
生成式AI快速發展,然而,現今主流的AI模型使用的訓練語料多為英文或是簡體中文,導致模型缺少對台灣本地語言習慣、在地文化及價值觀,漸漸可能使台灣的在地語言在AI時代被邊緣化。IMA資訊經理人協會今年推動Taiwan Tongues「台灣通用語料庫計畫」,希望建立高品質的台灣語料庫,在號召之下,現在已有數十位作家參與、貢獻累計超過500萬字文學作品。
IMA協會理事長蔡祈岩表示,AI快速發展後,儘管能夠支援繁體中文,但因為不瞭解台灣的語言,導致使用錯誤的用語或是誤讀台灣的語言,IMA協會發起Taiwan Tongues,號召作家組成Team Taiwan,讓全世界能夠聽台灣,包括兩層涵意,一個是聽得懂且理解,另一個則象徵我們在AI的主體性及主權,要讓AI能理解台灣人的腔、習慣。
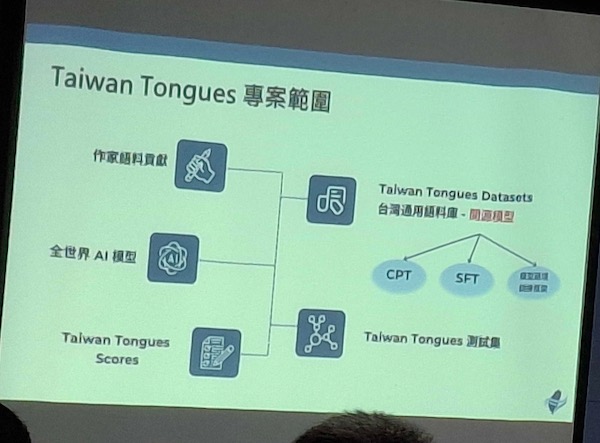
Taiwan Tongues目的為建立高品質的語料庫,一邊蒐集語料的同時,也將語料開源,該計畫號召台灣的文學作家參與授權,包括台灣使用的語言,包括台灣華語、台灣台語、台灣客語及原住民語,希望讓AI能夠聽懂、理解台灣的聲音。
這項計畫由IMA執委胡長松帶領,身為文學作家的他也帶頭無償釋出約150萬字的作品,號召更多作家加入,目前已有向陽、曾貴海等知名作家參與釋出他們的作品,累計已有超過500萬字的高品質語料。
胡長松指出,語言承載文化,作家或詩人擅長以詩文寄托文化價值觀,在AI時代下當本地的語言邊緣化,詩人、作家也應該站出來挽救語言、文化。Taiwan Tongues的目標是號召作家加入,共同建立高品質的台灣語料庫,目前已有不少的高品質語料,其中不少是台灣台語文學作品,已陸續上架到Hugging Face,以CC4.0授權,供外界非商業使用,例如語音助理、機器翻譯、語言教學、文化推廣等等,至於商業授權則必需與個別的作家談授權。
這個台灣語料庫,希望透過開源讓外界使用,除了協助台灣的企業或研究機構建立本地的模型,也希望讓國外主流的模型運用,為在AI時代下拉抬台灣在地語言、文化在全球AI模型的能見度。
除了發起台灣語料庫,Taiwan Tongues計畫也和群聯電子合作,利用其提供的運算硬體資源,結合Reward Model、RL微調,開發可訓練具備多元觀點辨識和區域語音調適能力的模型訓語境訓練框架,來幫助企業訓練在地化的AI模型,降低單一語料、單一觀點可能產生的偏差風險。
另外,協會也和陽明交智能所的廖元甫教授合作,建立一套台灣語境評測,可對模型驗證使用台灣語料庫後的成效,經過廖元甫帶領團隊的測試,使用Taiwan Tongues語料和教育部台灣辭典等公共語料,以CPT持續預訓練、SFT微調,經過台灣語料預訓練、微調,台語AI模型的正確率評分從31.5提高到42.6分,顯示台灣語料對模型帶來顯著的效果,提高對台語的理解、書信內容生成的正確率。
數發部次長林宜敬則表示,除了民間發起的台灣語料庫,未來數發部也會統籌推動公部門的語料,以組成政府機關語料,未來進一步深化公部門和私部門合作,力促政府和民間在語料開放、模型建構和應用評測的合作。另外,今天Taiwan Tongues為號招作家加入,以無償貢獻文學作品,對於不願意無償授權的作家,數發部未來也會建立適合的授權機制,讓更多作家能夠以合理的方式參與。
展望未來,IMA期望Taiwan Tongues繼續擴大台灣使用的華語、台語、客語、原住民語等多種語料,並希望和國際上的主流語言模型平臺合作,讓台灣的語言在全球AI生態中增加更多的能見度。
Taiwan Tongue也準備開啟Wiki Taiwan,增加台灣語言在網路世界的能見度,首先是針對台灣使用的華語,號召志工補齊維基百科裡只有英文而沒有繁體中文的條目,其次是針對台語,先將維基百科上約140筆的繁體中文條目轉為台語內容,再進行英文條目的翻譯補齊工作。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02