
針對高效能運算(HPC)的伺服器GPU應用需求,今年11月,趁著美國超級電腦大會SC舉行的期間,AMD發表了新的GPU加速器Instinct MI100,搭配ROCm 4.0。這套產品採用了AMD最新發展的GPU架構CDNA(Compute DNA for the Data Center),當中搭配了全新的Matrix Core引擎,而能更有效率地處理矩陣型態的資料,提高運算吞吐能力與用電效率。



AMD主打運算效能大幅突破的特色,與競爭廠商今年推出的新款資料中心GPU一較高下
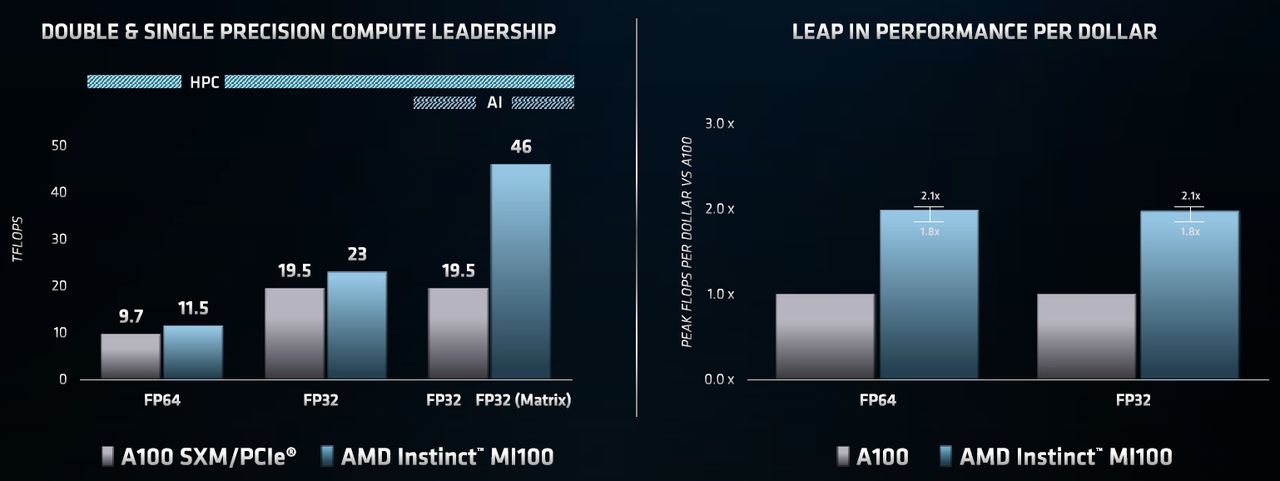
就高效能運算的應用而言,採用CDNA架構的AMD Instinct MI100,在FP64、雙精度運算的效能表現上,最高可達到11.5 TFLOPS;相較之下,市面上另一款資料中心GPU產品Nvidia A100,可達到9.7 TFLOPS,若啟用Tensor Core,可達到19.5 TFLOPS。而在FP32、單精度的運算上,AMD Instinct MI100可達到23.1 TFLOPS,Nvidia A100則是19.5 TFLOPS,不過,若是搭配Nvidia在這套產品新支援的Tensor Float 32(TF32),可達到156 TFLOPS。

針對人工智慧與機器學習的工作負載,Instinct MI100在FP32矩陣運算、單精度的效能上,可達到46.1 TFLOPS;而Nvidia A100在FP32單精度運算的效能,則是19.5 TFLOPS。
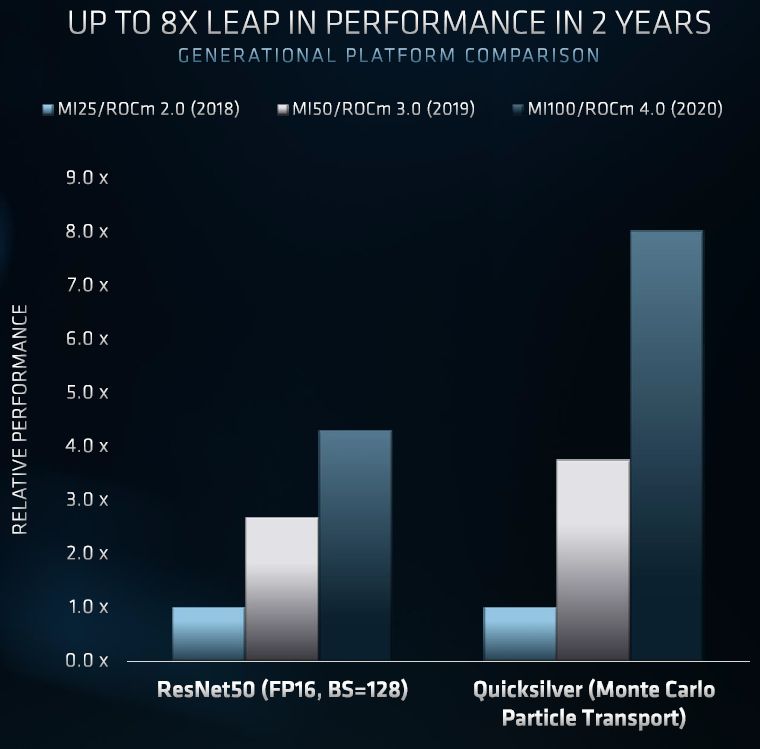
而在人工智慧訓練的工作負載而言,AMD Instinct MI100在FP16、半精度運算效能是184.57 TFLOPS,若以先前發表的Radeon Instinct MI50為基準(26.5 TFLOPS),可提升到將近7倍。
值得注意的是,這款GPU架構搭配的Matrix Core引擎,可廣泛用於單精度與混合精度的處理,像是FP32、FP16、BF16、INT8、INT4,對於融合高效能運算與人工智慧的工作負載,可大幅提升效能。
在I/O處理的部份,Instinct MI100本身使用了PCIe 4.0的介面,能在伺服器端CPU到這張GPU之間,提供64GB/s的資料存取頻寬,在此同時,它也採用第二代AMD Infinity Fabric技術,可支援多GPU的伺服器應用。若以搭配4張GPU的單一運算節點而言,這些GPU之間的I/O頻寬最高可達到552 GB/s。

事實上,每張Instinct MI100有3個頻寬為92GB/s的I/O連接,因此,整體而言,是提供276 GB/s的頻寬,若是集合4張GPU為1組的配置,GPU對GPU之間的頻寬是552 GB/s,若是伺服器搭配了2組各自內含4張GPU的配置,GPU對GPU之間的頻寬可達到1.1 TB/s。
如果未啟用AMD Infinity Fabric技術、僅依賴PCIe 4.0介面,採用了集合4張GPU為1組的配置,GPU對GPU之間的頻寬可達到256 GB/s。


在GPU記憶體規格的部分,Instinct MI100搭配的類型是高頻寬記憶體HBM2,容量為32GB,可支援1.2GHz的運作時脈,提供1228.8 GB/s的記憶體存取頻寬,能因應大型資料集的處理需求,以及大量資料搬移時面臨的I/O瓶頸。
發表新一代資料中心GPU加速硬體的同時,AMD發展的開放異質運算軟體平臺Radeon Open Compute Platform(ROCm),也趁機推出了4.0版,可針對搭配Instinct MI100的伺服器系統,提供最佳化的運作效能,以及擴展性。(10月推出3.9.0版,4.0目前尚未正式發布)
ROCm原本就是結合多種開放原始碼軟體的工具集,當中包含了編譯器、可程式化API介面、程式庫,過去在程式模型的部分,可支援OpenCL與OpenMP(Open Multi-Processing),而在4.0版裡面,AMD將編譯器予以升級、開放程式原始碼,並將其統合而能同時支援OpenMP 5.0,以及HIP(Heterogeneous-Computing Interface for Portability)等兩種(Programming Models)。
除此之外,PyTorch與Tensorflow這兩套深度學習的軟體框架,也針對ROCm 4.0的搭配提供更完善的支援,進而使AMD Instinct MI100發揮更高的效能。整體而言,ROCm 4.0如今可同時涵蓋到高效能運算、機器學習、人工智慧的應用,協助程式開發人員設計出高效能且可移植到不同運算架構的軟體。
而在Instinct MI100與ROCm 4.0實際使用的成效上,AMD也找來美國橡樹嶺國家實驗室為其背書,他們表示,相較於其他GPU,AMD Instinct MI100可帶來2至3倍的效能增長,而且,在他們早先發展混合CPU與GPU運算的系統時,也注意到AMD開放式軟體平臺ROCm,以及HIP相關的開發工具。

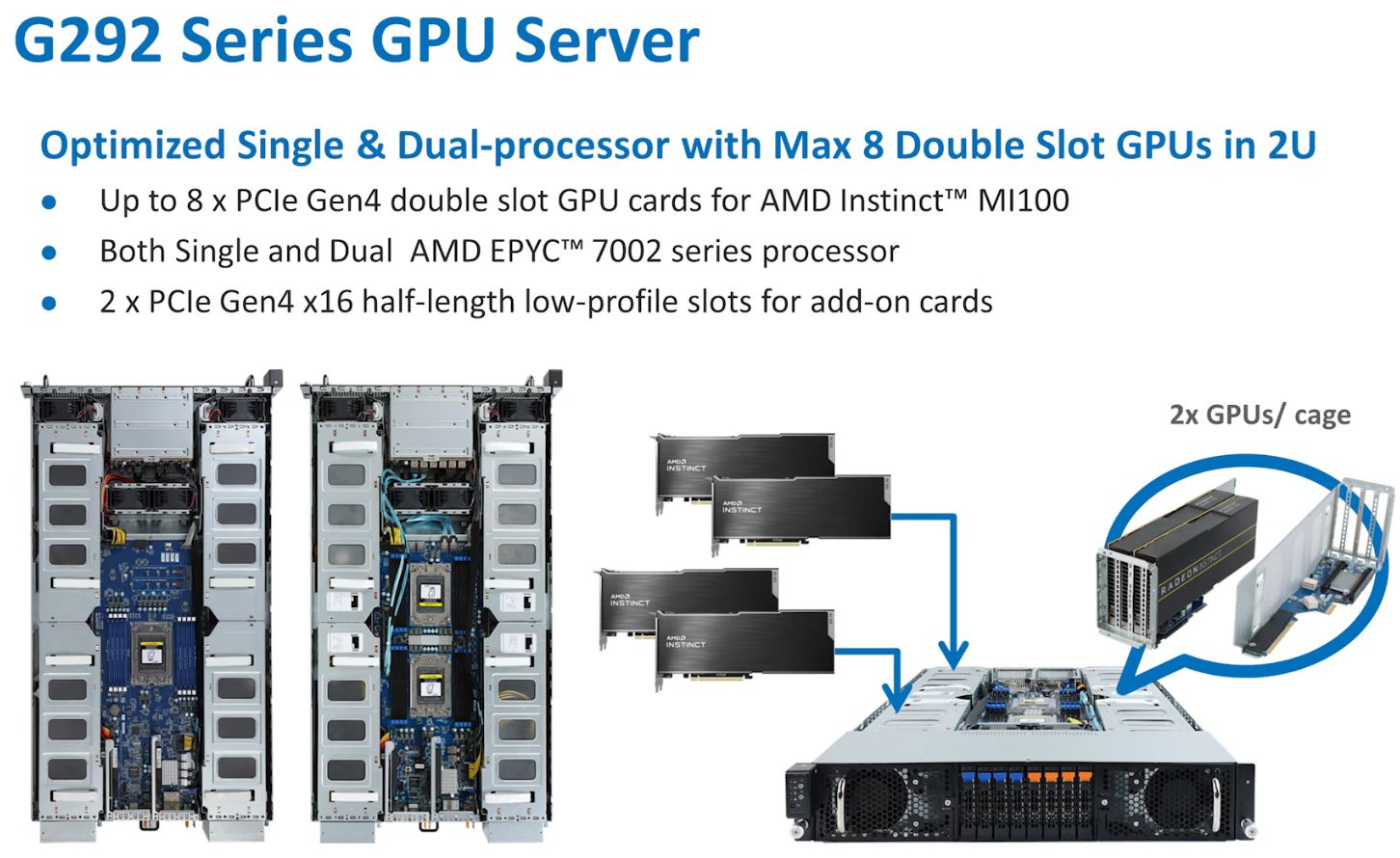
就產品供應的態勢而言,伺服器廠商是否願意搭配AMD Instinct MI100來販售,也將是這款資料中心GPU能否在企業環境普及的關鍵之一。AMD表示,目前將有4家廠商表態支援,分別是Dell、技嘉科技、HPE、Supermicro。

而在AMD提供給新聞媒體的簡報當中,他們已提及對應機型:以Dell而言,會是2U尺寸的Dell EMC PowerEdge R7525,HPE是6U尺寸的Apollo 6500 Gen10 Plus System,Supermicro是4U尺寸的4124GS-TNR,技嘉是4U尺寸的G482-Z53與G482-Z54。
不過,上述伺服器當中,只有技嘉發出新聞稿與公布這兩款伺服器的規格,並且特別提及對於AMD Instinct MI100的支援,其他廠牌在這些伺服器機型目前公布的規格當中,並未著墨。
對此,我們也向技嘉科技詢問此事,他們表示,技嘉GPU伺服器經過測試,都可支援AMD Instinct MI100,不過,G482-Z53與G482-Z54有特別設計,完全支援AMD Infinity Fabric,可提升CPU-CPU及GPU-GPU互連性能。

在技嘉的新聞稿當中,也提到G482-Z53可安裝AMD Instinct MI100,G482-Z54可額外安裝AMD Instinct MI100、網路卡、2.5吋U.2硬碟槽,後續我們也向他們詢問是否能多裝一張AMD Instinct MI100,他們表示,G482-Z54額外提供一條PCIe 4.0 x16插槽,可安裝全長全高規格的PCIe介面卡,但基於散熱考量,不建議多安裝一張GPU。


不過,AMD在他們的YouTube頻道當中發布了兩支影片,也揭露技嘉與HPE搭配AMD Instinct MI100的伺服器產品機型。



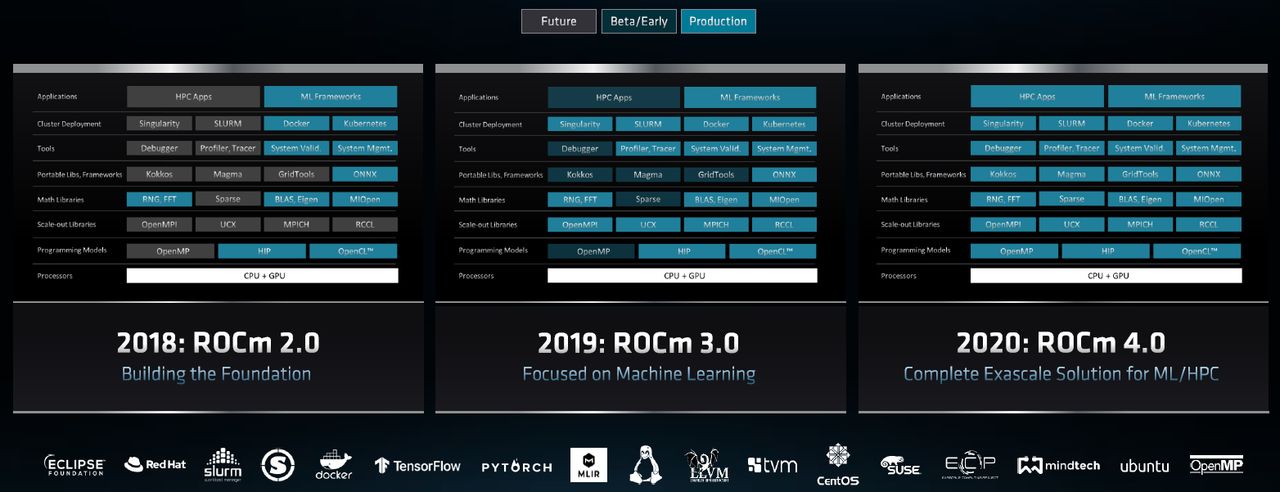
歷經多年發展,AMD伺服級GPU硬體產品線與異質運算軟體平臺,逐漸浮上檯面
Instinct MI100的推出,重振了AMD的伺服器GPU發展,重新取得了與其他廠商一較高下的態勢,但回顧過去,AMD這條路走得相當艱辛。
AMD在2014年到2016年所提供的這類產品,主要是FirePro S系列,而為了因應GPU硬體虛擬化的使用方式,他們在2015年8月推出Multiuser GPU(MxGPU)解決方案,隔年2月發表FirePro S7150與FirePro S7150 x2,當中就搭配了MxGPU技術。
不過,到了2016年12月,AMD發表Radeon Instinct系列的GPU加速卡,總共有MI6、MI8、MI25等3款,採用的GPU架構分別為Polaris、Fiji、Vega,可用於深度學習推論與訓練的場景,在此同時,他們也推出開放原始碼的GPU加速程式庫MIOpen,而這套軟體環境是架構在AMD於2014年推出的開放運算平臺,也就是Radeon Open Compute Platform(ROCm),而此時ROCm 1.3版規格也順勢發布。自此之後,FirePro S系列逐漸走入歷史,Radeon Instinct系列取而代之。
到了2018年11月的SC大會前夕,AMD揭露即將發表的第二代EPYC伺服器等級處理器,也發表了兩款首度導入7奈米製程的資料中心GPU,也就是Radeon Instinct MI60與MI50,採用的GPU架構是Vega 20,加速運算軟體平臺ROCm也推出2.0版。



接著,則是2019年11月、同樣在SC大會期間,AMD發布ROCm 3.0,當中支援了基於LLVM的編譯器HIP-clang,可搭配hipify-clang改善從CUDA程式架構轉換過去的能力,以及提供同時適用於高效能運算與機器學習最佳化的程式庫;同時,ROCm會整合到相關軟體供應鏈的上游,像是TensorFlow與PyTorch這些機器學習的軟體框架當中,以便支援強化學習(Reinforcement Learning)、自動駕駛與影像偵測等應用。

針對高效能運算領域的加速處理需求,ROCm也擴充支援更多類型的程式處理與應用模式,像是OpenMP、NAMD(Nanoscale Molecular Dynamics,奈米分子動力學模擬應用軟體)。在系統與工作負載的部署上,ROCm支援新的工具,像是Kubenretes、Singularity,以及SLURM(Simple Linux Utility for Resource Management)、TAU。

到了今年11月,AMD同時推出資料中心GPU產品Instinct MI100,以及開放式運算平臺ROCm 4.0。

產品資訊
AMD Instinct MI100
●原廠:AMD
●建議售價:廠商未提供
●處理器製程:TSMC 7nm FinFET
●I/O介面:PCIe 4.0 x16
●GPU架構:AMD CDNA
●GPU核心:120個運算單元,7,680個串流處理器
●GPU記憶體:32GB HBM2
●記憶體頻寬:1228.8 GB/s
●運算效能:雙精度(FP64)尖峰值為11.5 TFLOPS
●支援運算API:OpenMP、OpenCL、HIP、AMD ROCm
●耗電量:300瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-25