PyTorch基金會預計在2023年3月,將正式推出PyTorch 2.0,現在釋出開發早期版本供開發者測試,這個新版本從根本改進PyTorch編譯器的運作方式,對Dynamic Shapes和分散式運算提供更高的效能和支援。
PyTorch 2.0加入torch.compile功能,官方提到,這除了能將PyTorch的效能推向另一個新高度之外,也是將PyTorch中C++的部分移回Python的重要更新,而這也是這個版本被稱為PyTorch 2.0的原因。
由於PyTorch 2.0完全向後相容,因此torch.compile定位是一個額外的可選功能,torch.compile底層是一系列新技術,包含了TorchDynamo、AOTAutograd、PrimTorch和TorchInductor。這幾個新功能都是由Python編寫,並支援Dynamic Shapes。Dynamic Shapes供用戶發送不同大小的張量,但是卻又不需要重新編譯。
為了驗證這些技術,PyTorch使用來自各領域163個開源模型建構測試基準,包括圖像分類、物件偵測、圖像生成等任務,還有各種NLP任務,如語言建模、問答、序列分類、推薦系統和增強學習。這涵蓋HuggingFace Transformers的46個模型、TIMM的61個模型以及TorchBench的56個模型。
開發團隊使用基準中的163個模型,測試torch.compile的加速與準確性,由於執行速度可能取決於資料類型,因此測量包括float32和自動混合精度(Automatic Mixed Precision,AMP),但有鑒於AMP更常被使用,因此計算方式以0.75*AMP+0.25*float32不平均加權來計算平均速度。
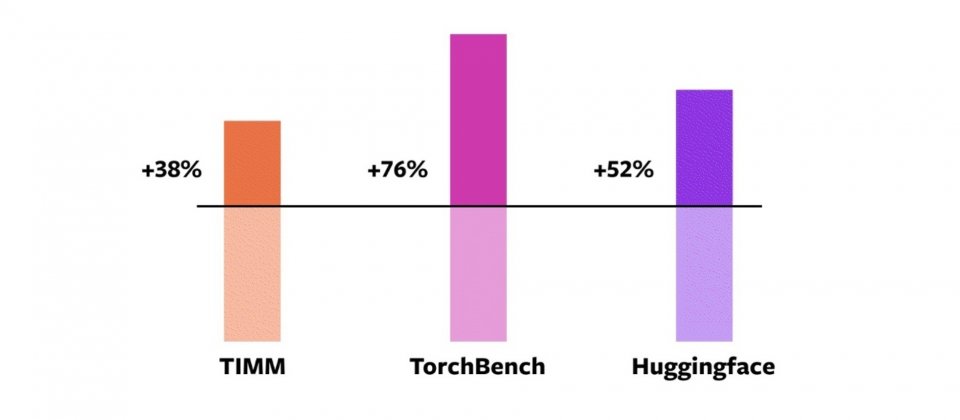
在163個開源模型中,93%模型能夠在torch.compile運作,在Nvidia A100 GPU上平均訓練速度提高43%,在使用Float32精度下,執行速度提高21%,而使用AMP精度則加速51%。對TIMM模型整體加速38%,HuggingFace模型加速52%,而TorchBench則有76%的加速。
torch.compile的預設後端TorchInductor,支援CPU和Nvidia Volta與Ampere GPU,目前還不支援其他GPU或是加速器,或是較舊的Nvidia GPU。torch.compile仍在開發早期階段,但用戶可以在Nightly版本先行試用。
熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09