
在2016年8月,處理器大廠英特爾併購AI技術新創公司Nervana Systems之後,各界都在關注後續將推出的AI運算晶片。2017年10月,英特爾宣布年底將會推出第一顆針對神經網路處理的矽晶片,稱為Intel Nervana Neural Network Processor(NNP),其研發代號為Lake Crest。當時他們也規畫多個世代Nervana NNP的發展流程,希望能針對AI模型的處理提供更高的效能,以及更強大的擴展性,預計在2020年將AI效能提升至現行產品的100倍。
這款晶片有哪些不凡之處?根據英特爾所言,NNP是該公司根據AI應用需求所全部重新設計的深度學習ASIC晶片,透過這套專門針對深度學習所建構的運算架構,它能支援所有深度學習指令集,具有各種需要的使用彈性,能讓核心硬體元件提供最大運算效率。



在2018年5月舉行的Intel AI DevCon大會上,英特爾宣布即將推出第一套商業化的NNP產品,稱為Nervana NNP-L1000(研發代號為Spring Crest),上市時間會是2019年,根據他們的預期,Nervana NNP-L1000比起第一代NNP(Lake Crest),能提供3到4倍的機器學習訓練效能。

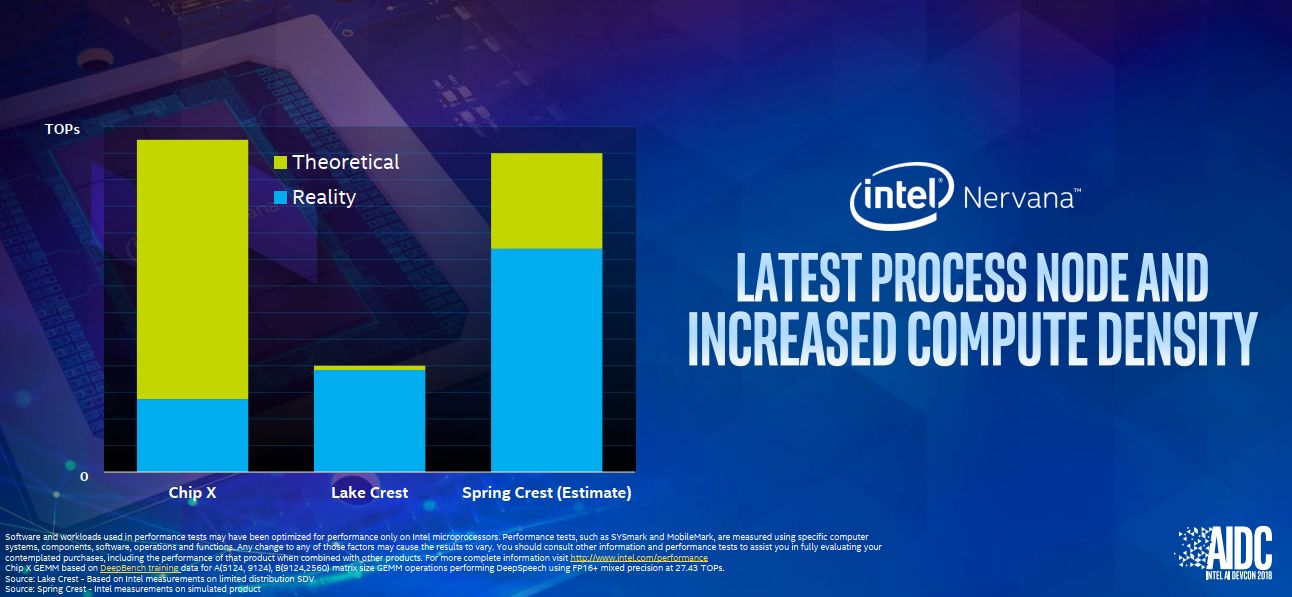
到了今年1月,英特爾在美國消費電子展(CES)期間,宣布推出另一顆用於AI推論處理的NNP晶片,稱為Nervana Neural Network Processor for Inference(NNP-I),在這套產品的研發上,英特爾也和Facebook合作。

3月召開的OCP Global Summit大會上,我們也看到英特爾透露NNP的近況,預告今年將會推出分別用於訓練與推論的產品,並提及NNP-L1000將推出遵循OAM(OCP Accelerator Module)外形設計的規格,採用夾層模組(Mezzanine Module)的型態。



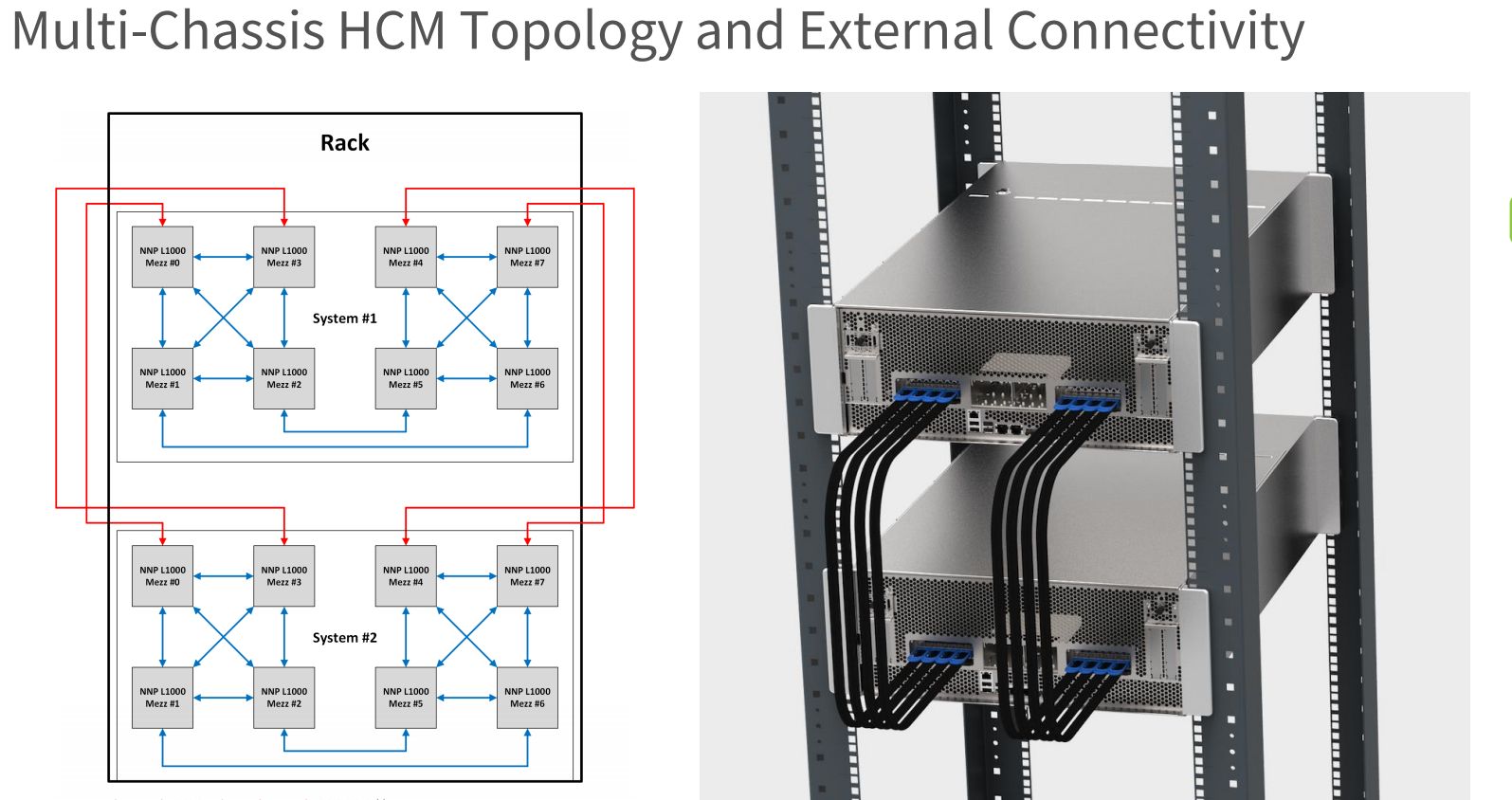
同時,他們也在OCP大會上,介紹了NNP-L1000用於單機箱、多機箱,以及多機箱多機櫃的高可用性機箱管理架構(HCM)。
下一個相關的消息是在7月揭曉,他們在中國北京舉行的百度AI開發者大會期間,宣布與百度公司合作研發用於AI訓練的NNP晶片,稱為Neural Network Processor for Training(NNP-T)。

隔月舉行的Hot Chips 2019大會上,英特爾對於即將推出的NNP晶片揭露更多細節,他們明確列出Nervana神經網路處理器的兩條主要產品線:NNP-T和NNP-I,前者用於深度學習的模型訓練,後者則是用於資料中心工作負載的深度學習推論處理,裡面採用了英特爾的10奈米製程技術,以及Ice Lake微架構的運算核心。

而NNP-T和NNP-I相關產品正式亮相的時間,則是在11月12日於美國舊金山舉行的2019 Intel AI Summit大會,英特爾公開展示這兩款特製的ASIC晶片,機型名稱分別為NNP-T1000與NNP-I1000,而且,他們宣布Facebook和百度均已採用這兩款產品。



以NNP-T而言,最多可內建24個張量處理叢集(Tensor Processing Clusters,TPC),以便執行深度學習訓練的作業。每個TPC會運用一種特別的計數格式,當中會結合16位元腦浮點(bfloat16)與32位元浮點(FP32)。而這種基於張量的bfloat16架構,可以支援多種深度學習指令,以便更有效率地運用硬體元件。
同時,每個NNP-T處理器,還擁有16個雙向高速的晶片對晶片連結通道(Inter-Chip Links,ICLs),能在安裝多張運算加速卡時,不論是在單一系統、單一機櫃(跨多臺伺服器),或是跨多個機櫃組成單個Pod時,均可獲得近乎線性擴展的處理規模。


在架構上,用戶可以在單臺伺服器上,使用8張加速卡,支援多個深度學習訓練系統,建構一組AI訓練用的Pod。它能支援多種連接方式,環狀拓樸、混合式立方網狀網路拓樸(Hybrid Cube Mesh),以及完全連結,以便對應不同的資料吞吐量與延遲度要求。
根據英特爾的內部測試,在一座安裝32張NNP-T加速卡的機櫃當中,執行ResNet-50和BERT的深度學習訓練時,所獲得的規模擴展可達到95%(競爭廠商的產品只有73%,但英特爾並未寫明與何種產品相比)。此外,不論是使用8張加速卡或32張加速卡,資料傳輸率均可維持相同速度,不因搭配數量更多的加速卡而影響效能。
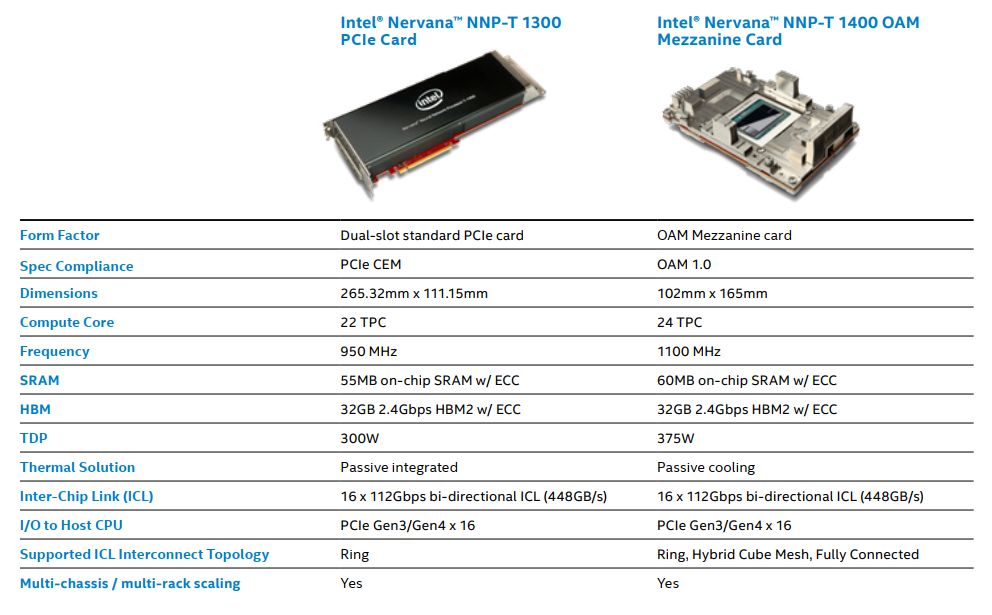
在產品形式上,NNP-T提供2種外形,分別是PCIe介面卡NNP-T 1300,以及OAM夾層卡NNP-T 1400,可安裝在伺服器當中,也能支援跨伺服器之間的運算流量處理,英特爾也提供跨機櫃的Pod參考設計,以支援雲端服務規模的應用需求,而這樣的作法,能讓用戶以晶片對晶片、機箱對機箱、機櫃對機櫃的串連方式,建置超大型深度學習訓練系統,而且當中不需要交換器來銜接。



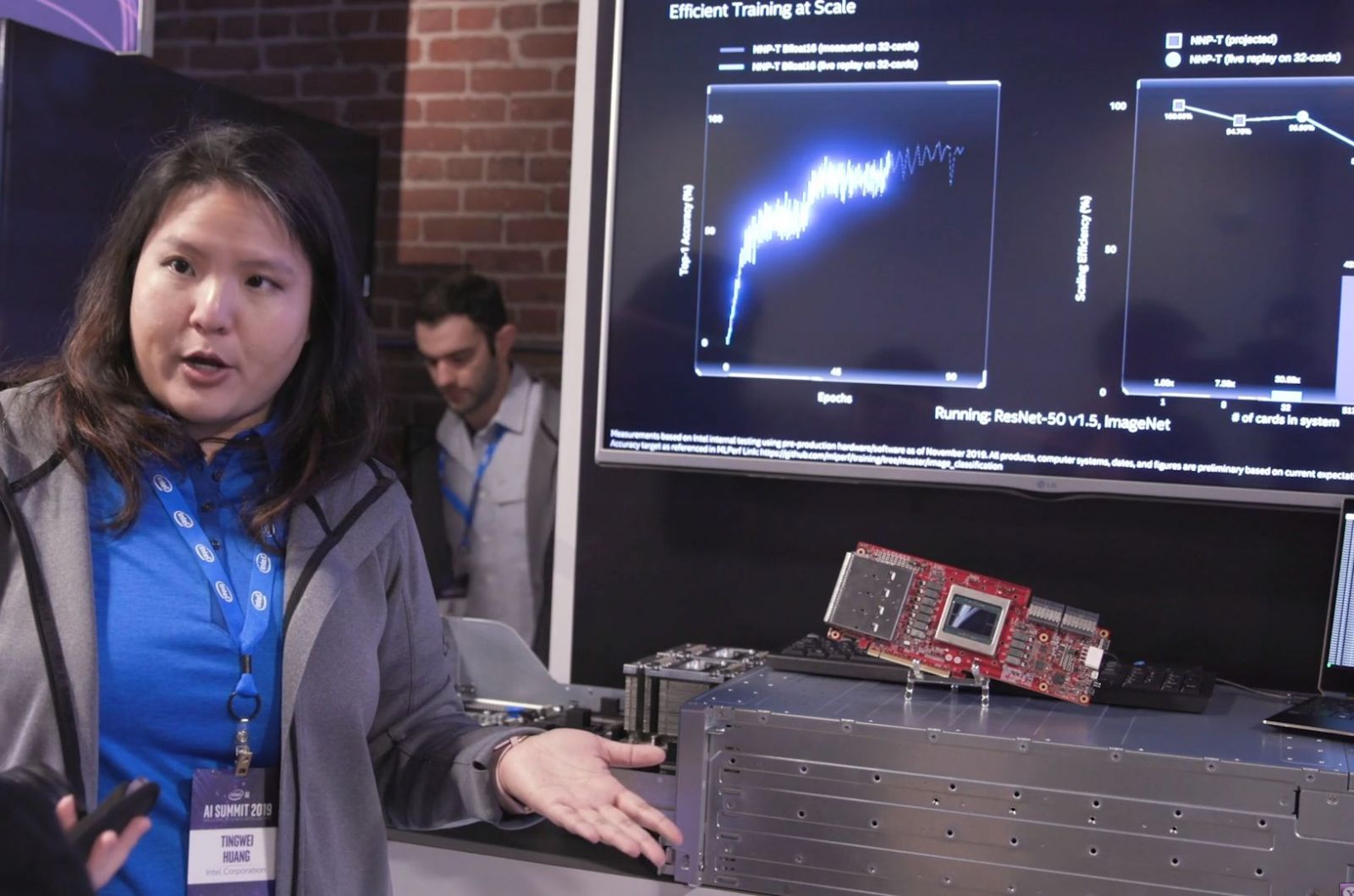


英特爾也在Intel AI Summit大會現場,實機展示以10座機櫃組合而成的伺服器系統。巧的是,Supermicro也在本週舉行的SC大會發布了新聞稿,裡面也秀出10櫃NNP-T Pod的產品照片,或許英特爾在自家活動當中所展示的設備,就是出自Supermicro之手。

另一款NNP-I,則是專為執行密集、多模態的推論處理所設計,具有高效能的運算效能、支援可程式化控制等特色,並且訴求具有較低耗電與建置成本。這裡面採用了完全整合電壓調節技術(FIVR),能讓系統單晶片(SoC)運用不同的功率包絡(power envelopes)實現動態電源管理,達到能源效率最佳化。

在這顆處理器的裸晶當中,也配置了英特爾架構的運算核心,包含AVX與VNNI指令集,能支援高階可程式化應用,讓從事AI工作的人員面對新一代的資料模型時,也能因為採用NNP-I而具有足夠的最佳化效能。
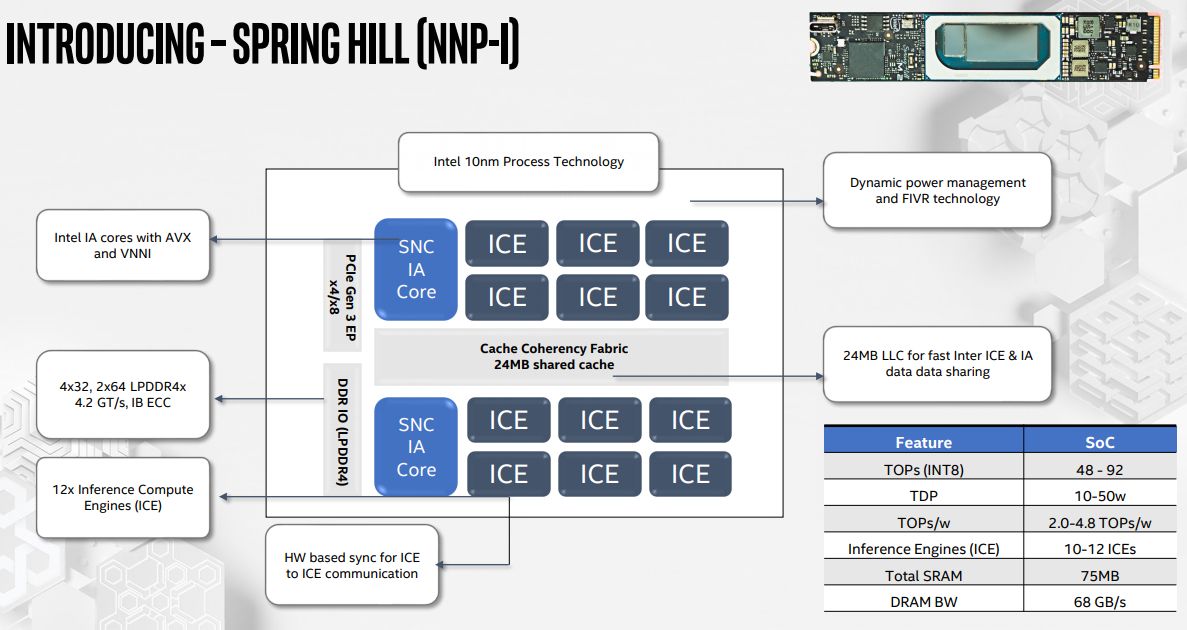
架構上,英特爾目前推出的NNP-I處理器是第一代產品,稱為NNP I-1000(代號為Spring Hill),裡面採用12個推論運算引擎(Inference Compute Engines,ICE),以及2顆英特爾CPU核心(IA Core),兼具可程式化能力與最佳化吞吐效能,具有支援不同計數方式的彈性,提供混合精度的計算力,可執行低精度的應用,達到近乎即時的運算效能,並能因應不同應用下的程式碼快速移植需求。
NNP-I的裸晶當中也配置了大量的SRAM記憶體,以及1顆同調(coherent)的網路單晶片(NoC)。基於這樣的設計而成的Cache Coherency Fabric,可善用多個記憶體階層架構,支援資料快速共享與重複使用,減少不必要的記憶體存取作業,而能提供低延遲的操作模式,如此一來,也促使NNP I-1000在執行深度學習推論處理時,具有更好的每瓦效能(根據英特爾在Hot Chips大會發布的資料來看,可達到每瓦4.8 TOPS)。
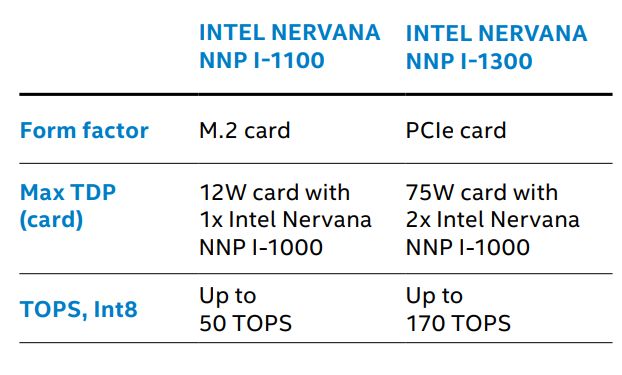
在產品的應用形式上,NNP-I可部署在資料中心或是網路邊際的位置,英特爾提供相當多種外形,以支援大規模的推論運算部署,目前有M.2、PCIe介面卡。不過,值得注意的是,英特爾也在Intel AI Summit大會主題演講的簡報,秀出有EDSFF的外形,而在大會現場,我們的記者翁芊儒則拍攝到M.2、E1.L、E1.S等3種外觀。



NNP I-1000的另一大賣點是其運算效能,英特爾也公布他們效能測試的比較結果,若以搭載Nvidia T4的伺服器(Supermicro 6049GP-TRT,4U機箱、安裝20張Nvidia T4)為基準,搭載32臺EDSFF形式的NNP I-1000的1U伺服器(英特爾並未公布設備廠牌與機型),可提供更高的運算密度(3.7倍)。

若要將NNP- I用於雲端原生的環境,英特爾表示,他們將提供一套完整的解決方案軟體堆疊架構,透過他們釋出的Kubernetes裝置外掛與管理介面,使其能夠支援Docker容器、Kubernetes調度指揮系統,以及無伺服器架構,能用於容器即服務(CaaS)與功能即服務(FaaS)的雲端服務模式。

若要將NNP- I用於雲端原生的環境,英特爾表示,他們將提供一套完整的解決方案軟體堆疊架構,透過他們釋出的Kubernetes裝置外掛與管理介面,使其能夠支援Docker容器、Kubernetes調度指揮系統,以及無伺服器架構,能用於容器即服務(CaaS)與功能即服務(FaaS)的雲端服務模式。
產品資訊
Intel Nervana NNP系列
●原廠:Intel(02)6622-0000
●建議售價:廠商未提供
●機型系列與用途:NNP-T系列用於深度學習訓練,NNP-I系列用於深度學習推論
●外形與細部機型:NNP-T 1300為雙槽PCIe介面卡,NNP-T 1400為OAM夾層卡,NNP I-1100為M.2模組,NNP I-1300為PCIe介面卡
●功耗:NNP-T 1300為300瓦,NNP-T 1400為375瓦,NNP I-1100為12瓦,NNP I-1300為75瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23
2026-02-20