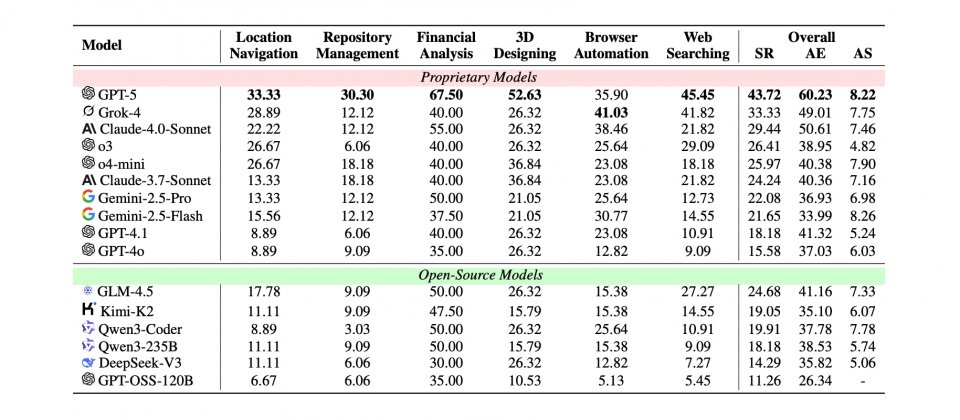
由Salesforce人工智慧研究團隊提出的最新MCP-Universe基準測試顯示,OpenAI的GPT-5在連結工具並完成多步驟任務場景的整體成功率為43.72%,雖然已經是所有受測模型中最高,但仍未突破一半,突顯代理型AI在實務應用上可靠性不足。研究同時指出,長脈絡處理與面對陌生工具時的適應力,是目前主要的限制。
MCP-Universe以MCP(Model Context Protocol)作為統一介面,直接串接實機MCP伺服器,讓模型必須在實際環境中完成操作。測試涵蓋六大領域,包括地理導引、版本庫管理、財務分析、3D設計、瀏覽器自動化以及網頁搜尋,總共涵蓋11個伺服器231項任務。這樣的設計有別於傳統的靜態資料集,更能檢驗模型真實應用場景的多輪規畫與工具協作能力。
評分方式採用執行式評估,並非單純依賴大型語言模型的主觀判斷,評估項目分為格式檢查、靜態比對與動態測試,其中動態測試會即時抓取正確的外部資料,例如股價、票務或天氣資訊,用於時間敏感型任務。這樣的設計能更貼近實務需求,同時確保在不同測試時點也能維持一致的評估基準。
在多模型對照中,GPT-5的43.72%成功率居首,xAI的Grok-4為33.33%,Anthropic的Claude-4.0-Sonnet則為29.44%。研究人員進一步分析指出,當互動步驟增加導致脈絡過長,或遇到參數格式各異的工具時,模型表現會明顯下滑。此外,子領域成績落差也相當大,例如GPT-5在財務分析任務中達到67.5%的成功率,但在地理導引與版本庫管理上表現不佳。
實際任務包含透過Google Maps MCP規畫會面地點、在GitHub MCP進行版本控制操作、以Yahoo Finance MCP進行股市分析、使用Blender MCP處理設計任務、透過Playwright MCP自動化瀏覽器操作,以及利用Google Search MCP與Fetch MCP進行資訊檢索。這些任務都要求模型能正確理解指令,並在實機限制下執行操作並回報結果。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02