
以GPU運算著稱的Nvidia,近年來大舉拓展伺服器與雲端環境的人工智慧解決方案。以深度學習應用方面為例,在2016年3月舉行的GTC大會期間,該公司推出2U尺寸的整合伺服器設備DGX-1,起先搭配的是8套SXM2形式的GPU運算模組Tesla P100。

到了隔年,因應Nvidia新發布的Volta架構,DGX-1開始搭配基於這項新架構而成的Tesla V100(內建16 GB HBM2記憶體)。同時,該公司還發表針對個人端的整合工作站設備,稱為DGX Station,當中採用的GPU模組是4套Tesla V100。
有了專業級與入門級的DGX系列產品之後,在2018年的GTC大會上,Nvidia再接再厲,推出了因應超大量運算分析需求的頂級產品,稱為DGX-2。




這款整合設備體型相當大,機箱為10U尺寸,搭配的GPU數量也更多,總共有16套Tesla V100,比DGX-1多出一倍,因此,在深度學習的分析應用上,可達到2 PFLOPS的規模(Tesla V100的Tensor效能是125 TFLOPS)。


而上述的運算效能,如果以現行的2U尺寸伺服器來提供,Nvidia認為,可能必須要建置到3百臺伺服器,佔用15座機櫃空間,才有可能達成。若以這樣環境作為基準,反觀10U尺寸的DGX-2,僅需60分之一的機房空間,用電效率提升的幅度則是18倍。

搭配記憶體容量更大的V100 GPU,整臺伺服器可處理更大規模的資料
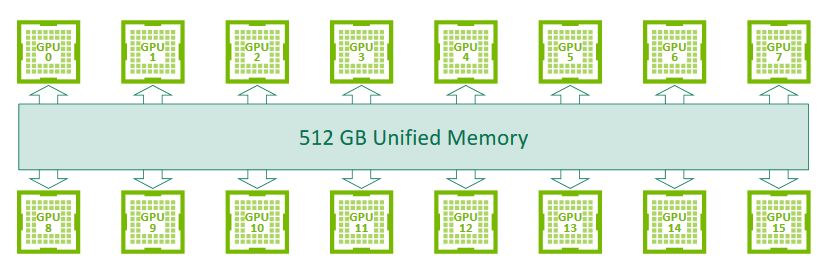
從運算規格來看,DGX-2採用的Tesla V100,是2018年Nvidia新增加的機型,內建HBM2記憶體容量為32 GB,比2017年推出的Tesla V100提高了1倍,所以,整臺伺服器能夠存取的GPU記憶體容量,也跟著水漲船高,來到512 GB之譜。





單就Tesla V100 32GB而言,若以Tesla V100 16GB為比較基準,用於記憶體資源受限既有伺服器配置的高效能運算應用時,Tesla V100 32GB可提升50%的效能。
若是相較於2017年推出的DGX-1搭配Tesla V100的組態,在進行FAIRSeq這套神經機器轉譯模型的訓練時,需15天之久,如果改用DGX-2,可提供10倍的效能,訓練時間縮短至1.5天。

搭配Nvidia獨創的NVSwitch技術,可強化單臺伺服器的多GPU互連效能
值得注意的是,DGX-2導入了更高階的GPU互連技術NVSwitch,提供的頻寬是現行PCIe交換器的5倍。它是基於NVLink所延伸出來的新應用,可彈性連接支援NVLink技術的GPU,建構出更有使用彈性的伺服器系統。

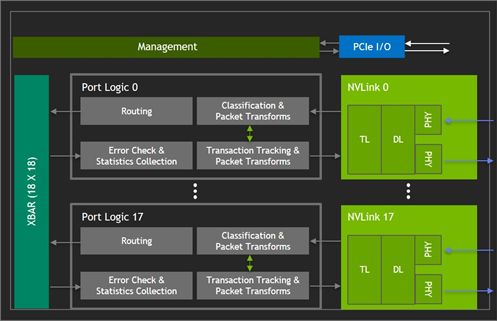
就NVSwitch本體而言,它是一顆NVLink交換器晶片,它採用台積電12 FFN製程,裡面包含了20億個電晶體,而且內建了18個NVLink埠(晶片裡面是18 x 18個連接埠,會由一條XBAR連接),而每埠最大可提供51.5 GB/s的傳輸速度,而匯聚雙向頻寬可達到928 GB/s。

![]()

事實上,過去Nvidia在單套GPU內部,以及2套GPU之間,就已經採用一條橫槓(Crossbar,XBAR)的管線來進行聯繫。以單GPU為例,可透過XBAR,在L2快取與HBM2記憶體,進行圖形處理叢集(GPC)與串流多處理器(SM)核心之間的資料交換。
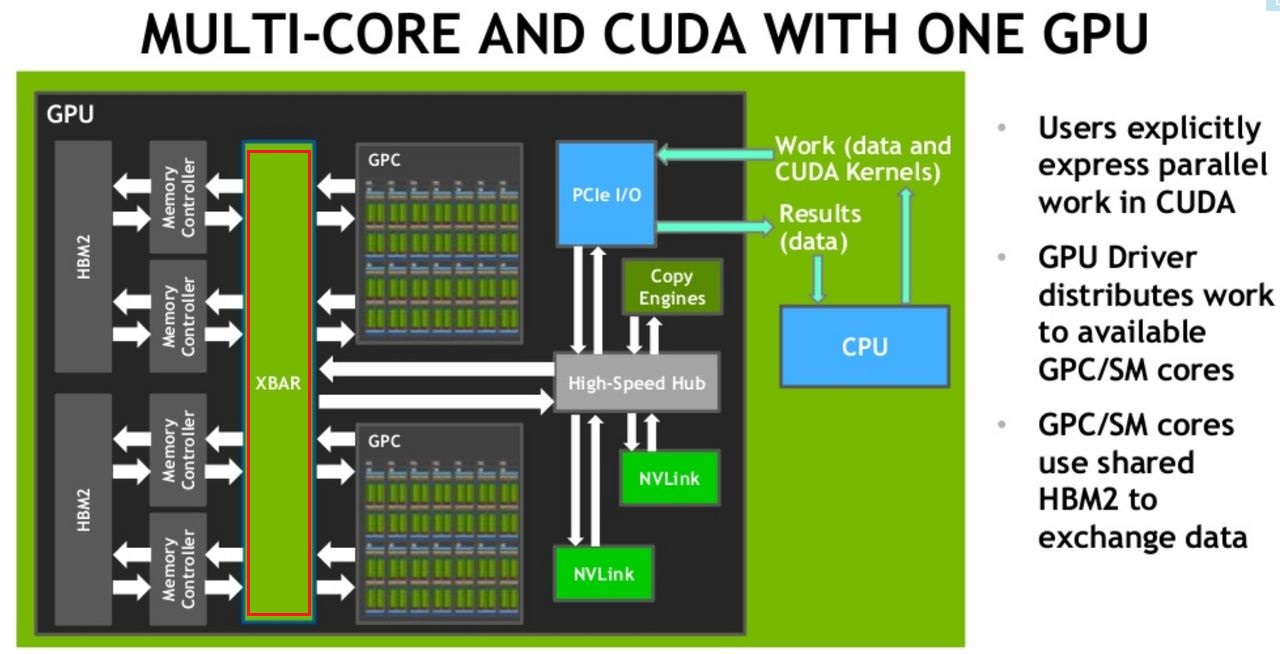
而在雙GPU連接時,它們能經由PCIe提供的32 GB/s頻寬來存取彼此的記憶體,但這樣會與伺服器匯流排的CPU處理競爭,而僅能使用有限的I/O頻寬。此時,有了NVLink技術,能夠讓GPC存取遠端的GPU記憶體,NVLink也可在多個XBAR之間進行橋接。

若使用V100 GPU,因為它可支援6個NVLink,因此GPU之間的頻寬可達到300 GB/s。然而,如果伺服器搭配的GPU超過2套,NVLink會被切分成多個小型群組式連結,這麼一來會局限可擴展的設備規模,而且可能要運用直連方式串接,而且,每一對GPU之間的存取頻寬也會降低。
因應上述使用情境,Nvidia認為,可以發展某種形式的XBAR來彙整大量GPU的串接,使它們能夠存取彼此的GPU記憶體,就像由單一GPU驅動程式執行個體來統籌控制。而有了這樣的XBAR,GPU記憶體的存取,不再需要其他處理程序介入來幫忙,而且可獲得足夠的頻寬,而提供與雙GPU組態相同的效能擴展能力,於是NVSwitch應運而生。
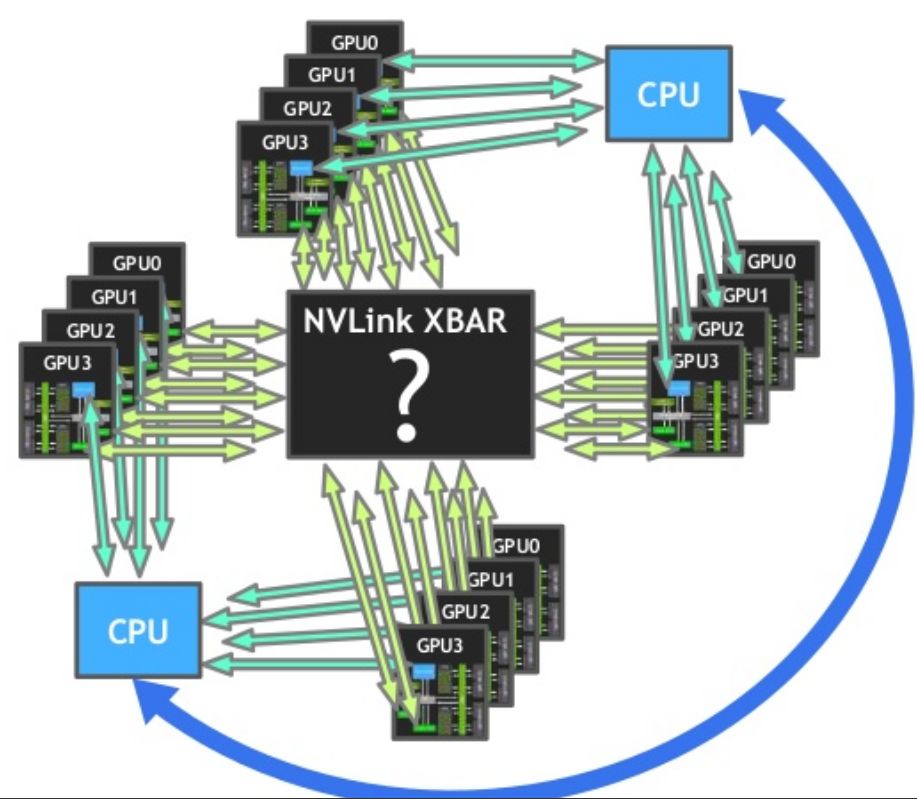
若單就構造來看,NVSwitch也可說是一種橋接GPU的裝置,能夠提供基於NVLink的交織網路環境,封包轉換會在連接埠邏輯的區塊(Port Logic blocks)進行,讓I/O流量都能前往多個GPU,或讓I/O流量源於多個GPU ,就像在單一GPU進行傳輸。
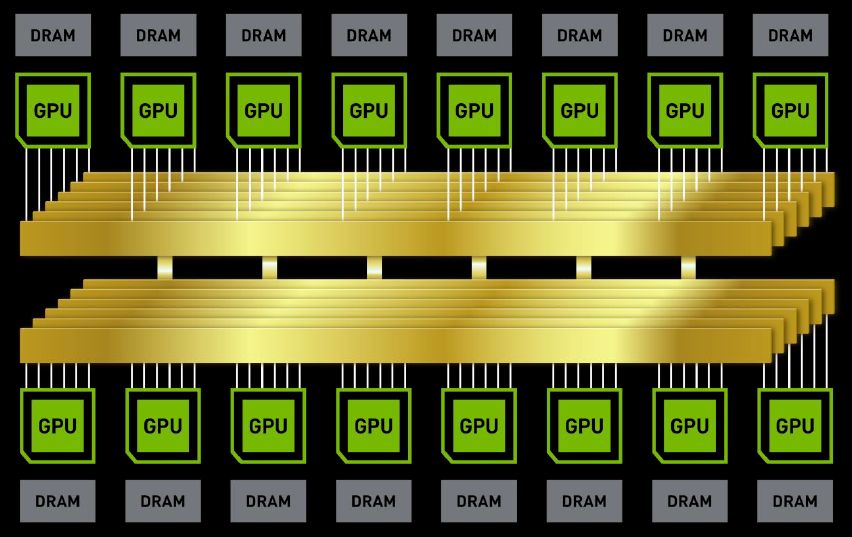
而且,多顆NVSwitch晶片會平行地運作,以支援越來越大量的GPU連接。基本上,3顆NVSwitch晶片可建構一套8套GPU串接的系統。每一顆NVSwitch晶片在連接每一套GPU時,會用到2個NVLink連結路徑,而交叉存取的流量可以橫跨所有的NVLink和NVSwitch,因此GPU之間會以成對的方式進行溝通,而能使用300GB/s的雙向頻寬。

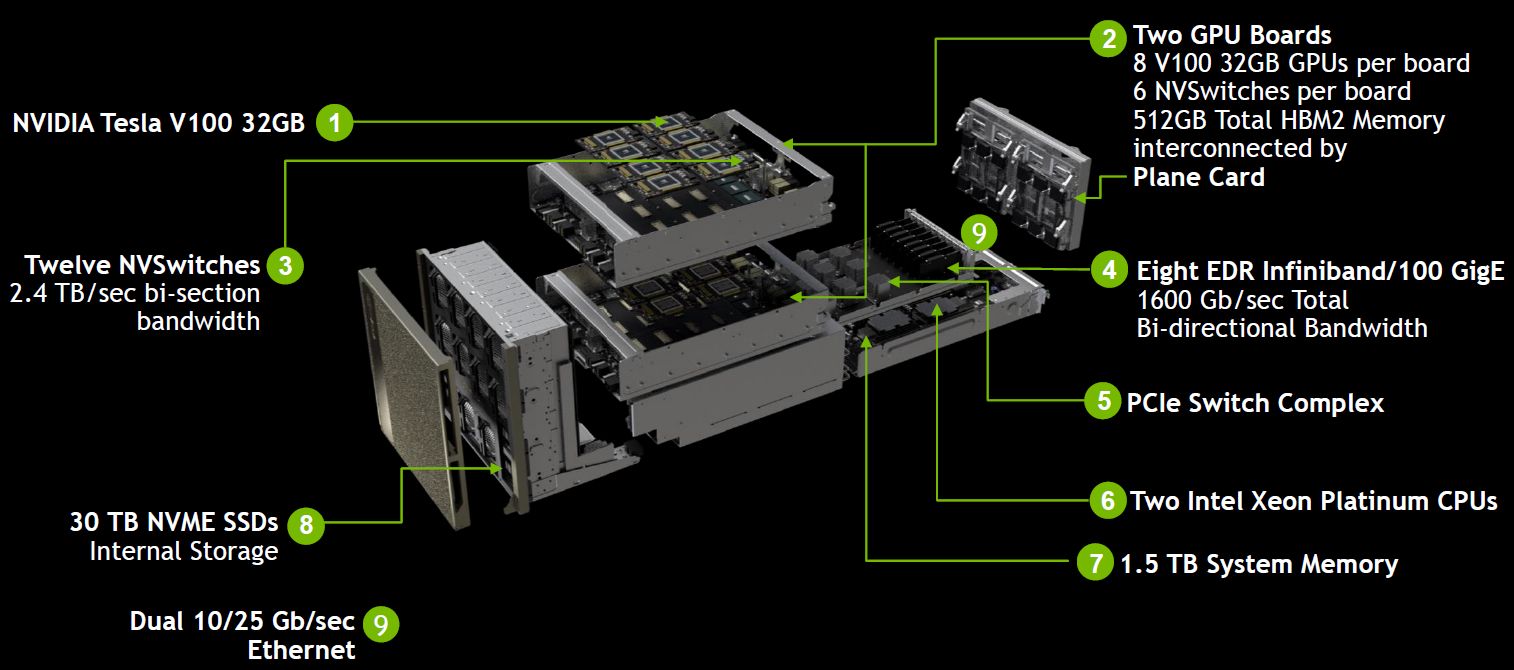
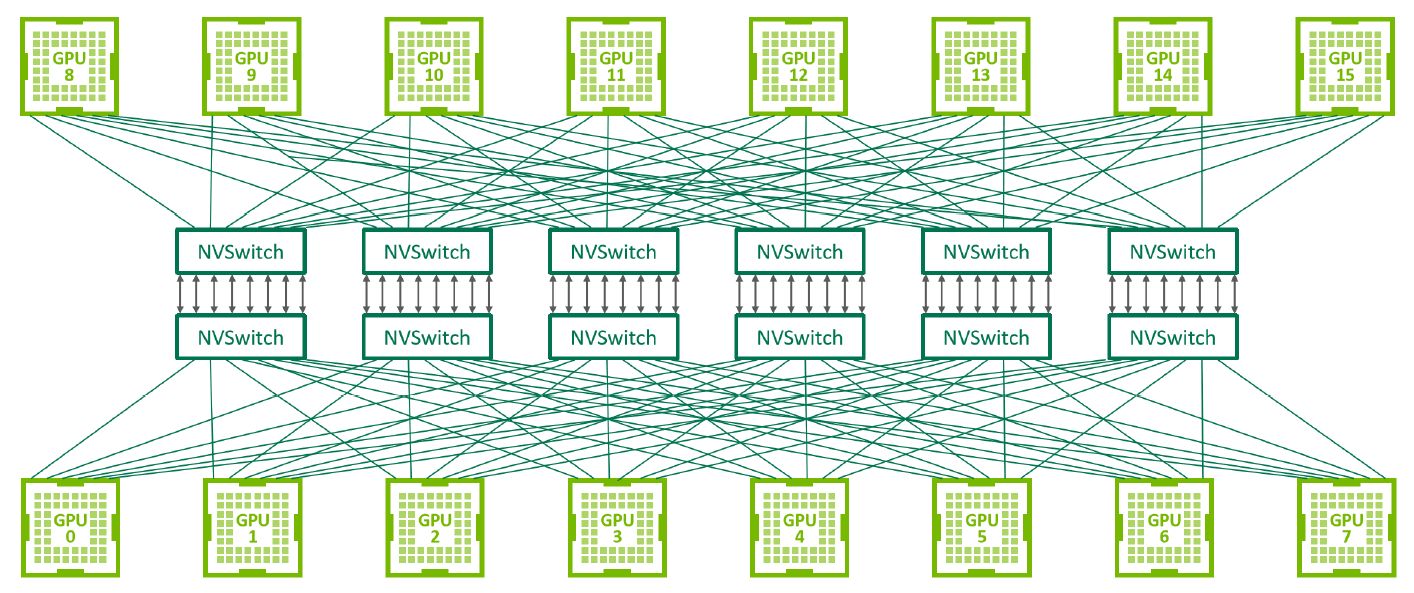
而在實際的互連組態上,DGX-2配置了12個NVSwitch晶片,而Nvidia在兩張各自承載8套GPU的基板之間,提供2.4 TB/s的雙向I/O頻寬,能夠支援單臺伺服器16套GPU運算模組互連組態,協助整臺系統能夠共用多達512 GB的GPU記憶體空間,以及2 PFLOPS的深度學習運算能力,藉此應付超大型的資料集,以及非常複雜的深度學習模型,例如類神經網路的平行訓練。





產品資訊
Nvidia DGX-2
●原廠:Nvidia(02)6605-5700
●建議售價:廠商未提供
●機箱尺寸:10U
●處理器:DGX-2為2顆24核心Intel Xeon Platinum 8168 2.7 GHz,
DGX-2H為2顆24核心Intel Xeon Platinum 8174 3.1 GHz
●系統記憶體:1.5 TB
●硬碟:2臺960 GB NVMe SSD(RAID 0),搭配8臺3.84 TB NVMe SSD
●GPU加速模組:16套Nvidia Tesla V100(5120顆CUDA核心、32GB CoWoS HBM2記憶體、900 GB/s記憶體頻寬)
●網路介面:8個100 GbE埠或100 Gb/s InfiniBand埠、2個10/25 GbE埠
●軟體:Ubuntu Server Linux OS、DGX-2 Software Stack
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05