iThome
面對巨量資料,IBM是以去年併購的資料倉儲廠商Netezza的資料倉儲產品TwinFin應戰。IBM軟體事業處資訊工程顧問莊惟欽表示,專責OLAP的資料倉儲與專責OLTP的資料庫,其應用與強項各有不同,但近年來,單純記錄交易資料已經無法區隔出企業的競爭力,因此,資料倉儲就成為企業發揮獨特優勢的工具。
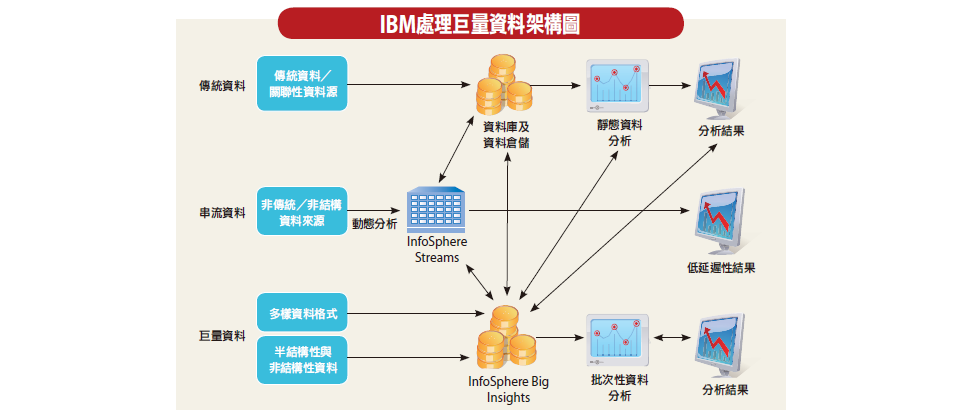
IBM針對巨量資料共有3種產品線,第一種是針對傳統關聯性有結構的資料,像是企業內部一般的ERP、CRM、採購等所產生的資料,第二種則是非傳統、非關聯的資料源,比如智能電網、股票交易等,都是在短時間內產生大量數據的系統,其中也包含了影像。第三種則是巨量資料,這種資料來源通常是非結構性以及半結構性,資料的格式也很多元,像是個人部落格、文件檔案等。
在資料處理的架構上,第一種資料則是藉由資料庫或是資料倉儲系統處理。第二種資料則是會藉由InfoSphere Streams處理感應器接收的資料,並不以儲存為目的,而是要快速回應,盡快提供分析結果。第三種資料,則是透過InfoSphere Big Insights平臺當作搜尋引擎,搜尋分析時所需要的文本資料。
InfoSphere Big Insights平臺可作為資料的存放空間,運用Hadoop中MapReduce的技術,搜尋存放在該平臺內部的檔案資料,但該平臺僅能進行簡單分析,例如文字敘述中的偏好等,企業若要進一步與歷史資料比對交叉分析的話,還是要靠底層資料庫架構將資料轉換成資料庫格式,再放到資料倉儲中運算。莊惟欽表示,MapReduce可以搜尋影音、文件、語音等檔案,但是在應用上,仍還是以文件為主。
TwinFin為了快速回應查詢,搭配了FPGA硬體分析伺服器,來負責大量資料解壓縮、欄位縮減過濾等動作,如同在硬碟與主機資料庫中加裝了加速卡,解決巨量資料從磁碟取出放入主機伺服器記憶體中分析的效能瓶頸,也讓資料存取的速度變快。
另外,莊維欽還強調TwinFin可將進階分析軟體如SAS、SPSS直接內建在資料倉儲的系統中,並支援平行處理進階分析軟體。
相關報導請參考「PB級資料的挑戰:巨量資料來襲」
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02