Downdetector
基於大型資料中心所構成的IT服務平臺,是現代社會的數位基礎建設核心,支撐著政府、企業與民眾的日常運作。因此,這些平臺與資料中心一旦因事故導致服務中斷,勢必對政府公共事務、企業營運,以及個人服務造成嚴重衝擊。
僅在2025這一年內,全球就發生多起影響範圍達到國家級,甚至屬於跨國級的重大IT服務中斷事故,例如AWS美東區域資料中心故障、韓國政府資料中心火災,以及Cloudflare全球服務中斷等。
這些大規模故障,使大量仰賴相關資料中心與雲端平臺運作的公共服務、企業業務,以及個人端應用程式與網站陷入癱瘓。服務停擺時間短則數小時,長則超過一天,從政府公務運作、企業營運到個人日常IT服務皆受到波及,造成的經濟損失更是難以估計,也動搖了用戶對這些服務與平臺的信任。
事實上,儘管大型資料中心與雲端服務平臺,都已建置各式各樣的與備援機制,力求避免因偶發事故造成服務中斷,仍無法完全杜絕意外停擺的情況。
這也讓人不禁要問:這些平臺與資料中心故障的原因為何?為什麼精心設計的備援與保護措施沒有生效,導致故障後的長時間服務中斷?
為此我們在這次製作的封面故事中,將透過回顧2025年全球IT服務與資料中心的重大當機事件,檢視成因、進而重新審視雲端服務的風險。
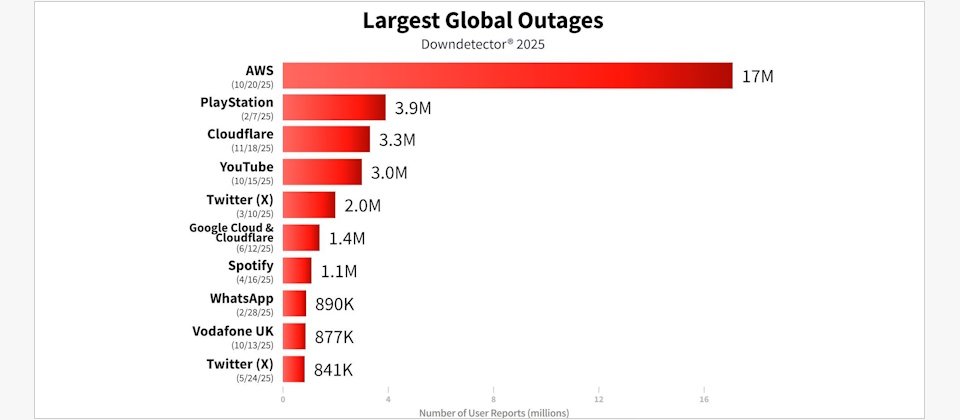
2025年重大當機事件一覽
我們先依據故障事故發生時間順序,列出2025年影響最重大的10起全球IT服務與資料中心當機事件,以及事故持續時間,再逐一檢視個別事故的情況:
● 2月7日至8日,PlayStation Network線上服務當機,停擺約24小時。
● 2月28日,WhatsApp訊息服務當機,停擺約1小時。
● 3月10日,X(Twitter)社群網站服務間歇性中斷,停擺約24小時。
● 4月16日,Spotify音樂串流服務當機,停擺約3.5小時。
● 6月12日,Cloudflare網路資安服務當機,停擺約2.5小時。
● 6月12日,Google Cloud雲端服務中斷,停擺約7.5小時。
● 9月26日至27日,韓國國家資訊資源管理院(NIRS)大田資料中心火災,受損服務95天後完全復原。
● 10月15日,YouTube影音媒體平臺故障,停擺約2小時。
● 10月20日至21日,AWS美國東部1區(US-EAST-1)資料中心故障,15小時後復原所有服務。
● 11月18日,Cloudflare網路資安服務當機,約5小時。
上述全球IT服務大當機的事故挑選,源自分析機構Ookla旗下Downdetector網站的全球資料中心監測資料,我們根據2025年12月的報告《Largest Outages of 2025: A Downdetector Analysis》,所列出的重大事故為基礎,再結合我們收集的事故資料。依循Ookla報告,我們判斷事故嚴重性的基本原則,是以受事故影響的用戶規模為基準,而受到當機影響的用戶規模,主要依據Downdetector統計的用戶通報故障數量。
原則上,受影響用戶多寡,並非判斷IT服務當機事故嚴重性的唯一標準,有一些事故影響的用戶雖然不多,後果卻十分嚴重。例如,澳洲電信公司Optus,在2025年9月18日發生緊急呼叫服務中斷13小時事件,表面上雖然只造成600多通緊急呼叫失敗,但導致4位民眾因無法聯繫緊急服務而喪命。
不過,為了取得一致、可供對比的標準,我們這裡仍以受影響用戶規模,作為篩選重大事故的基準。
除了前述列出10起事故,另有一些事故受影響用戶規模也相當龐大,而且,是因前述列出的事故牽連而發生,例如:社群媒體服務Snapchat在2025年10月20日的當機,便是受到同日發生的AWS雲端服務當機所導致,並非獨立事件,便不列入此處討論。
事故型態的初步區分
上述10起重大當機事故,影響程度皆達百萬用戶等級。若以影響的規模大小來看,最嚴重的兩起事故,分別是2025年10月的AWS當機事件(Downdetector記錄的用戶故障回報高達1,700萬件),以及2025年9月的韓國國家資料中心火災事故(導致韓國政府約三分之一的線上資訊業務與服務癱瘓)。
從事故持續時間來看,這10起事件中,有一半以上(5起)在5小時內恢復正常服務;另有兩起服務中斷介於8至15小時之間;2起事故的受影響時間達到24小時;剩餘1起則持續超過24小時。影響時間最長的,正是韓國國家資料中心火災事故——事故後72小時僅復原7%系統,3週後復原率僅達到50%,95天後才完全修復所有受損系統。
雖然韓國國家資料中心事故的服務異常延續時間格外驚人,但若將其視為特例,其餘9起事故皆能在數小時至1天內排除問題並恢復服務,顯示目前大型資料中心與服務平臺在遭遇重大事故時,可達成的復原時間目標(RTO)大致落在數小時至1天的範圍內。
從發生事故的平臺類型來看,這10起事故共涉及9個平臺,其中Cloudflare占兩起,其餘8個平臺各1起,可概分為4種類型:
一、雲端基礎架構與應用服務平臺,包括:AWS、Google Cloud、Cloudflare等公有雲業者的環境。
二、社群與即時通訊平臺,包括:WhatsApp與X(Twitter)。
三、娛樂與線上串流服務平臺,包括:PlayStation Network、Spotify、YouTube。
四、政府公共服務平臺,即韓國國家資訊資源管理院(NIRS)管理的政府平臺。
這4種類型涵蓋當前多數民眾日常使用的IT服務平臺,也包含全球最大規模的網路服務業者,如AWS、Google Cloud、YouTube與X(Twitter),以及國家級資料中心。
這意味著,無論是哪一種類型IT平臺,即便是全球屈指可數的超大規模系統,也難以完全避免發生重大事故的風險。我們日常使用的各類線上IT服務,無論政府資訊系統、公有雲、社群媒體或娛樂平臺,都可能因意外而中斷。
進一步來看,既然服務中斷難以完全避免,另一個關鍵重點便在於服務平臺在遭遇事故時的應變與處理能力,是否能在最短時間內修復問題、恢復服務,並同時向用戶提供充分且透明的公開資訊,以避免彼此不必要的誤解、恐慌與信任流失。
因此,接下來我們將逐一檢視每起事故的發生經過,比較各平臺的應對效率與事件處理透明度。
2025年10大IT服務當機事件
2月7–8日 PlayStation Network線上遊戲服務當機
2月28日 WhatsApp訊息服務當機
3月10日 X(Twitter)社群網站服務間歇性中斷
4月16日 Spotify音樂串流服務當機
6月12日 Cloudflare網路資安服務當機
6月12日 Google Cloud雲端服務中斷
9月26-27日 韓國國家資訊資源管理院(NIRS)大田資料中心火災
10月15日 YouTube影音媒體服務中斷
10月20-21日 AWS 美國東部1區(US-EAST-1)資料中心故障
11月18日 Cloudflare網路資安服務當機
資料來源:iThome整理,2026年1月

熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02