
辜騰玉攝影
聽了前面12場精彩的資料科學應用案例,「資料科學愛好者年會」第13場講者豪邁地說:「大資料要像家庭主婦煮飯一樣,打開冰箱後,有什麼食材就煮出什麼樣的飯菜,從有限的資料中去做應用。」這位講者在社群網站與資料科學技術應用上有近20年的豐富經驗,他說,在資料科學領域,不能先憑空想出一道完美佳餚,再去找所需的食材,因為事實往往跟想像有落差,尤其資料源自社群時,我們無法預期或者要求Google、FB提供所有符合期待的資料格式。
他是臺灣數位文化協會顧問洪進吉(暱稱為食夢黑貘),同時也是展雋創意的技術顧問、部落格觀察站站長,曾經協助架設莫拉克風災民間災情網路中心,集合民眾力量來彙整救災資料。今年他蒐集了180萬名臉書使用者的塗鴉牆資料,打造可以算出網路趨勢、結合時事議題的林克傳說。包括服貿東西軍等都是洪進吉在資料探勘、大資料的應用實例。它在這次的演講中分享了不一樣的大資料觀點,以及幾個大家對大資料常犯的迷思與錯覺。
洪進吉首先問大家有沒有想過,為什談「資料科學」,而不是智慧科學?以前讀資訊都會看到一個熟悉的金字塔,由下而上從資料、資訊、知識到智慧,為什麼要退回去資料的階段?他說,因為電腦只讀得懂資料,不知道什麼是智慧,人類嘗試教電腦什麼是資訊、知識、智慧,用各種演算法,將各式各樣的經驗從數字化變成可以再利用的東西,但要讓電腦追上人類,終究要從原始大量的資料開始計算。
他說,要從資料開始,很多人突然不知道從何應用,也因為習慣過去的思維及方式,在大資料應用過程中,容易產生一些謬論。洪進吉也說,現今社會到處都在講大資料,到處都是雲端,大資料已經不是致勝的關鍵點了,它甚至變成一個阻礙,需要被突破。
洪進吉提出四個系統分析的謬誤,也是他認為談大資料前值得思考的問題,包括從上到下的系統分析方式、目標與需求的連結性、大資料中的多樣性與真實性、自動化與人工化的探討。
過去要設計一套新的系統,有軟體工程的標準流程,大家會畫Top-down Design或是Mind Map,但現在,他說,若想要用這種方法來開發資料科學的系統,是完全錯誤的方式,應該放棄這樣的思維,他自己好幾次用這種方式開發系統,結果也都不了了之。他坦言,說到要完全放棄,自己也覺得害怕。
另外,是目標與需求連結的問題,既然很多資料來源在一開始就已經被限制,他認為那資料連結才是最大的問題。要完成一套系統不只靠程式設計師、系統分析師,需要非常多環節的人共同建立,從企業開發者到定義產品、開發產品、專案管理與操作者等。
他也說,早期企業產品經理常有的迷思,認為一定要有Profile、一定要做出資料區間化、只做內部決策參考用、也常在探究原因上花費了超過預期的時間,但其實很多好的大資料應用已經可以精準的預測到每個人、每個事件、每個時間點的預測分析,因此有些舊有思維是可以重新被思考的。洪進吉也認為,資料科學家不只是跨領域,而應該說是混領域的人,在各個領域都有一定度的專業能力,就像Maker一樣,必須自己動手來完成整件事情。
再來,對於大資料的多樣性與真實性問題,社群上使用者是否願意揭露自己,可能會影響資料呈現結果的真實性。洪進吉以林克傳說的分析為例,分析結果20%的人顯示自己地理資訊,其中三分之二的人說自己住在臺北,難道臺灣三分之二的臉書使用者都住臺北嗎?另外,五分之一的人都讀臺大,臺大真的有這麼多人嗎?還是念臺大的人較敢揭露自己?這些都是一些有趣的現象,可以思考大資料的真實性,是不是誠實反映了實際現象。
最後是自動化與人工化的探討,洪進吉分享他在今年打造的林克傳說,這套系統抓了180萬臉書使用者的塗鴉牆訊息,算出臺灣臉書熱門話題排行榜及五路趨勢, 並進一步分析使用者的閱讀偏好。但是,洪進吉說,知道網路趨勢,跟臺灣趨勢是兩回事。因此他們先運用人工智慧,透過系統自動化抓出資料,計算覆蓋率,找出重要的連結,甚至整合出議題,再靠工人(群眾)來定義標籤、集合標籤,判斷使用者的閱讀屬性,他將這稱之為人工智慧與工人智慧(群眾智慧)的結合。
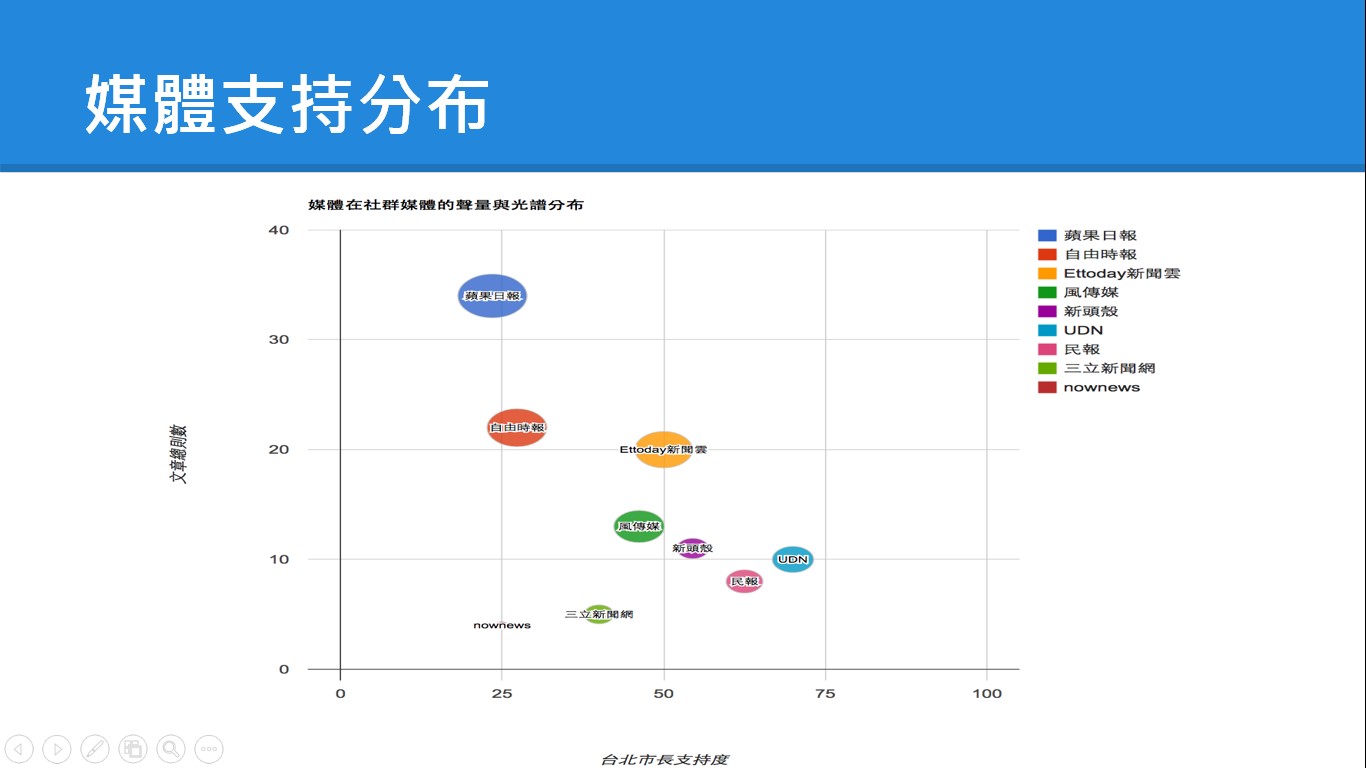
對於特定的議題,林克傳說透過連結的Tag屬性,算出整個網路趨勢。例如,從媒體在社群的聲量與光譜分布中,可以發現蘋果日報最支持柯文哲,而UDN最支持連勝文,還可以看到越支持柯文哲的聲量越大,越支持連勝文的聲量越小。
有些人都不表達自己意見怎麼辦?洪進吉說,這些人可能很少表達意見,但他會選擇資訊,從閱讀資訊的方式與來源、接觸的媒體資訊、加入的粉絲團,甚至是從朋友圈的屬性比例來做判斷,用工人智慧的選取來算出一個人的屬性與傾向。
林克傳說每個月要處理20億筆資料,對於利用業餘時間完成這些事情的團隊來說,其實是個很大的負擔,但洪進吉認為這是有趣的社會觀察,而且,在解決問題的過程中,會出現很多意料之外的中間產品。洪進吉也說,選擇工人智慧的方式來定義標籤準確度可達九成,若靠系統的人工智慧,大概只有六成的準確度。他認為,人的價值是電腦無法取代的,透過大資料的資料串集,再加上人的判斷,可以發現更多事情,解決更多問題。
林克傳說每天由系統自動化篩選出重要的100-200個連結,再交給由義工去定標籤,找到人的閱讀屬性與方向,甚至可以算出人的個性。

林克傳說透過連結的Tag屬性,可以做出整個網路趨勢。從媒體在社群的聲量與光譜分布,可以發現蘋果日報最支持柯文哲,而UDN最支持連勝文,還可以看到越支持柯文哲的聲量越大,越支持連勝文的聲量越小。
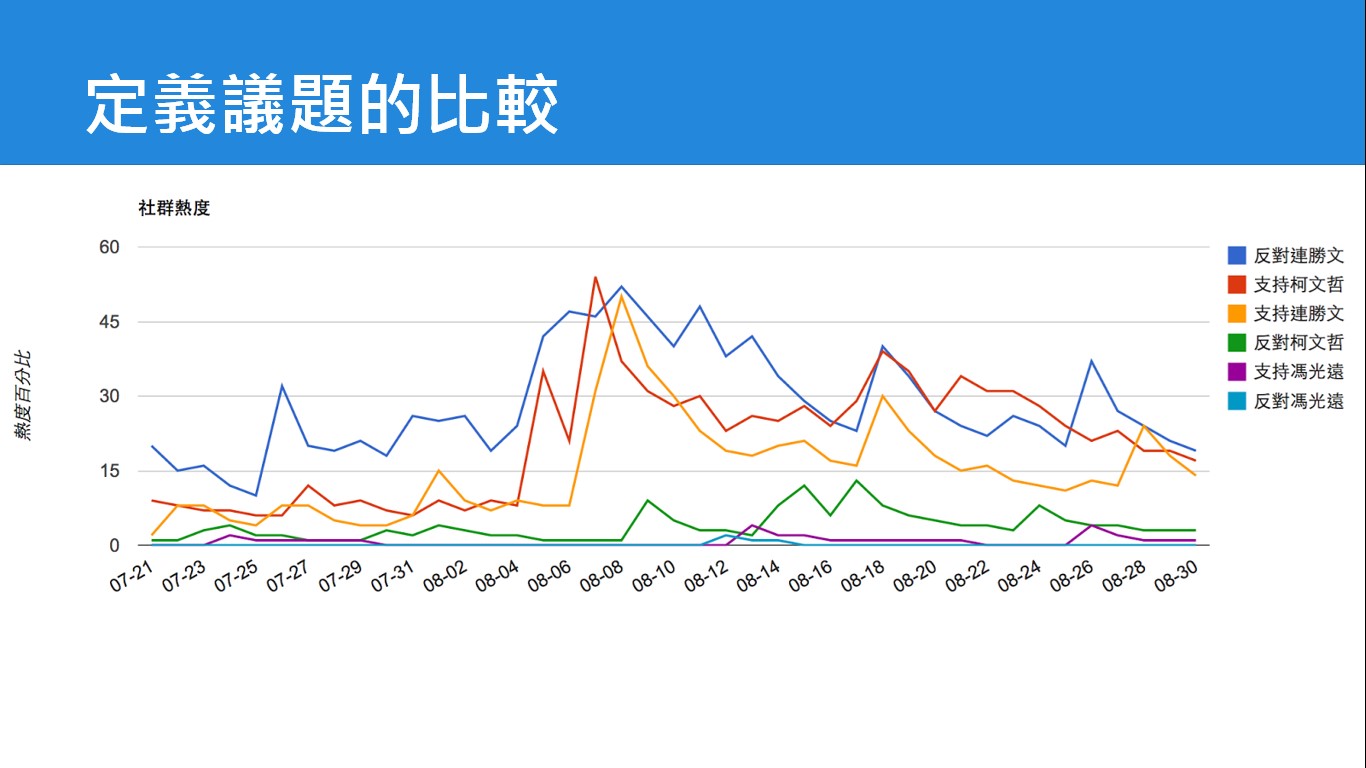
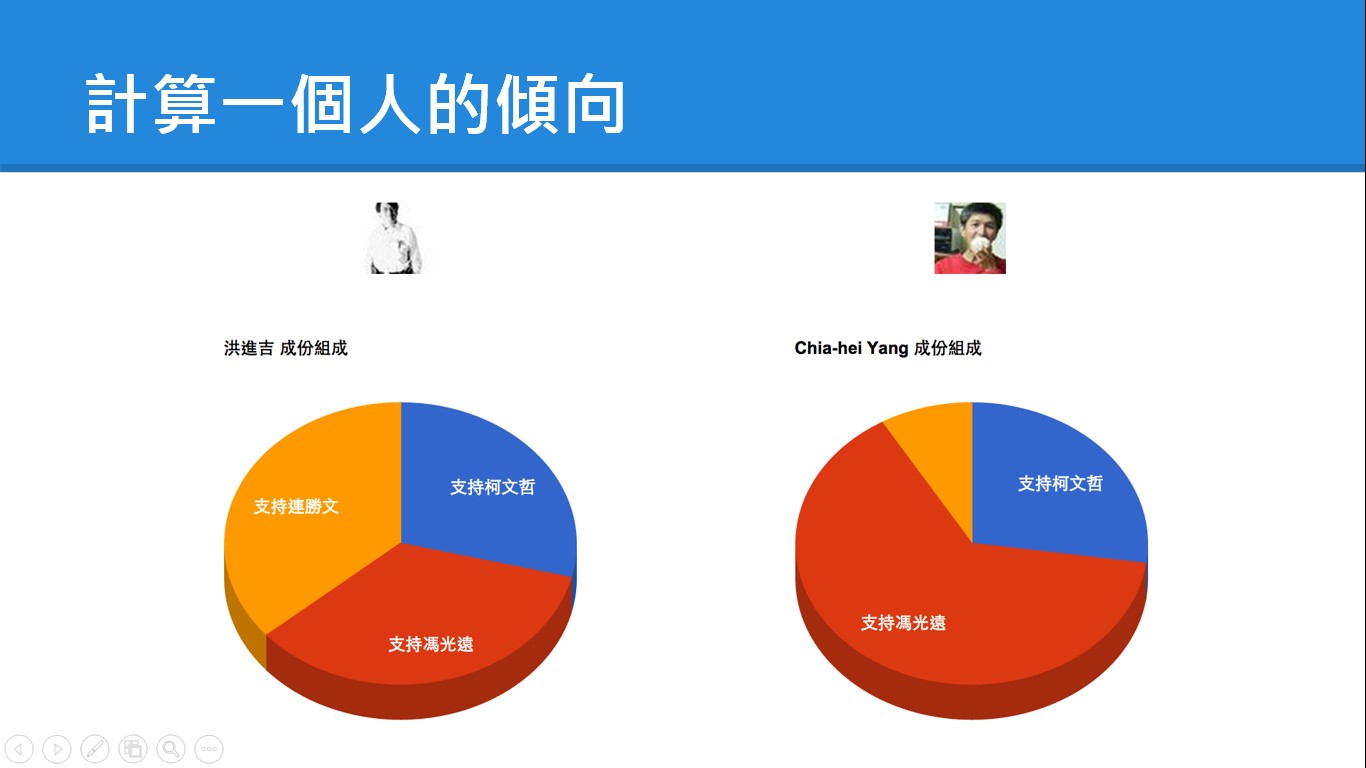
林克傳說從使用者閱讀資訊的方式與來源、接觸的媒體資訊、加入的粉絲團,甚至是從朋友圈的屬性比例來做判斷,用工人智慧的選取,來算出一個人的傾向。

熱門新聞

2026-03-02

2026-02-26

2026-02-27


2026-03-02

2026-02-27
")
2026-02-27

2026-02-27