")
微軟技術長Kevin Scott指出,Open Agentic Web由代理執行環境、通訊協定及外部世界3層次構成。微軟發表了用來解決第一層及第三層的技術瓶頸的開源專案,並宣布全面支持第二層的MCP協定。(圖片來源/微軟)
微軟對網路世界未來提出的新想像,以及由此而生的開源工具與框架,成了Build開發者大會最受關注的焦點。
去年,微軟乘著生成式AI熱潮,在開發者大會上祭出全面發展Copilot應用、開發工具及相關雲地端硬體的戰略。一年來,隨著生成式AI技術發展,更進階的代理式AI逐漸成為科技界焦點,微軟也開始強調,自家不斷推出的各式新Copilot助理,是一個個AI代理。
隨著AI代理技術更加成熟,加上MCP、A2A等AI代理用的通訊協定相繼推出,今年5月微軟開發者大會中,微軟CEO Satya Nadella大膽描繪出未來網路世界的一種可能──「Open Agentic Web」,微軟要提供開發者各式各樣的工具和所需基礎建設,讓開發者用來打造這個網路世界的新樣貌。
微軟對新網路時代的想像:Open Agentic Web
Open Agentic Web,這3個英文單字背後的概念,組成微軟想像中的未來網際網路樣貌。
首先,「Agentic」是核心概念,意指未來網際網路將充滿各式各樣的AI代理,執行組織與個人交付的工作。這些AI代理能處理複雜任務、存取多元資料來源、甚至與其他AI代理合作。
「Open」指是網路世界通用的開源框架與開源工具。微軟期望,透過提供網路開發社群開源、簡單的協定與工具,能促使網路世界更快速、更自由的發展,有如網際網路發展初期,HTTP及HTML這類簡單、共通的標準,讓開發者能共同打造網路新樣貌。
這正是為何,推出多款與AI代理相關的企業級產品同時,微軟也公布2款正在開發初期的開源專案TypeAgent與NLWeb,前者用來示範如何大幅強化AI代理記憶,後者則提供技術框架,讓AI代理能有效率的存取網站內容。這兩大工具,不只能在Azure上布署,亦可以部署於其他雲端或地端環境。
「Web」則是指網路世界中的網站。儘管如今網際網路世界有許多資訊傳遞通路,微軟仍聚焦世界上2億多個活躍網站,作為AI代理蒐集資料和執行任務的重要場域。他們還希望,以Web世界既有的共同協定和機制為基礎,如Schema.org、RSS等,來發展支援AI代理使用網站的技術,如NLWeb。
微軟技術長Kevin Scott進一步從技術架構角度來剖析Open Agentic Web的不同層次,分為Runtime(執行環境層次)、Protocol(協定層次)及World(外部世界層次)。
首先是Runtime層次的技術,這包括AI代理的記憶、推理、授權,以及實際執行任務相關技術。
Kevin Scott解釋,這個層級的技術已經相當強大,甚至出現人類開發者無法充分發揮AI代理能力上限的情況。不只如此,未來AI模型還會更多、更強、更便宜,使人類能用更低的成本,交付更複雜的任務給AI代理。
不過,AI代理技術再強,如果無法有效存取所需資訊,或與外部系統溝通,最終執行任務的能力還是有限。需要通訊協定(Protocol)層次技術,來實現這件事。代表技術如MCP與A2A,分別定義AI代理如何與其他系統溝通,以及AI代理之間如何溝通。
在第三層外部世界(World)層次上,則包括了網站、網路服務和其他AI代理。此層次系統高度支援與AI代理的互動,才能讓AI代理更好的穿梭於網路世界,完成任務。
微軟的目標是,支援這3個層級的技術發展,來促使Open Agentic Web更加蓬勃發展。
Runtime層技術:強大記憶能力的結構式RAG
AI代理要妥善執行複雜任務,需要能推理出適當執行步驟,到不同系統執行這些步驟的權限,以及實際執行步驟的能力。執行任務過程中,AI代理需要記得每個步驟與前後步驟的關聯,更需要記得過往與使用者的對話,作為背景知識。前述行為所需能力,分別需要代理執行環境(Runtime)層次的推理、授權、執行、以及記憶技術來實現。
其中,記憶力是AI代理是否具備,是其是否能執行連續或複雜任務的一大關鍵。然而現況是,生成式AI模型固然強大,但記憶能力有限。尤其在多輪對話或長期任務中,AI常常無法完整回憶先前對話內容或使用者偏好。
鎖定此瓶頸,微軟推出名為TypeAgent的開源專案。這是一組樣本程式碼(Sample code),示範微軟如何嘗試打造具有超強記憶力的AI代理,以及如何結合暫存等方法,讓系統執行任務時,能減少呼叫LLM的需求。微軟期待,此專案能提供一個共同方向,讓微軟及開源社群合作研究AI記憶力技術。
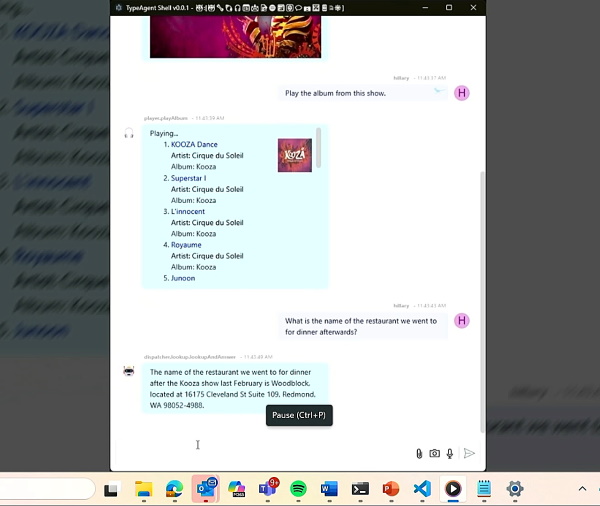
在TypeAgent示範中,AI代理可以在不提供過多上下文提示的情況下,記得使用者許久前造訪過的音樂會、播放該音樂會的專輯、回想當天去過的餐廳,並用使用者資訊再次訂位餐廳,展現出強大記憶力。圖片來源/微軟
微軟將TypeAgent中示範的記憶力技術稱為結構式RAG(Structured RAG),利用3大原理,來嘗試強化AI代理記憶能力和回想完整度,並降低生成式AI產生幻覺的機率。
首先是利用蒸餾法(Distillation),將AI代理所使用的模型蒸餾成邏輯演算法和物件結構,而非只是蒸餾成更小的模型。這種做法,使AI代理和傳統軟體溝通時,可以用更結構化、更明確的指令,進而降低AI代理回憶時,產生幻覺的機率。
再來是將語意資訊轉化成高資訊密度的高度結構化資料,使Transformer類語言模型的注意力可以有效聚焦在關鍵資訊上。如此,可以降低RAG資料所需儲存空間,同時讓模型聚焦在回憶所需的少量資訊,來減少遺忘或加入雜訊的可能性。
最後一點,則是透過將資料呈現成人類與AI模型都可以理解的邏輯結構,使人類可以打造搜尋圖譜(Search Graph),來引導AI搜尋記憶的方向,避免AI代理在執行複雜任務時出現意外的語意理解分歧。
在今年微軟開發者大會中,微軟用實際的範例,來比較結構化RAG與傳統RAG的成效差異,同樣都是用來回憶25集的Podcast節目,要盤點這些節目中,總共提及多少本書。結構化RAG範例使用3,000個輸入Token,準確回憶出63本書,若改為傳統RAG範例,則只有想起15本書,但是,卻需要輸入2倍的Token數量。
目前,微軟嘗試將TypeAgent原型中展示AI代理記憶技術和任務派遣技術,轉化為可供開發者使用的程式庫,以利整合於各式既有AI代理應用,像是微軟旗下服務,或是操作第三方服務如Spotify的AI代理。
TypeAgent技術仍處研究階段,微軟號召開發者社群一同研究,不過,官方提醒,目前不建議用於生產環境。
協定層布局:押寶MCP,所有微軟產品都支援
Kevin Scott在開發者大會中多次提到,當前對AI模型的運用,遠不及當前AI模型能力,尤其推理模型的能力更是沒有充分利用。
他觀察,除了軟體開發相關應用,幾乎沒有成熟的AI代理應用。究其原因,他認為是AI代理發揮能力的空間不足,即使模型再強大,也無法有效執行複雜任務。
為了讓AI代理充分發揮能力,微軟全面押寶MCP(模型上下文協定,Model Context Tool),將其發展成AI代理的共通標準。這項來自AI新創Anthropic提出的新溝通協定,定義了LLM存取外部資料和工具時的通訊規格。協定中,提供資料的端點為MCP伺服器,請求端則是MCP客戶端。
Kevin Scott說,微軟看中MCP簡單易用、容易普及的特性,可以成為Open Agentic Web通訊協定層的關鍵技術。為了支持MCP,微軟旗下產品,如GitHub、Copilot Studio、Dynamics 365、Azure AI Foundry、Semantic Kernel與Windows 11等服務,也逐步開始支援這項協定。
Kevin Scott則將MCP比喻成Open Agentic Web的HTTP。如今網際網路一組重要通用規格是,根據HTTP規格設立伺服器,並用HTML作為描述內容的語言。他們希望未來,當開發者要打造伺服器,呈現內容給AI代理時,MCP能扮演HTTP的角色。至於Open Agentic Web的新HTML角色,微軟希望藉由他們推出的開源框架NLWeb來扮演。
外部世界層技術:推NLWeb框架支援網站對AI代理呈現內容
執行任務時,AI常需要到網路上尋找資料。當AI代理需要在網站上尋找任務相關內容,目前常見方法仍是爬蟲網站內容後解析,以及模仿真人使用者,操縱鼠標在網站上來回點擊以尋找資訊。這種做法,動輒花費大量時間,查詢結果還不夠精確。
針對此一痛點,微軟挖角了Google自訂搜尋負責人R. V. Guha協助打造解方:一個可以讓AI代理直接和網站資料庫對話的框架NLWeb。R. V. Guha也是RSS、RDF等常見網路標準發明人,也是Schema.org網站的創建者。
網站可以利用NLWeb來建立更適合AI代理或是自然語言搜尋用的索引。NLWeb利用RSS、Schema.org等描述網站內容的標準格式。網站收到查詢請求時,NLWeb會結合搜尋技術和LLM技術,來拆解查詢內容背後所需的資料檢索請求、撈取出對應網站內容索引、再將搜尋出來的索引依照相關性排序。NLWeb框架內建MCP支援,可以用來打造自家網站的MCP伺服器,提供給AI代理更有效率的查詢站上資料。
用NLWeb來來重新索引、檢索、排序網站資訊,等於為網站打造了一款支援自然語言搜尋的AI搜尋功能。
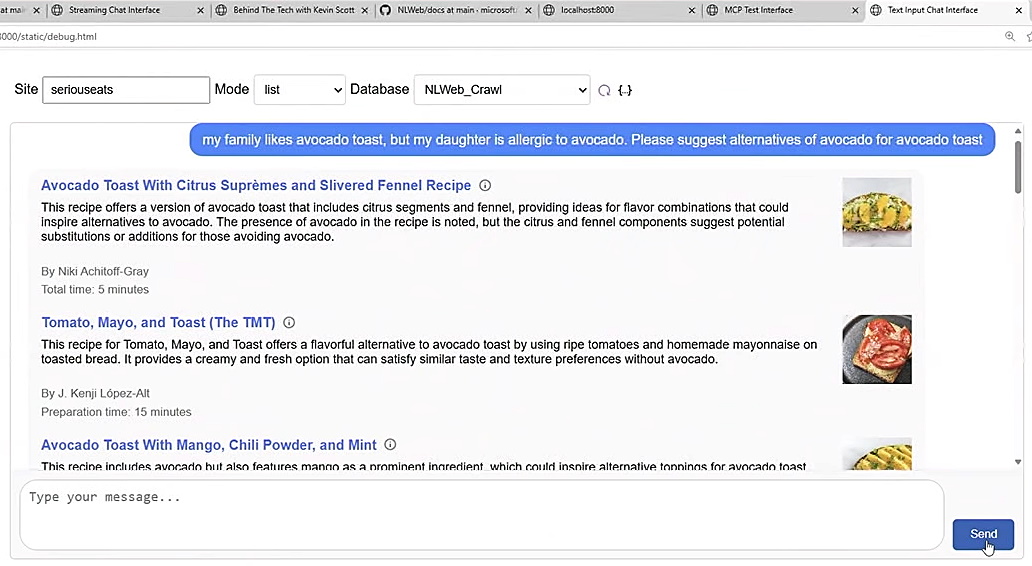
網站套用NLWeb框架後,就能利用LLM能力,來處理傳統搜尋機制難以理解的查詢問題,圖為NLWeb前端查詢介面的示範,網站主也可用NLWeb來設計站內搜尋。圖片來源/微軟
R. V. Guha舉例:「我對酪梨過敏,請推薦我酪梨吐司食譜,但酪梨使用酪梨替代品。」是極度刁難傳統搜尋機制的請求,不斷強調「酪梨」關鍵字,卻不要酪梨,又要食譜中含有「酪梨吐司」概念。用LLM驅動的搜尋機制,可以輕易理解這個自然語言查詢意圖。NLWeb不需要任何調整,即能搜尋出符合要求的結果。
微軟強調,NLWeb只是個簡單的框架,核心功能是提供資料轉化規則和查詢規則,以及串聯LLM和向量資料庫。網站主可以將其部署在任意環境,並圍繞著NLWeb打造各式各樣的網站體驗或MCP伺服器,而不限於簡單的站內搜尋功能。
例如,電商可以用NLWeb支援生成式AI購物助手,來推薦商品給顧客。或者,旅遊網站可以用來支援旅行規畫工具,來自動安排符合使用者行程的機票、飯店、餐廳和行程。
Kevin Scott比喻,HTML是瀏覽器解析出內容的通用格式,NLWeb則是提供一種AI代理可以查詢出網站內容的格式。呈現哪些內容、如何呈現,以及如何利用這些內容打造商業模式,都由網站主自行決定、自行打造。微軟期望,NLWeb未來能獲得如HTML般的普及性,成為Open Agentic Web中,AI代理與外部世界溝通的通用標準。
微軟產品策略如何結合Open Agentic Web願景
Kevin Scott強調,當Open Agentic Web的時代來臨,許多底層技術不被特定廠商綁定,才能使網際網路繼續蓬勃發展。諸如MCP、NLWeb、TypeAgent等技術,雖然都是大型科技公司提出,但開放所有開發者使用。微軟推出後兩者技術時,也強調可以部署於任何環境,並未設計專屬於Azure環境的系統優化。
產品布局上,微軟執行長Satya Nadella則於開發者大會中,說明微軟如何鎖定開發者打造Open Agentic Web的需求,從4個層次來支援這個願景的發展,分別是應用與代理層、AI平臺、資料,以及基礎設施。
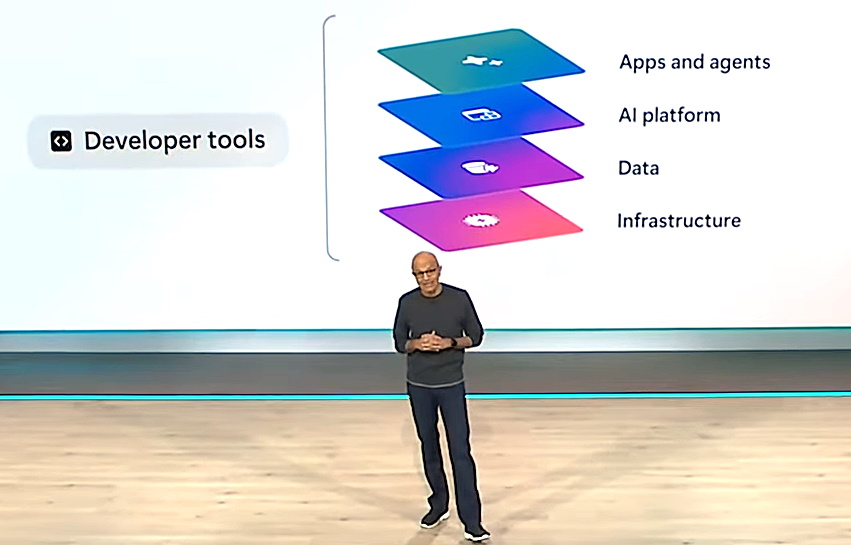
微軟執行長Satya Nadella在開發者大會中,將微軟Open Agentic Web發展策略分為應用層、開發平臺層、數據層及基礎建設層。其中,今年大量推出的AI代理工具多在第一層,而微軟雲端平臺上的AI開發平臺大量更新則屬於第二層。圖片來源/微軟
基礎設施層指的是Azure資料中心。Satya Nadella回顧Azure資料中心的規格與進展,例如自己是首家大規模部署NVIDIA GB200 GPU的雲端業者,以及近3月開設10家新資料中心等。
今年新產品宣布集中於前3層。應用與代理層的產品,包含許多開箱可用的AI代理工具。
例如,可以協助網站可靠性工程(SRE)的AI代理、協助使用者操作多款生產力工具的Microsoft 365 Copilot AI代理等。另外,還有用No-code方式打造AI代理的Copilot Tuning等。
AI平臺層的新服務,則是用來支援開發者在Azure AI Foundry平臺打造、部署、管理和調度AI應用與AI代理。這些新服務包括可以快速打造和部署AI代理的Foundry Agent Service、根據任務的性質可以自動選擇適合模型的Model Router,以及AI代理授權管理工具Entra Agent ID等。
微軟還宣布Foundry與Windows Defender整合,來強化AI代理從開發到應用的安全性把關。他們更宣布,Elon Musk旗下xAI的模型Grok將加入AI Froundry可用模型中。
資料層的更新則聚焦於支撐AI應用程式與代理所需的資料處理能力。例如,宣布將Cosmos DB與Azure Databricks等資料庫服務直接整合進AI Foundry,使AI應用能更即時存取所需資料。以及,在資料處理服務Microsoft Fabric中新增AI驅動的快速資料轉換功能等。此外,還有各式用LLM或AI代理來支援資料查詢及資料分析的新功能。
Satya Nadella總結:「微軟希望透過一個系統性、平臺性的方法,在系統每一個層級,支援開發者在Open Agentic Web中創造屬於自己的機會。」

熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02