
Salesforce設計一款演算法,可逆推擴散模型處理過程,進而能生成貼近原圖的編輯圖像。
Salesforce
重點新聞(0113~0119)
Salesforce 擴散模型 文字轉圖像
Salesforce新演算法可逆推擴散生成模型,改字也能準確貼近原始圖
Salesforce最近設計一款新演算法EDICT,可逆推任何文字轉圖像的擴散模型,就算原始文字提示有所修改,新生成的圖像依然貼近原圖,比如使用者將文字提示「站在衝浪板上、穿著救生衣的狗」中的狗改為貓,新生成的圖片能保留原圖樣貌,只將狗轉換為貓。
團隊表示,EDICT之所以能這麼做,是因為追蹤了一對中間表徵,而非只是一個。這種可逆性,讓模型產出非常貼近原圖的編輯圖像。Salesforce也把這套演算法用於熱門的Stable Diffusion模型,發現演算法能高保真重建出原始圖像。 而且,團隊以MS-COCO這類複雜的圖像資料集測試發現,EDICT的圖像重建表現,比降噪擴散隱性模型要好。
團隊表示,EDICT不需要訓型訓練或微調,也不需要額外的訓練資料,而且能與任何預訓練降噪擴散模型整合。EDICT程式碼已在GitHub上公布。(詳全文)

文字轉影片 稀疏因果 Tune-A-Video
新加坡國立大學打造文字轉影片模型Tune-A-Video省資源
新加坡國立大學以單樣本學習,打造一款文字轉影片AI模型Tune-A-Video,來降低訓練所需的運算成本。團隊指出,近來,文字轉影片這類生成式AI的主流研究方法,仰賴大規模成對的「文字-影片」資料集來微調。然而,這種方法耗費大量運算資源,也不直覺,於是團隊提出Tune-A-Video,來以單一組「文字-影像」訓練開放領域的影片生成器。
團隊以經過海量資料訓練的文字轉圖像預訓練擴散模型為基礎,來開發文字轉影片模型。他們也發現,文字轉圖像模型能針對動詞,產出相對應的圖像,而且,用這些模型來同時生成多張圖像,其生成內容的一致性非常高。
因此,為進一步讓模型學習連續性動作,團隊提出一種稀疏因果注意力機制,能透過單樣本微調預訓練擴散模型,來根據文字提示產生影片。團隊表示,Tune-A-Video可用來產生吻合時序的影片,可用於背景或主題變換、屬性編輯、風格轉換等。(詳全文)

ChatGPT DoNotPay 服務條款
美新創用ChatGPT讀服務條款,不只能白話解釋還會揪出不合理之處
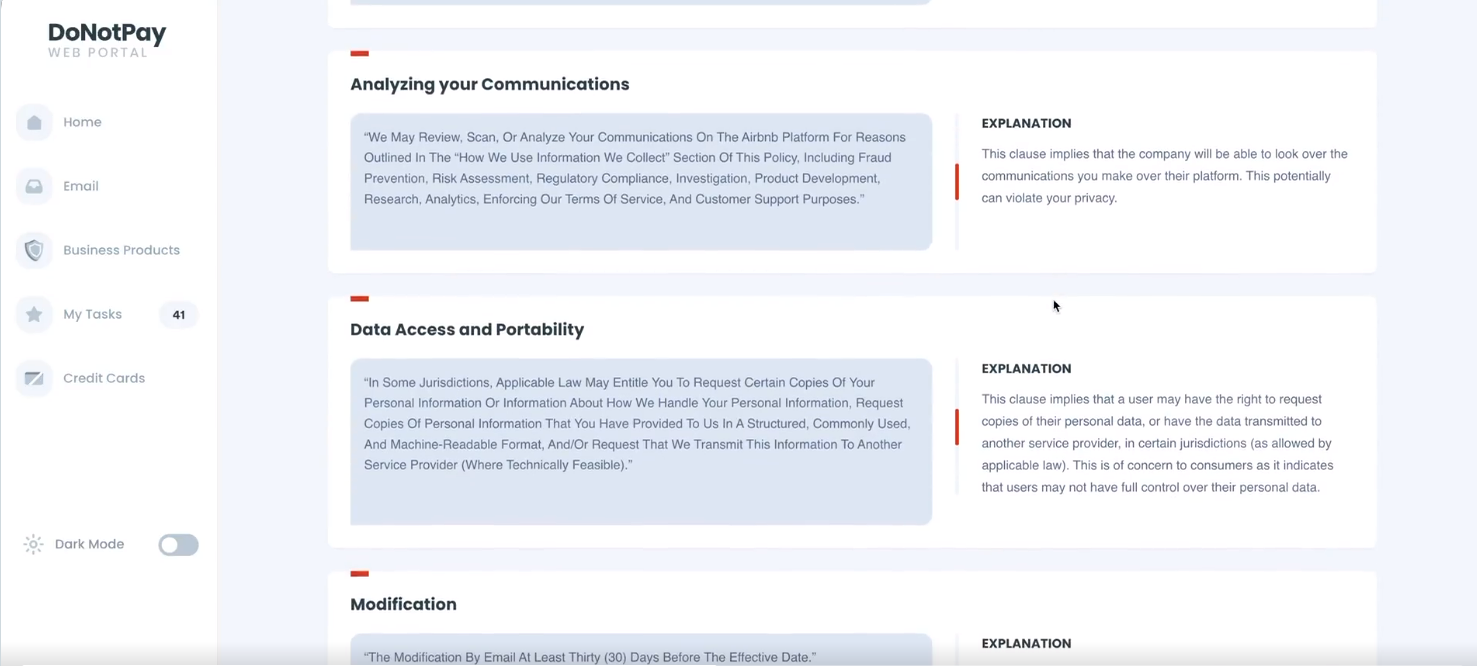
生成式AI又有新應用!致力以AI維護消費者權益的美國新創DoNotPay執行長Joshua Browder最近展示一款外掛,該外掛基於ChatGPT,使用者在DoNotPay平臺服務DoNotSign上上傳服務條款PDF或輸入網址,系統就會自動閱讀內容、產出白話解釋,若有不合常規的條款,系統還會自動標註,來告知使用者。除了服務條款,該系統還能處理隱私條款、租賃合約等法律相關文件。Joshua Browder指出,該功能將是首款供大眾使用的GPT系列產品,因此可能受到OpenAI的API限制。目前,該功能正在審核中,還未正式上線。
這不是第一個DoNotPay發表的AI應用。日前,Joshua Browder展示一款基於GPT-3.5的語音代理系統,能利用使用者聲音,來與客服自動對話,另一款則是基於GPT-3 API的聊天機器人,能與客服文字對話,解決訂閱、續約、付費問題。(詳全文)
微軟 Azure OpenAI GPT-3
微軟Azure OpenAI服務正式上線,企業可用GPT-3、Codex和DALL-E 2了
微軟日前宣布Azure OpenAI服務正式上架,更多企業用戶可申請使用OpenAI的AI模型了,如GPT-3、Codex和DALL-E 2。微軟還預告,Azure OpenAI服務還會納入ChatGPT模型。
Azure OpenAI服務由微軟在2021年推出,可讓企業在安全、合規的條件下,從Azure雲平臺取用OpenAI預訓練模型。這些模型包括具1,750億個參數的自然語言預訓練模型GPT-3、GPT-3的升級版GPT-3.5,以及可將自然語言轉為程式碼的模型Codex,還有文字轉圖像模型DALL-E 2。使用者可透過Azure OpenAI來開發各種應用程式,如從客服日誌快速總結客訴、快速編寫程式,或快速生成部落格文章等。Azure OpenAI服務提供的模型已由數十億頁公開文件訓練,企業只需提供自家少量業務資料,就能進一步微調模型。為確保AI合理使用,微軟也要求開發者先申請存取權限,事先描述預期用例和應用程式。微軟的監控程式也會持續過濾Azure OpenAI服務可能產生的辱罵、仇恨和冒犯性內容,當官方確認用戶用例違反政策,便會限制使用。(詳全文)

空中巴士 自駕技術 客機
參考蜻蜓視覺能力,空中巴士開發客機自駕技術
空中巴士(Airbus)以蜻蜓為靈感,開發自動飛行技術,Airbus UpNext DragonFly展示飛機已進入最後3個月的測試階段,來測試飛行路徑選擇能力、自動降落技術和駕駛員輔助技術。空中巴士計畫將DragonFly技術用於緊急操作上,當機組人員無法控制飛機時,DragonFly會將飛機重新導航至最近的機場,並安全著陸。
這款DragonFly模仿蜻蜓超廣視野和辨識地標能力,來讓飛機辨識地景特徵和周圍環境,並安全操縱飛機。DragonFly系統也參考蜻蜓敏銳的視覺能力,整合感測器、電腦視覺演算法和導航運算功能,可在低能見度和惡劣天氣情況下降落,這項新的降落技術,甚至可以根據飛行員的飛行技巧自訂,減輕飛行員在緊急情況的額外程序。(詳全文)

語音合成 Eleven Labs 語音特徵
生成式AI新進展!Eleven Labs揭露最新語音合成成果
專注語音合成AI的研究實驗室Eleven Labs日前發布最新語音生成模型,使用者能根據性別、年齡、口音、音高,甚至是說話風格等特徵,來生成全新的人造聲音,而且系統每次合成的聲音都不一樣,即使用戶以相同參數生成聲音,也會得到一個不曾存在的聲音。
近來,生成式AI大放異彩,在文字、圖像甚至是影片領域遍地開花,但語音生成並非如此。因此,Eleven Labs參考語音合成和語音複製的語音特徵編碼方法,在訓練專屬模型時,對說話者嵌入分布進行採樣,來合成無限多種的新聲音。他們也在這過程加入一定程度的限制,讓聲音擁有特定的語音特徵。Eleven Labs打算把這個模型發展為「Design Voice」功能,預計在2月於自家平臺上線。團隊表示,該模型可用於新聞媒體和商業廣告的語音,甚至能用於遊戲開發。(詳全文)
Nvidia 零售業 防盜竊
Nvidia推新AI工具,防零售業商品被盜竊
Nvidia推出3款零售業專用AI工作流程Retail AI Workflows,可用來打造商品防竊盜應用。進一步來說,這些工作流程以Nvidia自家微服務平臺Metropolis為基礎,Nvidia先以常遭竊的商品圖片和軟體來訓練這些工作流程,開發者再以無程式碼或低程式碼模組來快速開發應用程式。
第一款工作流程是零售業防損AI工作流程,其中的AI預訓練模型,能辨識上百種最常受盜竊損害的產品,如肉類、酒品和洗衣粉,模型也能識別產品不同的尺寸、容量和形狀。此外,使用者還能用Nvidia Omniverse平臺合成資料,來客製化模型,以業者自家的數十萬種商品來訓練。
另一種是多攝影機追蹤AI工作流程,具多物件、跨多攝影機功能,讓開發者更容易打造跨全店多攝影機的系統,來追蹤商品物件。最後一個流程是零售商店分析工作流程,能以電腦視覺技術,在客製化的儀表板上呈現商店分析洞察,如商店客流量趨勢、使用購物籃的顧客人數、走道占用率等資訊。(詳全文)
假消息 大型語音模型 輿論操縱
OpenAI:大型語言模型加重輿論操縱
OpenAI聯手史丹佛大學和喬治城大學,展開大型語言模型(LLM)對輿論風向操縱的研究,他們發現,大型語言模型會導致更多惡意傳播行為,且形式更多元,行為成本也更低。
近年,生成式AI有顯著進展,但也容易遭惡意人士濫用。於是,3大機構聯手,以ABC模型來探討輿論操縱影響,其中A代表行為人,也就是輿論操縱行為背後的實體,B代表輿論操縱行為,C則指操縱內容。研究發現,在A方面,未來將因為生成模型普及而降低宣傳成本,出現更多樣的宣傳群體;而B則會出現自動生成內容規模擴大,同時也更有效率,如即時生成個人化內容,且生成內容更可信也更有說服力。團隊表示,語言模型對輿論風向操縱有重大影響,但目前沒有終極解決方案,有能力開發大型AI的科技龍頭和社群媒體,應共同應對輿論操縱。(詳全文)
圖片來源/Salesforce、新加坡國立大學、DoNotPay、微軟、空中巴士
AI近期新聞
1. 新AI工具GPTZeroX可偵測文章是否出自ChatGPT
2. 線上會議認真神器!Nvidia Broadcast以AI模擬用戶眼睛緊盯鏡頭
資料來源:iThome整理,2023年1月
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10