
波士頓大學打造一系列大型語言模型Platypus,透過LoRA模組合併和微調方法,來提高模型訓練效能。
波士頓大學
重點新聞(0811~0817)
波士頓大學 Platypus LLM
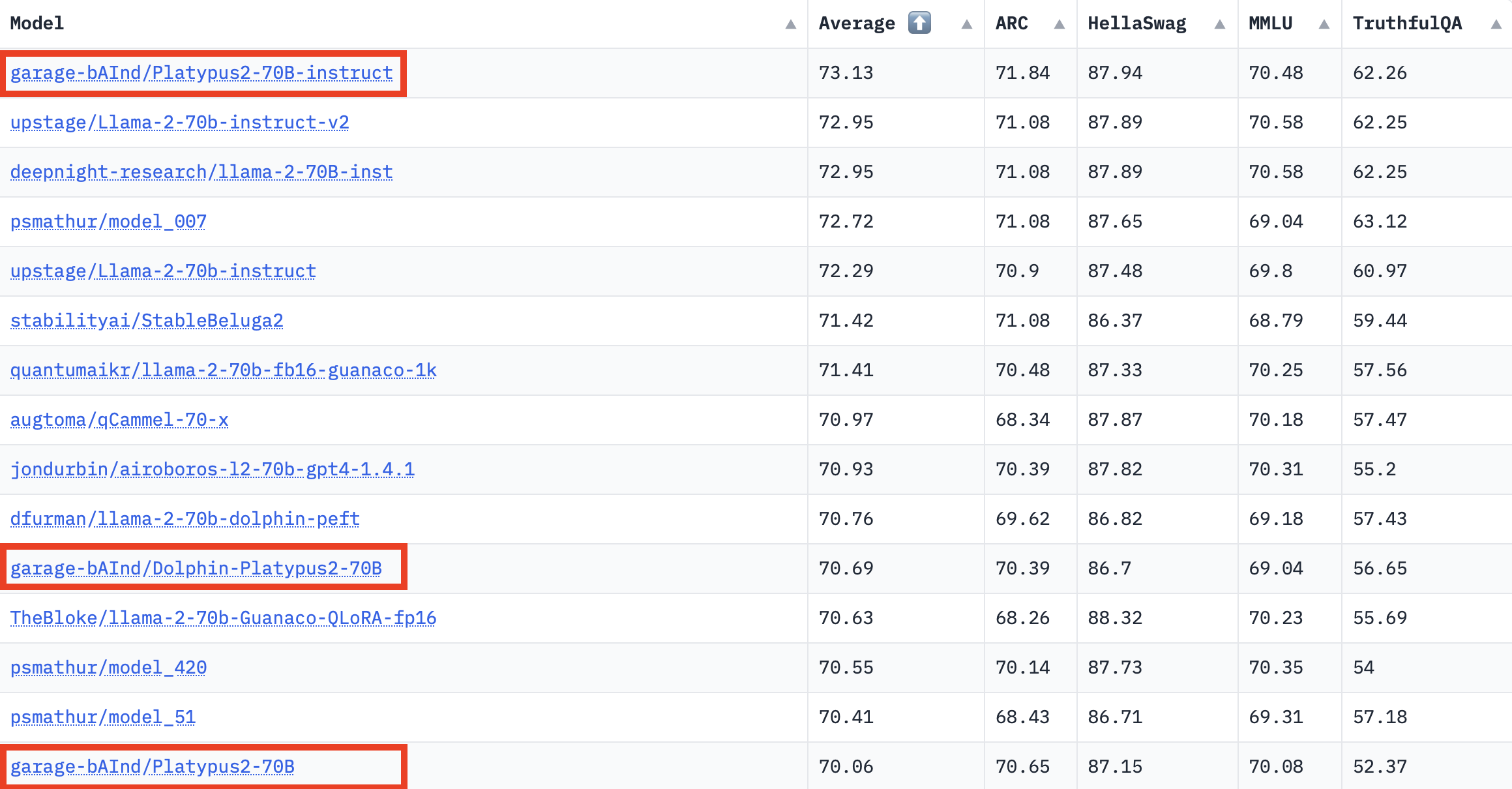
波士頓大學發布大型語言模型Platypus,占排行榜第一
最近,波士頓大學發布一系列大型語言模型(LLM)Platypus,包含不同參數版本。它們表現優異,在Hugging Face全球Open LLM排行榜上位居第一,所需的微調資料和訓練資源還不多。尤其,用單個A100 GPU、2萬5千個問題,就能在5小時內訓練出130億參數的Platypus模型。這是因為,Platypus採用自建的資料集Open-Platypus,該資料集是團隊從11個開放資料集中,特別編輯而成,著重改善LLM的STEM跨學科知識和邏輯能力。資料集中大部分問題為人工設計,只有10%是LLM生成,目前已開源。
完善資料集後,團隊在模型開發上著重2大方法:低秩近似(LoRA)訓練和參數有效微調(PEFT)函式庫。有別於完整的微調,LoRA保留了預訓練模型權重,整合了Transformer層的秩分解矩陣,進而降低可訓練參數,節省訓練時間和成本。經過一系列LoRA模塊的微調和組合,團隊發現模型訓練更有效率,所擁有的知識也更完整。另一方面,團隊也花不少心力把關資料集的污染和完整性,還設置一套驗證方法,來確保資料集的品質。(詳全文)
微軟 濫用 使用限制
9月底將正式上路!微軟頒布AI使用限制,將收集用戶對話防止濫用
為防止AI被用於侵權、傳播deepfake影片或惡意程式等行為,微軟9月30日將實行AI服務政策,防範使用者濫用或惡意使用AI服務,也將監控用戶的輸入和使用行為。微軟先是在7月30日公布新版微軟服務協議,新增5項AI服務相關規定,包含不得逆向工程、汲取資料、濫用AI服務的產出,以及用戶的法律責任等,這些規定預計9月30日正式實施。
進一步來說,微軟規定使用者不得以其AI服務來探詢其底層元件,包括模型、演算法和系統,他們也不得判斷或改變模型的權重。此外,除特別准許,使用者不能用網頁爬蟲、網頁抓取或網頁資料擷取手法,從AI服務取得資料。微軟還禁止用戶利用AI服務或其產生的資料,來訓練、打造或改進其他AI服務。微軟還強調,未來將處理、儲存用戶輸入的提示和其產出,以監控和防範濫用。,若用戶使用微軟的AI服務,結果導致第三方單位追究,如侵害版權或其他與內容有關的責任,一律由用戶負起所有法律責任。(詳全文)
OpenAI GPT-4 內容審查
OpenAI用GPT-4來加速內容審查工作
OpenAI宣布大型語言模型GPT-4又有新用途,可協助社群網站或論壇管理員審查平臺上的大量內容,將內容審查政策更新周期從幾個月,縮短為幾小時,來減輕人力負擔、降低對審查員的心理傷害。社群平臺常態性的網頁內容仲裁和審查工作,大都仰賴人力檢視大量內容,不但慢,還對人類審查員造成心理壓力或傷害。為此,OpenAI展開研究,要用LLM解決上述挑戰。他們測試發現,用GPT-4於內容管理系統,有幾大優點,包括可加速審查政策的更新,且GPT-4能解讀冗長政策文件中的規則,甚至是不同規則間細微的差異,並立即套用到政策更新,使其標註更為一致化。
OpenAI也分享實作方法,平臺管理員可先撰寫出政策指引,並以幾個範例、加上政策要求的標註,作為標準訓練資料集。再來是讓GPT-4讀取政策,來自動為資料集加標註(不看人類寫的正確答案)。第三步是讓GPT-4比較自己和人類的答案,政策專家可叫GPT-4說明它標註的理由,分析政策定義中模稜兩可的地方、釐清模糊不清之處,再建議更清楚的政策用語。最後,第2、3步驟可反覆執行,直到人類滿意為止。OpenAI指出,這種迭代流程可提升審查政策品質,以此設定分類器,可讓政策和內容審查作業擴大應用更多內容。(詳全文)

Google 程式開發 Project IDX
Google推出AI多平臺程式開發平臺Project IDX
為提升對開發人員的吸引力,Google發布可開發多平臺App的實驗性雲端整合開發環境計畫Project IDX,整合了Codey基礎模型和AI輔助程式撰寫等功能,讓開發人員打開瀏覽器就能開發程式。
Google這幾年推出不少多平臺App開發平臺,如Angular、Flutter、雲端Google Colab、Firebase,但他們認為,整個多平臺App開發流程得要更順暢、更快才行,因此在幾個月前啟動Project IDX實驗。Project IDX是在Google雲平臺上打造的Web開發服務,打開瀏覽器就能用。Project IDX目的是簡化開發、管理及部署完整堆疊的Web與多平臺應用程式,且具備熱門框架及支援多種語言(如JavaScript、Dart),也提供AI輔助開發與預覽、發布工具。Google指出,Project IDX也可以微軟Code OSS為開發底層,就算是習慣微軟工具的開發者,也能快速上手。(詳全文)

AI開發 Llama 2 IBM
IBM在自家AI開發平臺提供Meta的Llama 2模型
IBM宣布在AI開發平臺Watsonx.AI提供Llama 2模型,讓企業用戶能簡單取用Llama 2模型,訓練為專屬模型、開發自家AI應用。Watsonx.AI是Watsonx平臺的一部分,可讓企業簡單地訓練、驗證、調校和部署AI模型,該平臺包括預先打包的人工智慧模型目錄,還有可用於模型訓練的資料集。
而Llama 2是Meta在7月對外釋出的大型語言模型,IBM在Watsonx.AI中提供該模型,是延續過去與Meta在多個開源專案合作的基礎。IBM指出,他們目前的AI戰略是向用戶提供第三方和自家的模型。因此,在Watsonx.AI中,用戶可以使用到IBM和Hugging Face社群的模型,解決各種自然語言處理任務。接下來,IBM還計畫發布AI Tuning Studio,並在生成式智慧工具整合FactSheets資料治理服務。(詳全文)
Amazon 線上購物 摘要
Amazon用生成式AI摘要線上購物商品評論
Amazon指出,光是2022年,就有1.25億名顧客在線上商店貢獻15億條評論和評分,相當於每秒就有45條評論。於是,Amazon打造一套AI工具,可摘要線上購物商品評論,來產生評論亮點,在產品資訊頁面提供簡短說明文字,突出顯示顧客評論中最常提及的產品功能和情緒。
其中,評論亮點功能會先在Amazon美國行動購物上線。此外,Amazon也指出,他們用機器學習模型分析了帳戶關聯、登入活動、評論歷史和各種異常行為,來阻擋虛假評論,專業調查員也會用複雜的詐欺偵測工具,來避免商店出現虛假評論。(詳全文)
Line LLM 生成式AI
Line日本開源自有大型語言模型
日前,Line日本總部開源一套日語大型語言模型japanese-large-lm,以Apache License 2.0授權開源,包含36億及17億個參數2個版本,允許商業用途,兩項專案都可以在HuggingFace Hub存取。
Line自2020年11月起,就專注開發大型語言模型HyperCLOVA,還啟動多項應用計畫。Line在2021年5月開發者大會上,首次公開2,040億參數訓練而成的韓文版LLM HyperCLOVA,11月則公布日語特化版,擁有850億參數,並宣稱將以其發展一系列自然語言處理服務。這次開源的japanese-large-lm模型由Massive LM團隊開發,團隊指出,本模型是用了Line自己的日語大型Web文本為基礎來訓練,並利用成員自行開發的HojiChar開源函式庫,來過濾大量原始碼及非日語文字等雜訊,最後用了650GB資料集來訓練。(詳全文)
GPTBot 網路爬蟲 封鎖
OpenAI開源網路爬蟲工具GPTBot,網管可禁止抓取
OpenAI日前開源一款網路爬蟲工具GPTBot,可自動抓取網路上公開的大量資料,用來訓練下一代大型語言模型、提高精準度。OpenAI開發這套工具的原因,是要解決從公開網站上擷取資料的隱私與智財權爭議,也因此,該工具能過濾刪除需要付費的網站,不抓取這些網站內容,但還是可能抓到能辨識身份的資訊,或違反OpenAI政策的內容。
因此,OpenAI指出,網站管理員也可禁止GPTBot存取內容,比如在網站robots.txt檔案中加入GPTBot,或是自訂GPTBot存取網站部分內容。此外,OpenAI也公布GPTBot使用的IP位址範圍,方便網站辨識與封鎖。(詳全文)
圖片來源/波士頓大學、OpenAI、Google、Amazon
AI近期新聞
1. Google再測試生成式AI,讓Chrome協助使用者摘錄重點
2. Stability AI推出自家程式碼生成模型StableCode
3. 資料科學家愛用程式語言Julia首進TIOBE Index前20名
資料來源:iThome整理,2023年8月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02