前面我們列出2025年全球10起最大規模IT服務當機事件,接下來將從事故過程、影響範圍、事故發生原因,以及服務平臺的應對處理方式等幾個面向,逐一檢視每起事件的梗概與重點,進而比較不同平臺間的事故處理效率與透明度。
先從最嚴重的兩起事故開始看起——AWS大當機與韓國NIRS火災,再依影響規模,逐一審視其餘事故的狀況。
AWS特定服務區域發生大當機
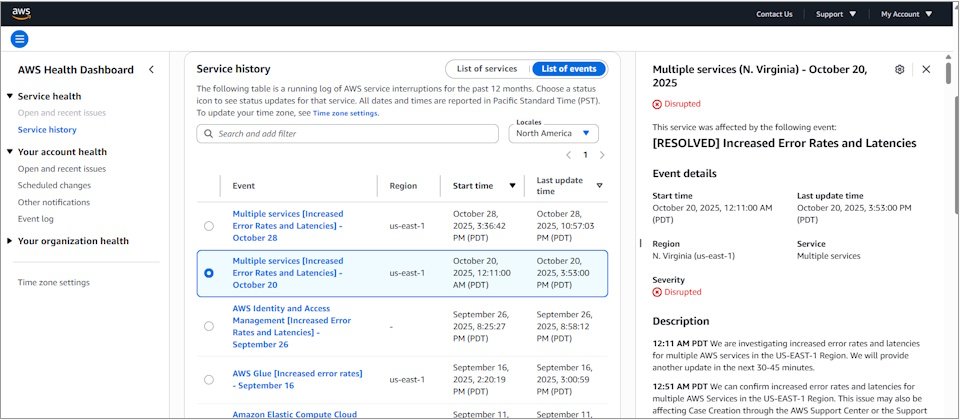
AWS位於美國維吉尼亞州北部的資料中心服務區域(Region)US-EAST-1,於太平洋時間(PDT)2025年10月19日至20日(臺灣時間10月20日至21日)發生大規模雲端服務中斷事故。
故障最初於太平洋時間10月19日晚間11點48分,被用戶與監測系統發現,直到10月20日下午2點20分才完全排除,影響時間約15小時。
數千個依靠AWS運作的網站、App與服務都因這次事故而中斷,或出現錯誤,其中受衝擊最大的包括Snapchat即時通訊服務、Reddit社群論壇、Fortnite與Roblox等線上遊戲平臺、Robinhood、Venmo、Coinbase等金融與支付應用服務平臺,還有教育SaaS服務Instructure、創作SaaS服務Canva等。AWS自身的電商零售服務、Prime Video、Alexa等平臺,也被波及。
另外一些用戶雖然本身不在US-EAST-1區域,但部分服務是依靠US-EAST-1資料中心的雲端基礎服務來運作,因而也受到這次事故的影響。
事故起因為US-EAST-1的DynamoDB端點,在更新DNS紀錄時發生錯誤,導致DNS解析異常。依賴DynamoDB的其他基礎架構服務(如EC2、Lambda)隨之癱瘓,進而引發連鎖反應,最終影響多達142項AWS服務。
事故發生後,AWS採取分階段復原策略,先修復DynamoDB的DNS問題,再透過重啟、服務遷移與流量限制等方式,逐一恢復其他受影響服務。
AWS對當機事故的公告
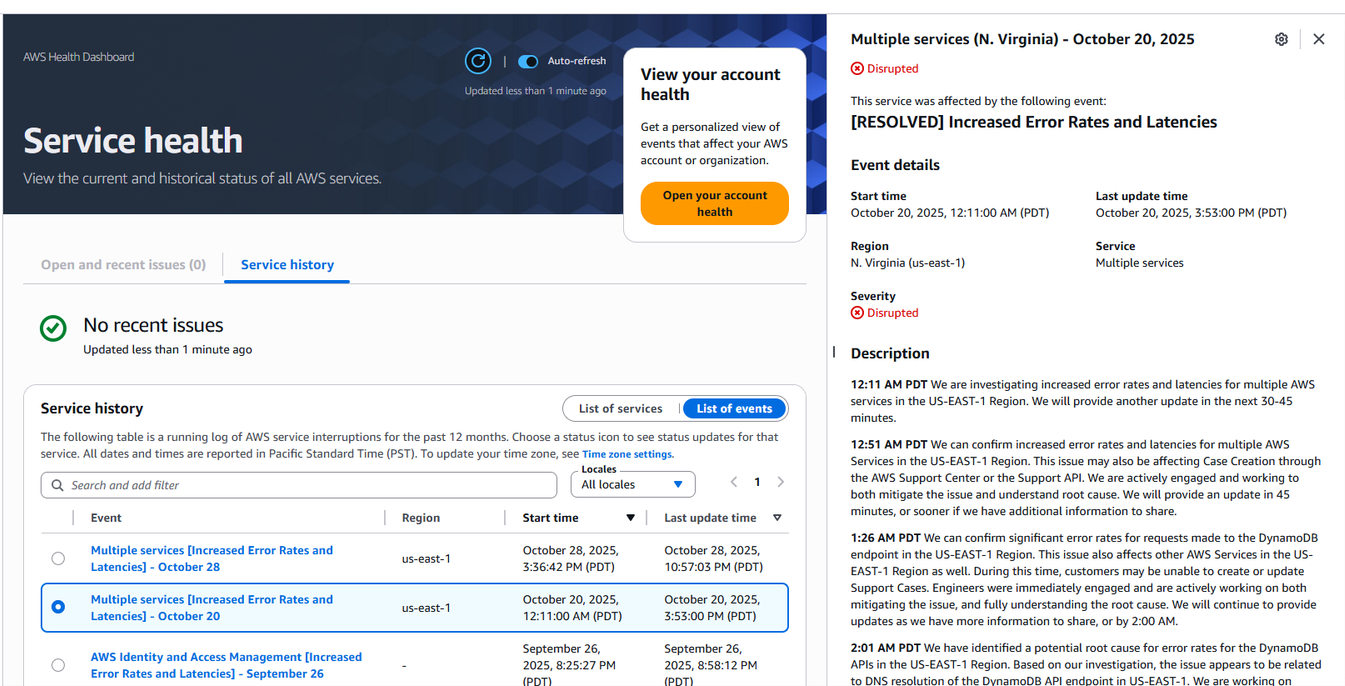
在10月20至21日事故期間,AWS持續透過Health Dashboard持續更新修復狀態訊息,事故後也提供詳細調查報告。圖片來源/AWS
這次事故的發生,再次突顯AWS控制平臺與管理後端過度集中於US-EAST-1,所產生的長期結構性問題。該區域是AWS最早建立、規模最大、功能最完整的區域,許多AWS核心工具與服務(如S3、IAM、CloudFront)預設使用或將API路由至此。一旦該區域發生故障,便可能引發全球性連鎖影響。
對用戶而言,僅採用多可用區(Multi-AZ)的備援架構,已不足以完全因應此類風險,必須透過跨區域(Multi-Region),甚至跨多雲(Multi-Cloud)架構才足以應對。
韓國國家資料中心大火
位於韓國大田(Daejeon)的國家資訊資源管理院(NIRS)資料中心,於2025年9月26日晚間8點20分(當地時間)發生嚴重火災。起火原因在於:資料中心內的不斷電系統(UPS)鋰電池在搬遷過程中起火,火勢蔓延至伺服器與電力設備區,歷時約22小時才完全撲滅。
此次事故共造成709個系統關閉或受損(最初公布為647個),受影響的系統包括Government24政府入口網站、Onnara電子公文簽署系統、KONEPS政府招標採購系統、G-Drive政府雲端檔案儲存服務、海關通關系統、線上警政案件登錄系統、線上郵局購物中心,支付兒童保育補助的「國民幸福卡」等。
其中96個系統完全毀損,受創最嚴重的是G-Drive。由於缺乏外部備份,該系統內存放的逾10萬名公務員業務資料無法復原。其他系統雖可透過備份重建,但即便未直接受火災損毀,也因國家綜合操作平臺(nTOPS)受損與現場清理作業延宕,導致復原進度極為緩慢。事故發生後72小時內,僅約7%的系統恢復運作;3週後,復原比例也僅略高於一半。直到12月30日,韓國行政安全部才宣布全部709個系統完成復原,距離火災發生已過95天。
如同我們在去年10月封面故事《鋰電池火災引發國家級危機:一場火災竟癱瘓政府資訊服務》提到的,這起事故可歸因於三層相互連鎖的關鍵疏失。
第一層疏失,是逾期使用UPS鋰電池,起火的鋰電池超過原廠10年保固期,原廠雖曾建議更換,但NIRS仍在檢查後繼續使用。
至於第二層疏失,是NIRS資料中心對鋰電池風險的不足。UPS配置缺乏必要的物理與熱隔離設計,沒有足以延緩熱擴散的環境防護機制,結果導致火勢迅速蔓延。
第三層疏失,則是備份與備援機制未能發揮預期的效果。除了G-Drive之外,其餘系統雖然依重要性差異而建置不同層級的備援與備份,但仍無法達成服務不中斷,或短時間內恢復運作的目標。
而這三層疏失,可總結為NIRS資料中心的整體安全標準不足,進而反映在電池運用政策、機房布置與消防設施,與備份備援措施方面的缺失。
基於這次火災的教訓,韓國政府後續也採取一系列補救措施,例如,韓國行政安全部將提高資料中心安全標準,強化災難備援系統,改善過往公共資料中心安全標準低於民營資料中心的問題,韓國政府也將增加行政安全部的預算,國會批准用於購買緊急復原所需的IT設備與遷移私有雲的490億韓元資金,以3,434億韓元改善主要災難復原系統,並逐步從老舊的大田資料中心搬遷。
Cloudflare的全球服務中斷
作為當前主要網際網路存取安全服務商之一的Cloudflare,去年一共發生兩起重大服務中斷事故,牽連到全球依賴該公司服務的企業網路服務。
6月12日當機事故
首先是在2025年6月12日,Cloudflare發生持續約2小時28分的服務中斷,從UTC時間17點52分持續到20點28分,不僅影響Cloudflare多項服務,也導致全球大量依賴Cloudflare的第三方網站與服務出現高錯誤率、延遲增加,甚至無法存取。
受這次事故影響的Cloudflare服務類型,包括:Workers KV、WARP、Access、Gateway、Images、Stream、Workers AI、Turnstile、AutoRAG以及Dashboard等。其中最嚴重的是Workers KV、AI Gateway、Stream與Realtime,存取請求與服務錯誤率都超過90%。
而受這次事故波及的第三方服務與網站,則包括Spotify、Discord、Twitch、Snapchat等社交與通訊平臺,Etsy、Shopify等電子商務平臺,Pokémon Trading Card Game(寶可夢集換式卡牌遊戲)與MLB.tv等娛樂平臺。
Cloudflare報告指出,起因是作為核心服務的Workers KV後端,由第三方提供的儲存區故障,導致Cloudflare服務使用的KV命名空間讀寫完全中斷,進而讓依賴Workers KV的多項功能發生連鎖失效。經由Cloudflare發現與確認問題後,他們藉由遷移Workers KV、調整路由與服務政策,繞開與減輕故障儲存區的影響,逐步恢復受影響服務的正常運作。
基於這次事故的教訓,Cloudflare表示將改進其儲存基礎架構的備援能力,消除對任何單一服務供應商的依賴,並針對本事件中受影響的各個產品,改進抵禦單點失效的能力。
11月18日當機事故
距6月事故不到半年,Cloudflare又發生一起規模更大的服務中斷事故。
2025年11月18日上午約11點20分(UTC時間),Cloudflare網路開始出現嚴重異常,核心網路流量無法正常傳遞,導致大量依賴其CDN、安全防護、代理與流量管理服務的網站與應用無法運作,普遍回傳HTTP 5xx錯誤或出現連線逾時。直到下午約17點06分(UTC)才全面恢復,事故持續時間接近5小時。
受影響的Cloudflare自身服務與產品包括:核心CDN與安全服務、Turnstile、Workers KV、Dashboard、Access與電子郵件安全服務等。
而受到牽連的第三方服務與網站,則包括社群平臺X(Twitter)、AI應用平臺ChatGPT、設計服務平臺Canva,還有Spotify Letterboxd、League of Legends等娛樂與遊戲網站,就連部分政府網站也受影響,例如臺灣「普發現金」網站(10000.gov.tw)。Downdetector網站的用戶異常通報數量,規模也達到6月12日那次Cloudflare事故(330萬對140萬)的兩倍以上,是自2019年7月的當機事故以來,Cloudflare最嚴重的一次事故。
Cloudflare的服務中斷說明

Cloudflare在2025年11月18日的大規模服務中斷期間,透過即時更新當前修復狀態訊息,事後也提供詳細調查說明,展現處理事故的透明度。圖片來源/Cloudflare
Cloudflare表示,事故之初,曾懷疑是遭遇超大規模DDoS攻擊,但事故發生後2.5小時,確認是Bot Management組態檔案錯誤造成。Bot Management是用於管理存取Cloudflare用戶端網站的模組,每隔幾分鐘便會收到由資料庫產生的更新組態檔案,然而一次對資料庫存取權限的調整,無意中產生大小為預期兩倍的組態檔案,進而觸發Cloudflare網路存取代理服務引擎出現錯誤。等到確認問題原因之後,Cloudflare藉由更新正確的Bot Management組態檔案,使得服務恢復正常。
針對這次事故的後續改善,Cloudflare表示,將強化內部的系統組態設定產生與自動部署流程中,對於邊界條件、檔案大小等潛在風險的驗證。
12月5日當機事故
除了前述兩起大規模事故之外,Cloudflare在12月5日再次發生嚴重當機,雖然事故規模相對較小,但時間距離11月18日大當機僅兩週,因而也十分受到矚目,我們亦一併介紹。
2025年12月5日上午8點47分(UTC時間),Cloudflare全球服務出現大規模中斷,導致大量經由Cloudflare代理的網站與應用服務回傳HTTP 500(Internal Server Error),約於9點12分完全恢復運作,持續時間約25分鐘。
相較前兩次事故,此次中斷時間明顯較短,但影響範圍仍相當廣泛。依 Cloudflare正式發布的報告,受影響的流量約占其提供的HTTP總流量28%,Cloudflare自身的Dashboard與API服務亦出現異常。
受到影響的第三方服務與網站則包括:視訊會議應用網站Zoom、社群網站LinkedIn、設計服務平臺Canva、加密貨幣網站Coinbase、AI應用網站Claude與Anthropic,HSBC、Zerodha、Zerodha Kite、Groww等銀行金融應用網站,還有一些政府、企業、娛樂與電商平臺網站(如Deliveroo、Shopify)也出現HTTP 500錯誤訊息。
Cloudflare表示,此次事故起因為WAF(Web Application Firewall)組態修改。為因應剛揭露的Next.js開發框架重大漏洞CVE-2025-55182(CVSS嚴重性評分10.0),Cloudflare將WAF緩衝區大小從128KB提高至1MB。然而此一變更意外觸發Cloudflare舊版FL1 Proxy架構中的缺陷,導致代理服務當機並回傳HTTP 500錯誤。Cloudflare發現問題後,透過恢復原本組態而讓服務恢復正常。
Cloudflare指出,這起事故是新的組態變更與舊有程式碼互動缺陷所導致,並表示將檢討內部部署與測試流程,強化漸進式部署與回復(rollback)機制,以及提升組態變更與代理服務程式碼的整體品質。
報導未完 請見:全面檢視2025全球10大IT當機事件(下)

熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02