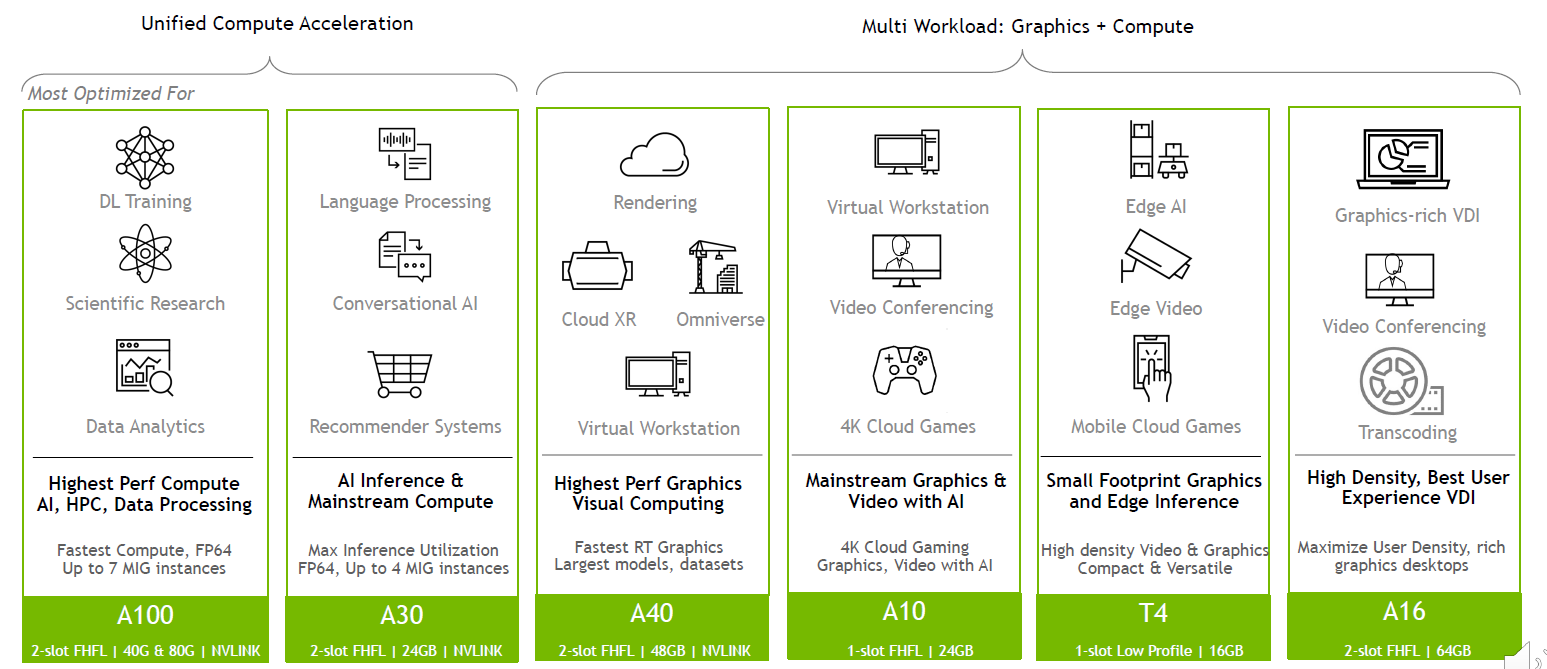
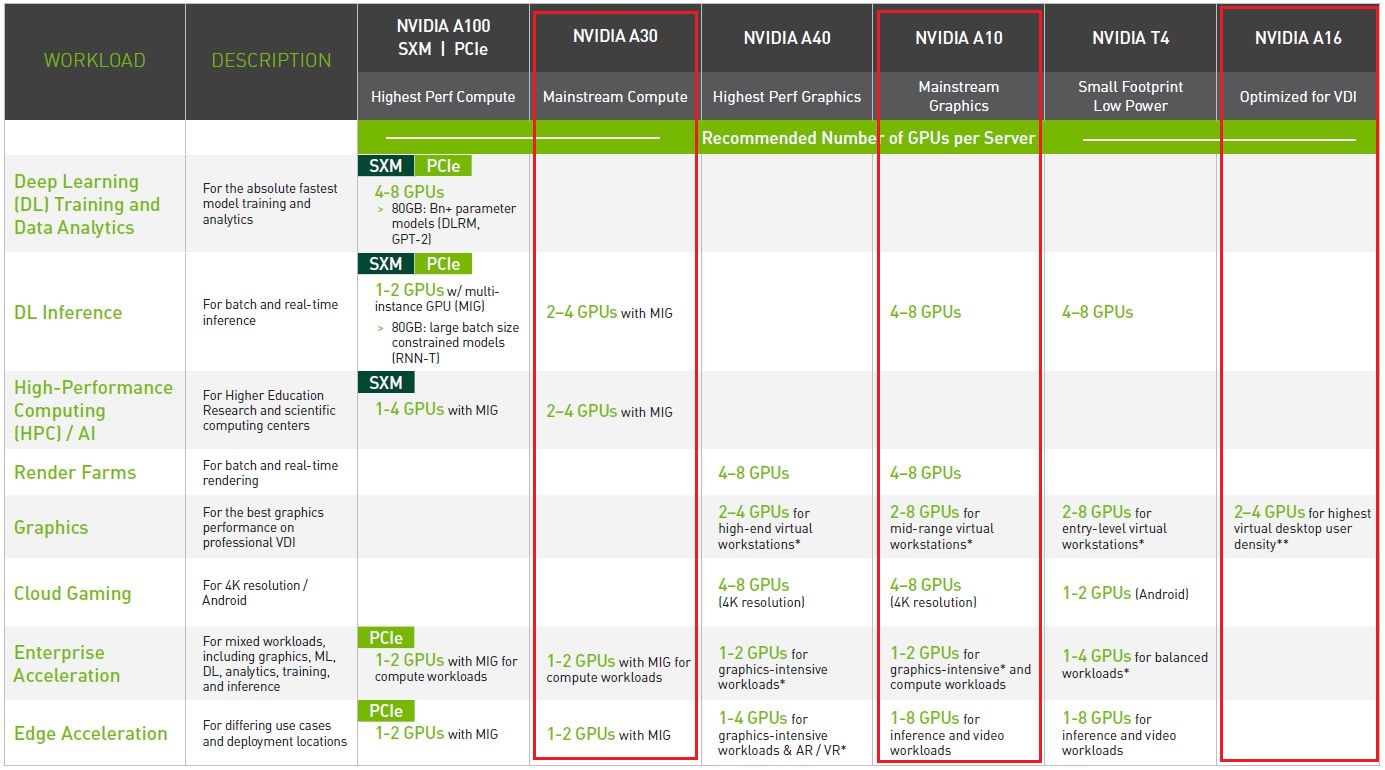
在產品定位上,A30可用於主流深度學習與資料分析,像是推薦系統、對話式 AI、電腦視覺;A10則適用於支援深度學習技術的繪圖處理、虛擬工作站,以及混合運算與繪圖處理的工作負載,目前Nvidia已公布這兩款機型的規格與產品型錄(datasheet),不過,在認證伺服器目錄當中,僅列出A10的配置,有3款伺服器通過Nvidia的驗證;
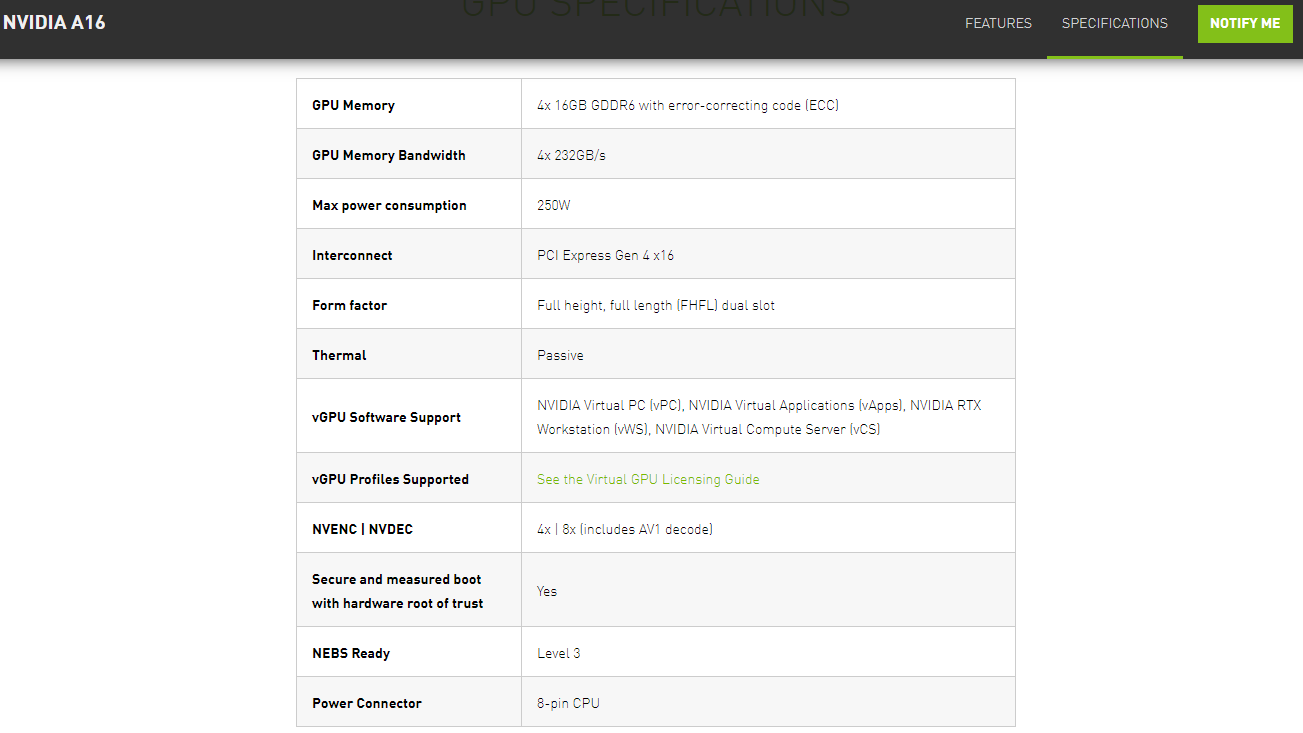
至於A16,專攻遠端工作者的應用場景,強化VDI、桌面虛擬化這類終端使用者運算的操作體驗,目前Nvidia已初步公布規格,預告將於今年稍晚推出。
就硬體規格而言,A30、A10、A16都是被動散熱(無風扇),採用PCIe 4.0的I/O介面(若需更高的效能,可透過NVLink Bridge連接兩張A30,即能取得330 TFLOPs的深度學習效能),
並且同樣配備了容量為24GB的記憶體,但差別在於前者採用HBM2,記憶體頻寬為933 GB/s,後兩者則是GDDR6,記憶體頻寬為600 GB/s、232GB/s。值得注意的是,A30配備第三代Tensor Core,而且也是A100以外、目前唯一支援多執行個體GPU(MIG)的產品,最多可切割成4個GPU,各自搭配6GB記憶體來使用;相較之下,A100最多可切割成7個GPU,各自搭配10GB記憶體。


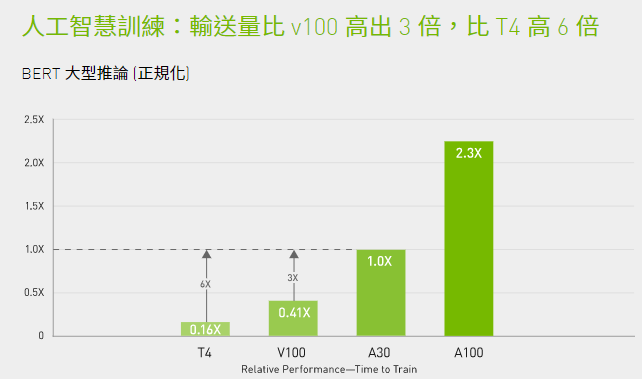
而在深度學習的訓練作業上,A30因為配備Ampere架構的Tensor Core,而支援Tensor Float-32(TF-32),運算能力大幅增長,若以既有採用Turing架構的T4為基準,可提供10倍的效能,若是再搭配自動混合精度與FP16的支援,甚至將吞吐量提升至20倍。
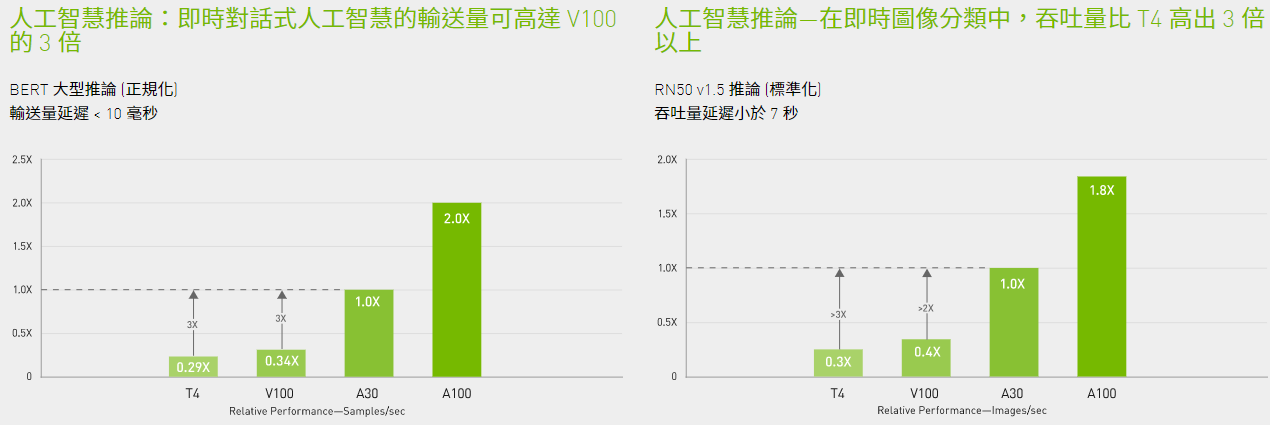
在推論處理上,A30可加速FP64、TF32、INT4等多種精度,還能支援MIG,切割成4個GPU執行個體,能讓多個類神經網路同時執行在不同的硬體分割區,而能互不影響,確保彼此的效能,再加上受益於Ampere架構支援結構化稀疏性處理(structural sparsity),使得A30可以獲得2倍的推論效能。在GPU虛擬化的應用類型上,A30可支援Nvidia vCS,以及VMware與Nvidia合作發展的AI Enterprise軟體套餐。
至於A10,主要用於繪圖、渲染、機器學習,以及運算負載的加速處理,它配備了24GB的GDDR6記憶體,內建第二代RT Core,以及第三代Tensor Core,可支援多種Nvidia發展的GPU虛擬化應用,像是vPC/vApps、RTX vWS,以及vCS。

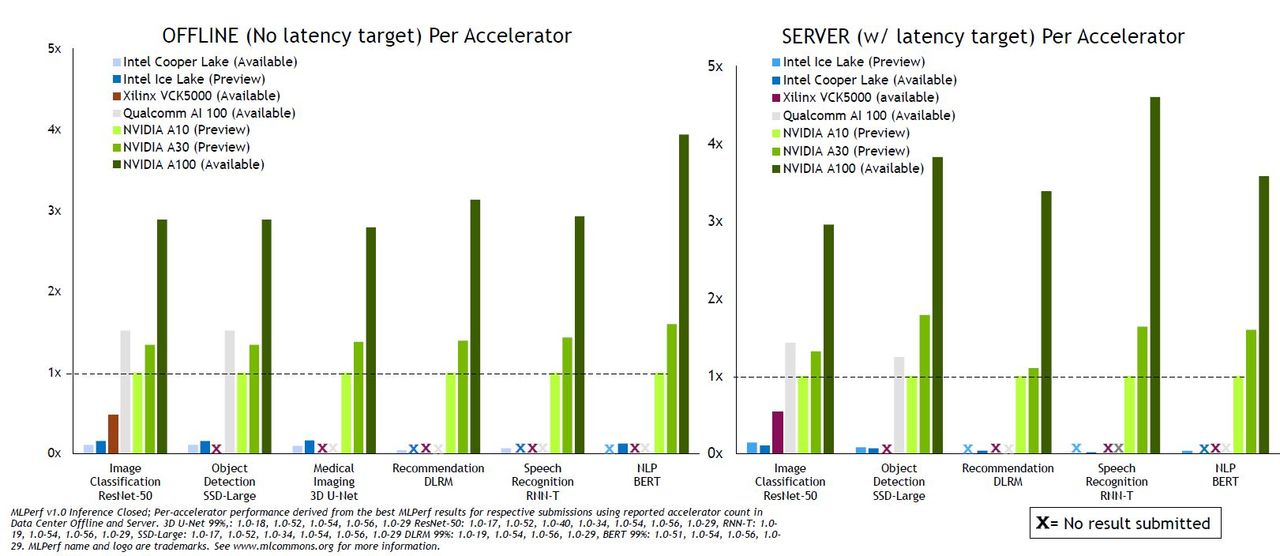
關於A30與A10的AI效能,這幾年崛起的定期評測各家運算平臺組織MLPerf/ MLCommons,在4月公布1.0的測試結果,當中也出現A100、A30、A10的測試結果。
而關於這幾款新推出的資料中心GPU效能,Nvidia也整理成比較圖表,突顯產品的優勢。

A16可用於新一代的VDI環境,可提供強大的效能,例如,單張介面卡支援的同時上線使用者,達到64人的規模(前代產品M10是32人),在編碼器(encoder)的吞吐量,也是前代產品的2倍,可針對多人環境提供更理想的串流影音效能。

它搭配了Ampere架構的CUDA核心、第二代RT Core、第三代Tensor Core,搭配4個16GB的GDDR6記憶體,支援多種Nvidia GPU虛擬化軟體應用:虛擬個人電腦vPC、虛擬工作站RTX vWS、虛擬運算伺服器vCS。
產品資訊
Nvidia A30
●原廠:Nvidia
●建議售價:廠商未提供
●外型:雙寬全高全長介面卡(PCIe 4.0)
●GPU架構:Ampere
●GPU記憶體:24 GB HBM2
●記憶體頻寬:933 GB/s
●熱設計功耗:165瓦
●GPU互連介面頻寬:112.5 GB/s
●多執行個體GPU切割數量:4個(每個GPU為6GB記憶體)、2個(每個GPU為12GB記憶體)、1個(每個GPU為24GB記憶體)
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-23

2026-02-20

2026-02-23

2026-02-23
2026-02-20