
OpenAI共同創辦人Greg Brockman展示輸入一張手繪的設計草圖,GPT-4就能自動生成對應網頁的程式碼,幾乎和手繪草圖一樣,他強調,這會大大改變網站設計模式
OpenAI正式推出了GPT-4模型,最大特色是不只文字對話還能輸入圖片,讓AI來解讀,而且解答能力和正確率大幅超越了GPT-3.5,也更能控制GPT輸出人設來符合企業想要的的形象,輸入Token數量也將大幅增加到32,768個,相當於50頁文字。目前先開放了文字輸入API功能,ChatGPT Plus付費用戶可優先排入試用新版。圖片輸入功能目前則只開放給特定合作夥伴。
GPT-4是一個多模態AI超大模型,可接受圖片和文字輸入,來生成文字的回覆,可以提供人類等級的回答內容。根據OpenAI實測,在全美統一律師資格考檢定上,3.5只能拿到倒數10%的名次,但GPT-4卻能拿到前10%的高分。或像是在SAT數學測驗或GRE測驗等三十多項不同學科的主流檢定測驗上,GPT-4都大勝3.5版。
Open AI花了6個月時間,利用ChatGPT和其他多項對抗式測試計畫來調整,終於打造出答案更真實、更可操控和更能防範濫用的新一代GPT-4。
雖然GPT-4和3.5版的訓練資料同樣都只使用到2021年9月為止的開放網路資料,但是4.0再多項傳統機器學習能力評比上,都超越了3.5版,甚至多項都達到SOTA等級。甚至在1,4000題多選題測試的MMLU(理解力)評比上,OpenAI宣稱,GPT-4英文答題的正確率達到80.5%,高於3.5版的70.1%,甚至也高於Google日前的PaLM模型英文答題的69.3%正確率,不過,PaLM答題正確率是OpenAI自行實測的結果,而非Google官方數據。值得注意的是,GPT-4對翻譯成中文版的MMLU答題正確率也達到了80.1%,日語和韓語版也都有70~80%的正確率。
不只是文字模型也是視覺模型,可同時輸入圖片和文字而生成文字解釋
除了答題能力更正確之外,第4版最大特色是能看圖,而且可以同時輸入指定圖片和圖片,GPT-4會以文字來解釋圖片內容,並且符合文字任務的要求。輸入的圖片可以是照片、圖表或螢幕解圖。未來,GPT-4還將持續強化解圖能力,例如可以輸入多組圖片範例,或是提供分解動作解釋的解圖(chain-of-thought)能力。
根據OpenAI使用多項標準學術視覺模型能力評比來實測,GPT-4解圖能力在不同評比的結果落差很大,在圖表或圖片問答評比如ChatQA、InfographicVQA、DocVQA達到SOTA程度,但也有些評比如VQAv2、LSMDC等還有不小的落差。目前圖片輸入功能還處於研究者預覽版本,沒有對外開放,OpenAI也沒有透露可能的開放時程。
另一個值得注意的新版特色是操控性(Steerability),可以透過人設指定,例如回答的用語、風格、語調等條件,來限制GPT-4的回覆行為。例如在API中透過system角色,要求GPT-4扮演不能直接回答答案的的數學課輔老師,在展示範例中,不管,學生怎麼問,或者試圖透過特殊指令試圖越獄,也都無法得到直接的答案。這個新功能可用來限制和控制GPT-4所能回答的限制,可供企業用來設定想要GPT-4回答的內容範圍,或者禁止回答的內容。
為了防範AI模型遭到濫用,OpenAI在GPT-4模型中也特別針對AI濫用或不當使用進行強化,目前實測上,gpt-3.5-turbo對敏感指令(例如違反倫理的指令)的攔截失誤率超過40%,但GPT-4可以降低到20%出頭,等於5次會誤判一次,或不良行為指令的阻擋失誤率更不到5%(例如犯罪行為教學等),例如禁止生成色情或犯罪相關的內容。
Token數量增加8倍,最多可輸入32768個,等於2萬多字中文
在GPT-4的API中另一個企業用戶在乎的新功能是輸入Token的上限,最大放寬到32K,比GPT-3.5的4k,多了8倍,達到32,768個Token之多。以每千次中文約700個Token來估算,32k的Token等於可以輸入超過2萬字中文的內容。不過,目前開放的GPT-4版本只提供8K版本,也就是比原本3.5多了一倍,達到8,192個Token,32K版引擎目前先開放特定對象試用。目前GPT-4效能也只達到每分鐘處理40K個Token或每分鐘200次呼叫的能力,OpenAI表示,正在持續優化中。
OpenAI共同創辦人Greg Brockman透過直播展示GPT-4最新特色
GPT-4如何解讀圖片的6大示範
示範1:可以用來解釋組合圖中各自小圖的重點

示範2:可以用來解讀圖表內容

示範3:可以看圖回答問題

示範4:可以看圖找出圖中異常之處

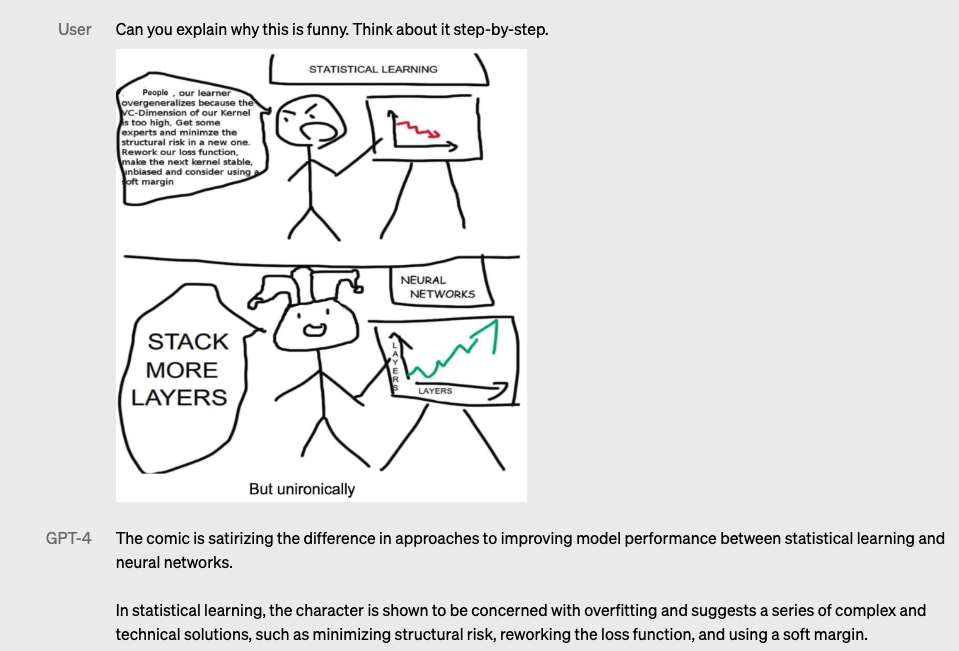
示範5:可以解圖迷因圖片(以人類幽默感口吻來解讀)

示範6:可以分解解讀漫畫的重點
熱門新聞

2026-03-13

2025-06-02

2026-03-14

2026-03-13

2026-03-13

2026-03-13

2025-04-15
2026-03-16