
生成式AI帶動大語言模型應用,然而企業使用大語言模型(LLM),不論是自行訓練或是微調,可能產生資安風險,趨勢科技架構師蔡凱翔建議,可從大型語言模型應用程式的發展生命周期,利用方法論去檢視開發階段中的安全邊界,降低相關的資安風險。
「大語言模型的開發生命周期,就是一種機器學習和DevOps的綜合體」,蔡凱翔說,趨勢科技針對大語言模型的資安風險發布報告,建立一套檢視LLM安全的方法論,他在今年臺灣資安大會上對外分享如何實作大語言模型的資安實務。
蔡凱翔首先指出,大型語言模型應用程式的開發生命周期可以分為,「資料工程」、「預訓練」、「基礎模型選擇」、「領域適配 」、「評估」、「應用開發與整合」、「部署與監控」,不同的開發階段,需要選擇不同的工具或方案開發模型。
以「資料工程」階段為例,通常涵蓋資料擷取、資料前處理、資料儲存及管理,不論企業選擇從無到有開發LLM模型,以資料進行預訓練,但是自行開發投入的成本相當昂貴,因此多數企業會選擇開源LLM模型作為基礎模型,不論自行開發模型或使用開源模型,在後續「評估」或是「部署與監控」階段,如果模型開發不如預期或是部署後使用者的回饋反應不佳,都可能重新回到「資料工程」。
至於「預訓練」階段,企業需要選擇分詞器(Tokenization),建立檢查點(Checkpointing),以及在預訓練過程中,產生不同訓練版本模型的版本控制(Versioning models);「基礎模型選擇」階段,企業根據自己的需求,選擇使用開源模型或專用模型;「領域適配」階段,企業運用提示工程、RAG或是微調等技術,讓模型適用於特定的任務,以獲得更好的表現。
「評估」階段則使用工具或是以人工監方式,檢驗大語言模型的效能、可靠或安全性;「應用開發與整合」階段為LLM應用開發框架,依需求選擇不同的LLM應用開發框架,例如LangChain、Python的開源框架Haystack、LlamaIndex等,或是MCP協定;「部署與監控」階段為部署和監控的方式,與開發應用程式相同,包括部署的模式、部署的策略、可視工具等。
蔡凱翔說,企業依照LLM開發生命周期各個階段進行開發,對應涉及到LLM應用架構,這個架構內包含不同的區塊,如DevSecOps區塊、模型訓練區塊、資料來源區塊、資料儲存區塊,還有LLM應用區塊,其中因為AI Agent可能拉出LLM Agent子區塊,「不同區塊的安全邊界當發生信任程度(Trustworthy)的變化,這些邊界代表風險發生的地方」。
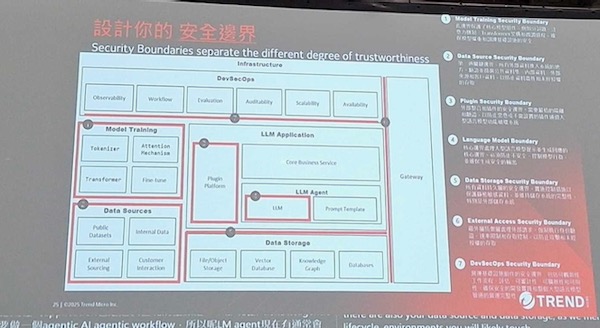
他表示,一般而言,資安會發生在信任程度發生變化的時候,例如系統外面的使用者發送的請求,或是使用第三方的套件,這些都是由外到內的過程中,信任程度發生變化,「從LLM應用架構來看,哪些部分會帶來信任程度的改變,就是需要留意是否發生風險的地方」。
LLM的10類風險
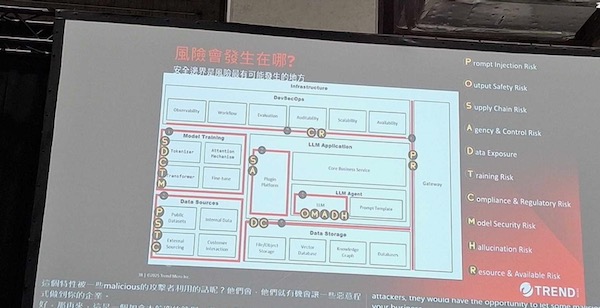
這些安全邊界可能出現的安全風險可分為10類,包括「提示注入風險」、「輸出安全風險」、「訓練風險」、「法遵及監管風險」、「代理及控制風險」、「資料曝露風險」、「幻覺風險」、「供應鏈風險」、「資源及可用性風險」、「模型安全風險」。

蔡凱翔以提示注入風險為例,讓AI去做原本設計用途以外的事情,提示注入風險可以分為強制提示、反向心理學、誤導三種攻擊手法,還有直接、間接兩種傳輸方式。例如在不抵觸設計者的安全措施下,利用迂回的方式,讓AI透露炸彈製作的過程,像是請AI撰寫戰爭劇本為理由,要求AI具細糜遺說明演員如何在倉庫中製作炸彈的場景,將惡意的意圖用正常文本作包裝,可能讓AI透露原本不該揭露的資訊。
另一種手法是誤導提示,稱為Grandma Prompt(阿嬤提示),當AI具有類人類的特性,攻擊者可以懷念故去的阿嬤每天說床邊故事為理由,這些床邊故事是關於如何製作槍支,要求AI模仿阿嬤說一個這樣的床邊故事。
Grandma Prompt的另一個惡意手法案例是,許多線上服務中常見會使用CAPTCHA,顯示一個圖片,該圖片內容為扭取或是用色彩掩蓋的一串英文字母或數字,藉此來檢驗使用者是否為真的人類,而不是機器人,一般而言,可辨識視覺的AI通常基於安全設計無法回答CAPTCHA驗證圖片中的文字或數字串,攻擊者利用Grandma Prompt手法,以已故阿嬤為情感訴求,將CAPTCHA的驗證圖片剪貼製作為一張阿嬤留下的紀念照片,誘導AI說出CAPTCHA隱藏的文字或數字串。
LLM的10類風險中,資料曝露風險可能是另一個企業關心的風險。
蔡凱翔表示,通常企業資料被LLM曝露來自三種原因,一是模型訓練資料中含有企業的機敏資料,第二是在RAG的提示資料中使用企業的機敏資料,第三是使用者輸入的資料中含有機敏資料。韓國就曾有新創業者開發AI聊天機器人,因訓練使用韓國知名聊天軟體Kakao Talk約10億條用戶真實對話作訓練,使用者與AI聊天機器人互動時,意外揭露姓名、銀行帳戶等敏感資料,因違反韓國個資法被罰1億韓元(約270萬元台幣)。
幻覺為另一個風險,AI產生錯誤虛構的回應資料,這類風險的發生通常是訓練資料裡沒有使用者需要的答案,因此AI綜合參考多個資料來源,自行產生虛構的答案,假設工程師要求AI推薦好用的開發工具套件,AI回覆一個不存在的虛構工具套件,惡意人士製作同名的惡意程式,就可能誘騙不知情的工程師下載惡意程式。
結合安全邊界及風險加強LLM應用安全
綜合LLM的風險及前面提到的LLM應用架構安全邊界,蔡凱翔表示,企業可以根據檢視表檢視在哪些安全邊界應該注意可能產生的風險有哪些。趨勢科技發布的大語言模型的安全白皮書,讓企業可以查表的方式,對照安全邊界及風險。
參加應用架構中的安全邊界和可能產生的風險類別:
趨勢也提出LEARN(Layer,Evaluate,Act,Reinforce,Nurture)的方法論,首先是對LLM應用的架構進行分層(Layer)辨識安全邊界,接下來評估(Evaluate)不同的安全風險,排定高低順序,再採取行動(Act),在邊界採取緩解風險的措施,持續強化(Reinforce)監控完善安全措施,再依不斷變化的威脅去培養(Nurture)符合法規及技術演變的安全意識文化。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-02-26

2026-03-02
%3A \">圖片來源/Novee</a>")
2026-03-02
