
奧丁丁AI團隊建置MCP伺服器,讓外部AI可以存取旗下OwlPay Harbor的API技術文件內容,方便外部開發者透過Cursor這類AI輔助開發工具的問答協助,更快串接API。
生成式AI帶動代理型AI(Agentic AI)興起,如何善用自主能力更勝以往的AI代理完成任務、事半功倍,一直是企業探索的重要議題。尤其,為讓驅動AI代理的大型語言模型(LLM)使用外部工具和資料、產出更精準的回答,開發者得為每個資料來源,進行複雜的客製化串接。
Model Context Protocol(MCP)因此應運而生,它就像統一的USB-C接口,不論資料還是工具,只要支援MCP,AI模型就能找到正確又即時的內容,給出更精準的答案。
奧丁丁集團最近就實作MCP,做出一套伺服器來連接對外API技術文件,方便Cursor這類AI輔助開發工具搜尋,讓外部開發者透過AI問答,協助串接API、降低技術門檻。奧丁丁AI團隊還預告,他們內部也要這麼做,建置MCP伺服器來連接內部文件、加速自家開發流程。
緣起:API串接的3大痛點
奧丁丁AI團隊首先點出,以往企業將AI介接外部工具或資源時,都會面臨3大挑戰。
第一,開發者得先閱讀複雜的API技術文件。這是因為,開發者將AI串接外部特定資源時,得仰賴API,必須先閱讀對方提供的API技術文件,自己再撰寫一份指令,來教導AI如何使用這支工具或資源。
由於沒有統一的API技術文件規格,這些文件可以很複雜,而且「AI所串接的每一支工具或資料庫,我都要這麼做,累積下來可能就有20、30份文件要處理。」
這情況帶出第二項挑戰,也就是維護成本。因為要處理的技術文件眾多,若提供API的企業或官方更改API,開發者就得重寫指令、重新教導AI使用該工具,衍生繁重的維護成本。
第三個挑戰是重工問題。奧丁丁AI團隊表示,由於AI介接外部工具沒有統一的規格,常常介接A工具使用A格式、B工具使用B格式,導致開發者花時間重工,開發效率低下。
不過,就在2024年11月,AI業者Anthropic發布開放協定MCP,將AI模型與外部資料或工具互動的方式標準化,就像是AI的USB-C般,來讓提供方和串接方遵循。
4大步驟實作MCP
常見的MCP支援方式有兩種,一是作為MCP Server(伺服器端),由開發者建置一個輕量級程式(即MCP Server),來讓外部AI或代理存取自家資源。另一種是作為MCP Client(客戶端),來使用MCP協定,讓自己的AI工具或代理存取各種支援MCP的資源,如知識庫、API等。
觀察MCP已久的奧丁丁AI團隊,在今年初決定用自家的對外服務OwlPay Harbor來試水溫。這是一款剛上線的API工具,支付業者可整合進自己的服務,來轉換法幣與穩定幣。
接著,奧丁丁AI團隊用4大步驟來實作MCP。第一步是設定目標,他們將目標定為,使用者可借AI之力,來更快速串接OwlPay Harbor。
意思是,奧丁丁選擇作為MCP伺服器端,建置一套MCP伺服器,來連接API技術文件,讓外部AI模型或代理存取。如此一來,外部開發者就能透過Cursor這類的AI問答,來簡化API串接。
串接MCP後,外部開發者可直接對AI輸入自然語言指令,AI代理就會自動將指令轉成搜尋關鍵字,透過MCP工具直接查詢技術文件,並自動產出API範例和專案架構,無需依賴外部搜尋引擎。
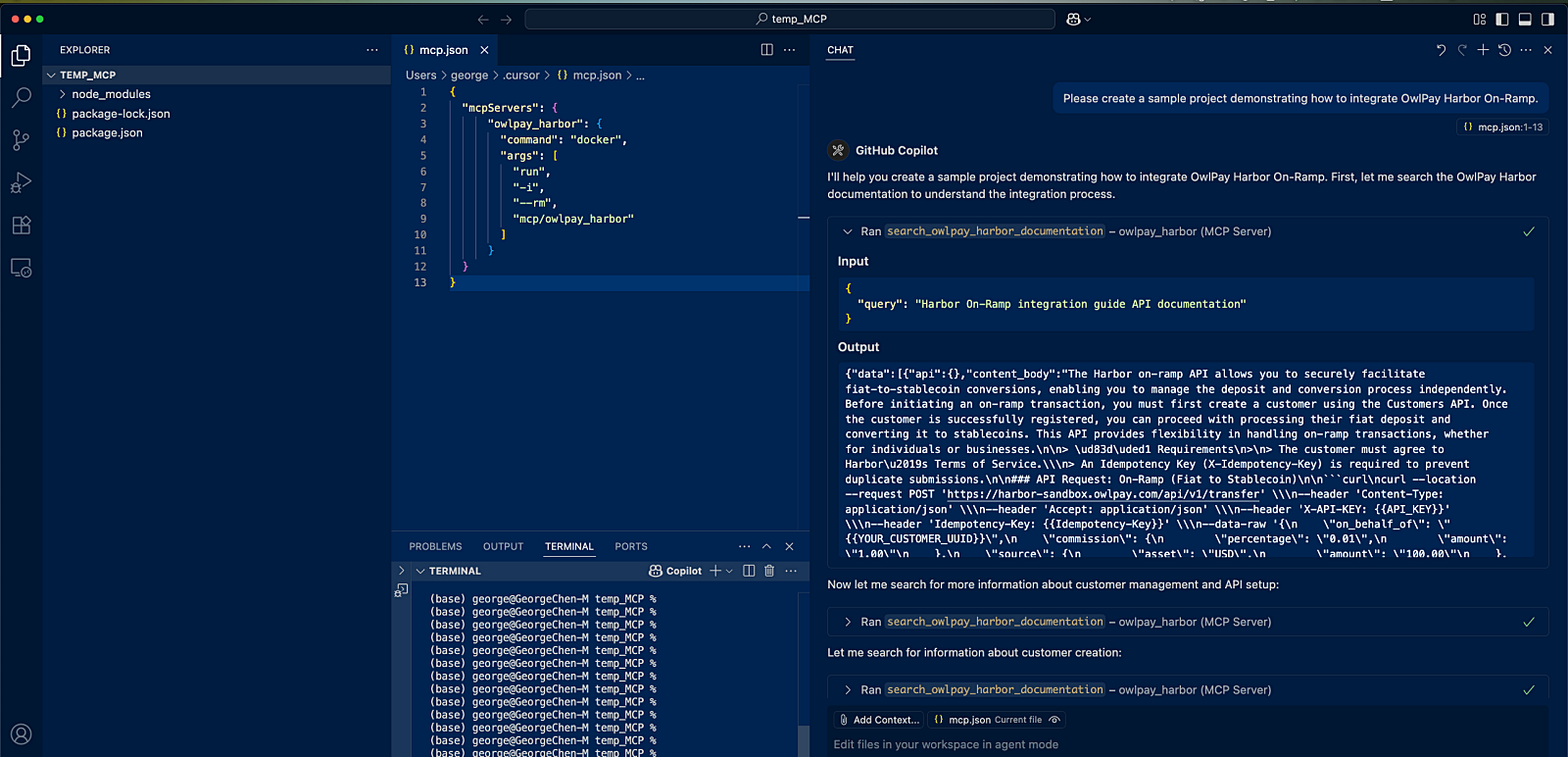
雖然MCP伺服器也能直接連結API,但奧丁丁AI團隊選擇只提供API技術文件、不提供整支API,是因為OwlPay Harbor為金流處理工具,涉及敏感資料,若由AI自動控制金流可能增加風險。因此他們採取比較審慎的作法,將MCP保留最小操作權限,只鎖定「引導企業使用者完成串接流程」,逐步協助使用者串接,而不是直接授權AI操作金流。
第二步是準備必要能力,也就是一支搜尋API,來告訴外部AI模型,如何檢索這些技術文件。這支API就像是查詢入口,讓AI在推論過程中,動態取得正確的文件內容。
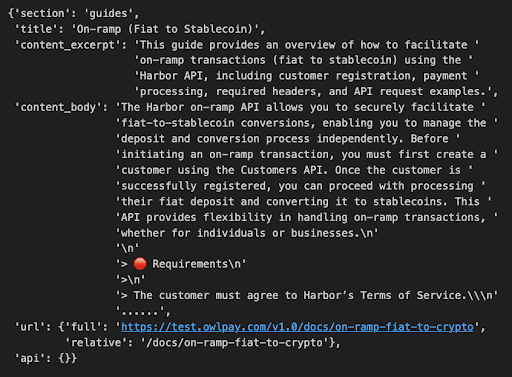
第三步是最有挑戰的一步,要將API技術文件轉換為AI可讀的形式。奧丁丁AI團隊解釋,要讓AI可搜尋檢索,就得將文件內容改為AI看得懂的格式,需要「高度語義化。」
意思是,文件的結構和內容,都要明確標註並分類其「是什麼」和「用來做什麼」,讓AI系統能自動理解並處理。舉例來說,好的MCP輸出結構,應該要「分層敘述」,也就是依序有大分類、標題、摘錄和主文的層次,且在功能欄位中,要將URL從文件中分離出來,而非混合為一。(如下圖)
另一方面,AI有其上下文窗口(Context window)限制,也就是AI一次互動可處理的最大Token(字符)數量,再加上AI多次互動時,會將先前的對話內容也算進窗口中,因此開發者必須控制文件長度,預留Token窗口供後續AI多次互動使用。
奧丁丁AI團隊根據經驗法則,將單次MCP查詢時所回覆的API文件內容,控制在模型最大可讀的Token總數一半以內。舉例來說,若模型上限為10萬個Token,單次回覆內容則控制在5萬個Token以內。這麼做,可以預留空間來讓AI有效理解問題本身、保持回應品質,避免「內容過長導致模型失效。」
與AI進行多輪對話時,AI會將過去的對話內容算進上下文窗口(Context window)中。因此,奧丁丁團隊將單次MCP查詢所回覆的內容,控制在模型最大可讀的Token總數一半。如此一來,AI才能有效理解問題、確保回應品質。
.png)
最後一步則是使用開源工具,如Anthropic釋出的MCP工具,來將處理好的OwlPay Harbor技術文件和搜尋API封裝成MCP工具並發布,來讓其他支援MCP的AI模型安裝、使用。
支援MCP不只降低開發門檻,還提供更精準回答
這種MCP支援,還有不少好處。比如對外部開發者來說,可以降低API串接門檻,不必單靠自己閱讀API技術文件,而是透過AI問答、輔助撰寫程式碼完成。
舉例來說,串接MCP後,開發者直接以自然語言輸入指令,AI代理就會自動將指令轉為搜尋關鍵字,透過MCP工具直接查詢技術文件,並自動產出API範例和專案架構,不必依賴外部搜尋引擎。
再來,透過MCP支援,AI搜尋的資料範圍更精準,回答也更準確。這是因為,AI工具使用外部搜尋引擎,尋找特定技術文件時,可能會搜尋到其他類似資料,並混在一起回答問題,進而產生幻覺。但透過MCP工具,AI可以存取特定內容並搜尋、產出答案,大幅降低取得錯誤或過時資訊的可能性。
另一個好處是,AI可透過MCP自主查詢整份文件、撰寫程式碼,不會處理一個段落後,再向使用者索取額外資料才能繼續作業。
除此之外,使用MCP還有安全上的好處。就使用者來說,AI工具透過MCP直接存取外部資源,使用者不必另外開網頁、複製資料再貼到AI工具中,因此相對安全。
對作為MCP伺服器端的企業來說,因為需根據目的,去設計能讓外部AI存取的內容,因此落實最小權限、給予最合適的內容範圍,也確保資料安全。
觀望者可從目標設定先著手
有了MCP實戰經驗,奧丁丁AI團隊也不藏私分享實作心得建議,供觀望者參考。
第一是確認目標,比如要做MCP伺服器端,還是MCP客戶端。決定後,才能思考該為AI準備什麼能力,並召集相關部門討論可行方案,開發團隊再給出開發方式、規格和時程。
第二個建議是安全性,也就是根據目標和希望給予AI的能力,來決定資料權限和範圍,比如奧丁丁決定將自家API技術文件打包成MCP工具,來供外部AI存取,那麼資料就得是原本已經公開的文件。
同理,若企業想將內部文件打包成MCP工具、供內部人員使用,也得先劃分資料使用權限與範圍,才能確保機敏資訊不外洩。
另一個建議是將文件改為AI可讀的形式,尤其是建置MCP伺服器來讓AI模型存取自家資料時,其資料格式、欄位就得高度語義化,且需保留適度的上下文窗口,才不會影響AI產出的答案。
這次實戰經驗,也讓奧丁丁AI團隊思考,未來要建置MCP伺服器來連接內部文件、資源,供內部團隊使用。尤其,奧丁丁AI團隊已高度運用AI協助開發,若AI能存取更多資料、工具,就更能加速開發流程,提高工作效率。文⊙王若樸
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02