
在Stability AI即將公開預覽的Stable Diffusion 3(SD3)之際,官方先解釋了SD3的技術細節。SD3採用專為多模態設計的MMDiT架構,能夠良好地處理圖像和文字Token資訊,使得模型整體理解和排版能力都獲得提升。SD3在基準測試上,包括提示詞遵循、排版和視覺美感,皆優於目前最先進的文字轉圖像模型。
文字轉圖像生成過程,模型需要同時考慮文字和圖像兩種模態,而SD3所採用的MMDiT新架構(下圖),便是針對多模態資料設計。與過去Stable Diffusion的版本類似,開發團隊使用預訓練模型得出適當的文字和圖樣表示,更具體的說,SD3使用兩個CLIP模型和一個T5模型來編碼文字表示,並使用一個自動編碼模型來編碼圖像Token。
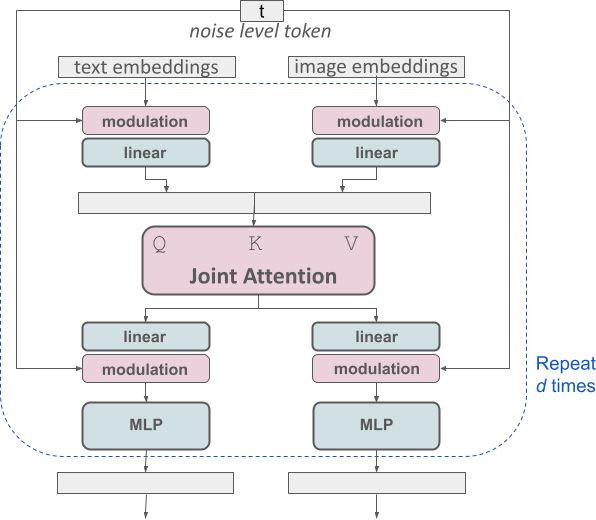
SD3所使用的MMDiT架構建立在Diffusion Transformer(DiT)的基礎之上。值得一提的是,DiT是OpenAI影片生成模型Sora的共同研究領導人William Peebles,在2023年於ICCV所發表的論文內容,同時也是Sora之所以能夠在影片生成上有重大突破的原因,DiT結合了擴散模型和Transformer的優點。
Stability AI指出,文字和圖像嵌入在概念上完全不同,因此他們對兩種模態使用兩組獨立的權重,也就是說每種模態都有兩個獨立的Transformer,只不過在運作上,是將兩種模態的序列連接起來執行注意力操作,這樣兩種表示便能在自己的空間中運作,而又同時可以考慮另一種表示。
藉由這種方法,資訊可以在圖像和文字Token間流動,以提高圖像輸出的品質,開發團隊還提到,這種架構也可以擴展至影片等多種模態。由於SD3改進了提示詞遵循能力,因此模型能夠根據用戶的具體要求,創建各種不同主題和特徵的圖像,同時還可保持圖像風格的靈活度。
SD3使用了一種稱為校正流(Rectified Flow)的公式來改善圖片品質,校正流公式會在模型學習時,把資料和雜訊以線性軌跡連接,在較直的推理路徑中生成更加清晰的圖片,並且還可減少完成的步驟。也就是讓模型在訓練的時候,透過逐漸將雜訊添加到資訊中,模型便能夠學習從具有雜訊的圖像中,恢復出原始乾淨的圖像,這讓模型學會更好的處理圖像,去除不需要的雜訊,最終生成更真實的圖像。
另外,開發團隊還在SD3訓練過程,採用了新的軌跡採樣排程,在軌跡中段給予更多的加權,使得SD3能夠更有效地生成圖像,特別是在較少採樣步驟的時候,這種改進可以協助模型在處理複雜圖像生成任務時,表現得更好。
針對SD3訓練所採用的新技術,包括使用重新分配加權的校正流公式,以及MMDiT架構主幹,Stability AI研究其對模型規模的影響,研究發現,無論是模型的大小還是訓練的時間增加,錯誤率都會逐漸減少,並使得模型效能持續上升。這代表Stability AI所採用的這些技術具有發展性,未來仍有改善模型的空間。
Stability AI在消費級硬體具有24GB VRAM的RTX 4090顯示卡上,運作80億參數的SD3模型,執行50個採樣步驟,總共花費34秒生成1024x1024的圖像。不過,Stability AI的SD3模型具有多種大小,從8億參數到80億參數都有,能夠符合不同硬體需求。
另外,SD3在處理文字採用了一個稍具規模的文字編碼器T5,擁有47億參數,這增加了模型運作需要的記憶體,在不使用T5編碼器的情況下可大幅減少記憶體,且造成很少的效能損失。雖然移除對圖像美感沒有影響,但是會降低文字遵循度,也就是說,不使用T5時,生成的圖像和文字描述可能會有一些落差,部署模型的用戶可以權衡提示詞遵循度和記憶體的限制,靈活選擇是否要移除T5編碼器。

熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-02

2026-03-02