
繼打造風靡AI圈的物件偵測模型YOLOv4、YOLOR後,中研院原班人馬近日釋出最新物件偵測器YOLOv7,不論是速度還是準確度,都優於現有卷積模型和Transformer類模型。
中研院
重點新聞(0701~0707)
本周有不少重量級開源模型出現,像是由中研院團隊開發、表現完勝現有物件偵測模型的YOLOv7,以及Meta打造、單一模型可翻譯200種語言的NNLB-200,還有哥倫比亞大學仿DeepMind蛋白質折疊預測模型AlphaFold、用PyTorch開發的OpenFold,表現甚至比AlphaFold 2要好一些。而PyTorch這個開源機器學習框架,最近也釋出最新的1.12版,新增許多加速API。產業方面,H&M聯手Google雲端要打造核心數據平臺,FIFA則要引進最新影像辨識技術作為越位裁判輔助。
YOLOv7 即時物件偵測 中研院
中研院即時物件偵測新模型YOLOv7問世,表現碾壓YOLO系列和Transformer物件偵測模型
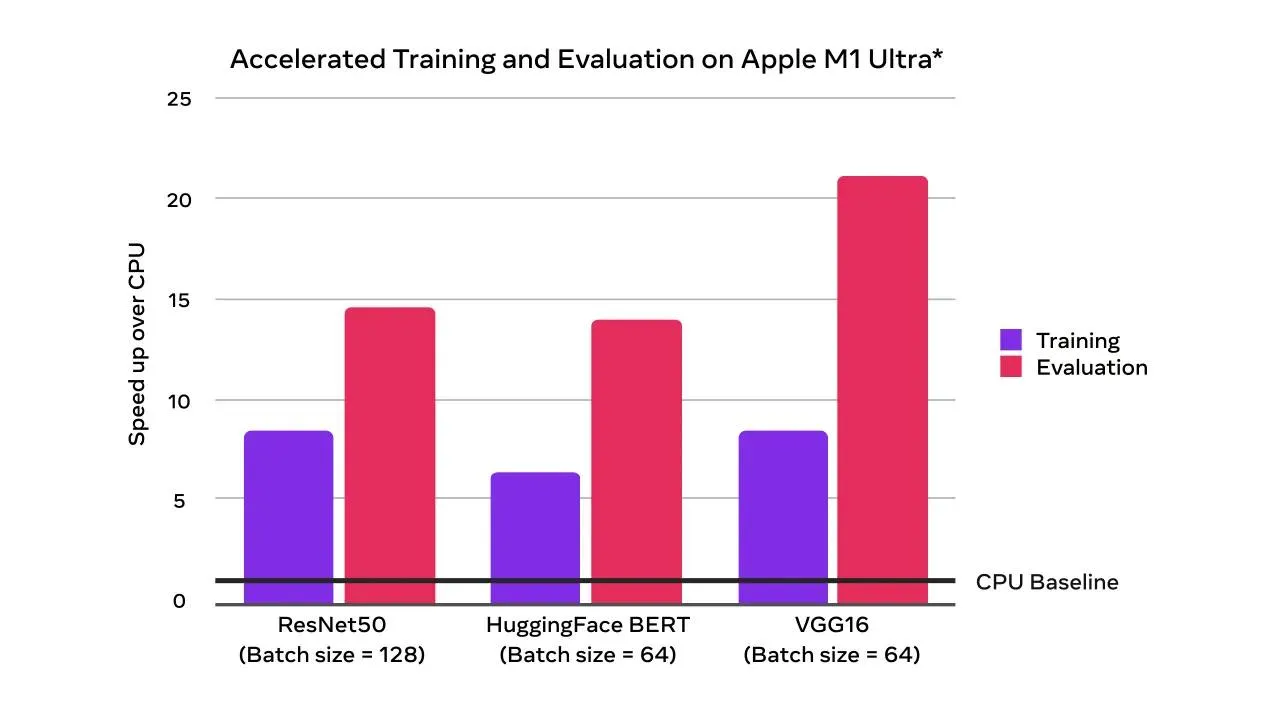
打造轟動AI圈的物件偵測模型YOLOv4和YOLOR還不夠,本周,中研院原班人馬釋出新一代即時物件偵測器YOLOv7,不論是速度還是準確度,在每秒5幀到每秒160幀範圍內,表現都優於現有所有物件偵測模型,像是YOLO系列模型和Transformer模型。而且,在使用GPU V100、每秒30幀或更多的條件下,YOLOv7平均精度達到56.8%,是所有物件偵測器中,準確度最高的模型。
進一步來說,YOLOv7由中研院資訊所所長廖弘源、博士後研究生王建堯和YOLO網路維護者Alexey Bochkovskiy共同開發,這款物件偵測器的表現,超越目前電腦視覺界主流的網路架構,如卷積網路(CNN)和Transformer架構。在使用GPU V100、每秒56幀的條件下,YOLOv7-E6速度比Transformer類的SWIN-L Cascade-Mask R-CNN快上5倍多、準確度高2%,也比卷積網路類的ConvNeXt-XL Cascade-Mask R-CNN快上5.5倍、平均精度高出0.7%。
此外,YOLOv7的速度和準確度,也比其他熱門物件偵測模型要好,包括YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5,以及Transformer類的DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B及許多物件偵測模型。團隊補充,他們只用微軟COCO資料集從零訓練模型,並未使用其他資料集或預訓練模型的權重。YOLOv7目前已於GitHub上開源,開發者可下載。(詳全文)

Meta 語言模型 翻譯
Meta最新翻譯模型可一次翻譯200種語言,未來要用於臉書、IG內百億則內容
Meta最近開源一套翻譯模型NLLB-200,單一模型就可一次翻譯200種語言,包括熱門語言和沒有豐富資料的非洲少數語言。這個模型,是源於Meta的絕不拋下任何語言專案(NLLB),將為10億多人提供翻譯內容。
Meta表示,NLLB-200成果將支援Facebook動態消息、Instagram及其他平臺上高達250億則翻譯內容,使用者只要點擊一個按鈕,就能用自己熟悉的語言準確了解內容。Meta這次開源,釋出了NLLB-200模型、多對多評估資料集FLORES-200、模型訓練程式碼,還有用於重建訓練資料集的程式碼。(詳全文)

PyTorch API 資料前處理
PyTorch 1.12新版來了!新API加速批次資料前處理、優化Mac訓練效率
離上一版更新才幾個月,開源機器學習框架PyTorch近日釋出最新版本v1.12,包括一系列服務更新和除錯。其中的主打特色有Beta版的機器學習資料前處理函式庫TorchArrow,是一個高效能、簡單好用的API,用來加速資料前處理工作流程。另一個則是Beta版的模組函式API,可讓開發者完全控制模組運算中的參數,此外還有針對複數、複數算子提供的2個新功能,一個是複卷積的新功能,另一個是對Complex32資料類型的實驗性支援。不只如此,這次新版也針對Mac做出模型訓練加速的優化,並針對特Transformer編碼器模組,提供快速實作的功能。(詳全文)
史丹佛大學 GAN 3D影像
史丹佛大學打造超強GAN模型,可隨意生成3D逼真臉部和物件影像
史丹佛大學日前打造一套GAN模型EG3D,可隨機生成高清晰度的人臉影像,或其他具有基本幾何結構物件的影像。該模型是目前少數能產出近照片渲染等級品質的AI模型。
進一步來說,GAN的原理是,透過生成器產出與輸入值近似的圖片,再由鑑別器來判斷品質,如此反覆來提高生成品質。在EG3D中,研究員先整合目前現有的高解析度2D GAN特徵,打造成一個元件,來將平面影像轉換為3D影像,一次完成2個工作。此外,該模型還有高效運算的特色,幾乎能在筆電上,即時產出逼真、清晰的3D影像,甚至也能用來建立複雜的3D設計。(詳全文)

AlphaFold OpenFold 蛋白質折疊
哥大教授開源PyTorch版蛋白質折疊預測模型OpenFold
哥倫比亞大學教授Mohammed AlQuraishi用PyTorch打造一套蛋白質折疊預測模型OpenFold,是仿DeepMind的AlphaFold 2開發而成,表現比AlphaFold 2稍好。雖然業界有不少仿AlphaFold的開源模型出現,但OpenFold是唯一一個開源最完整且表現最好的模型。
蛋白質折疊實驗是發現新藥的關鍵步驟,也是困擾科學家數十年的難關,因為要準確預測,得花上大量時間和硬體成本。而AlphaFold打破這個瓶頸,在2020年的蛋白質結構預測CASP14競賽中拿下第一,所需時間最短、準確率也最高,為此後的蛋白質折疊研究開拓新路。
OpenFold完整仿照AlphaFold 2開發、開源,唯一的例外是模型整合(Model ensembling)並未納入,因為它在原本DeepMind的測試中就表現不佳,且逐步淘汰,因此未納入OpenFold中。根據開發者在GitHub說明,不論是否使用深度學習訓練加速函式庫DeepSeed,OpenFold都能以全精度或bfloat16來進行訓練,且表現與AlphaFold相當。(詳全文)

Google Nvidia MLPerf
Google、Nvidia並列MLPerf機器學習效能基準測試之冠
MLCommons最近公布最新機器學習基準測試結果,Nvidia和Google分別在4項測試項目中拿下第一。MLPerf Training是業界組織MLCommons定期舉辦的機器學習效能測試,也是業界知名的參考指標。這次公布MLPerf Training 2.0結果,其中包括8種AI推論應用任務類別,包括圖像分類、圖像分割、物件辨識light-heavy、物件辨識heavy-light、醫療影像、語言辨識、自然語言處理、推薦和強化學習。
其中,Google的TPU v4在自然語言處理、圖片分類和2項物件辨識等4種任務測試中拿下第一,而Nvidia是唯一一家完成所有8項目測試的廠商,使用A100 GPU及新的Jetson AGX Orin SoC,在6項測試中拿下第一。(詳全文)
H&M Google雲端 核心數據平臺
H&M要用各類數據發展AI!近日聯手Google要打造核心數據平臺
瑞典服裝品牌H&M宣布要打造一套企業級數據骨幹平臺,來發展AI營運管理應用。他們找來Google雲端,要利用Google的資源,開發核心數據平臺、數據產品和AI相關應用,並發展全新數據網格,來處理店內、線上購物、供應端和品牌生態系中的各類數據。
這個平臺的終極目標,是要改善H&M內部供應鏈和跨通路的消費者體驗。H&M技術長Alan Boehme表示,自家公司有著悠久的創新歷史,現在則要利用先進分析技術來加速H&M數位轉型,給消費者耳目一新的服務。(詳全文)
影像裁判 國際足球聯盟 影像辨識
幾秒就能通知裁判!世界盃將引入新影像裁判技術
國際足球聯盟FIFA日前發表一套由攝影機和感測器組成的越位裁判技術,將應用於今年底的卡達世界盃足球賽。這套方案由愛迪達和其他廠商合作,可提供足球場上更精準的越位(offside)判決。
該方案將使用12臺攝影機,架設在球場屋頂來追蹤足球位置,並蒐集場內每位球員身上的29個資料點,每秒蒐集50次。這些攝影機也搭配比賽用球Al Rihla,球的中心置有慣性測量單元感測器,可將球的資料以每秒500次的頻率,傳到VAR裁判組。這個新技術,將結合感測器和AI模型,在進攻方的前鋒處於越位位置時,自動對VAR裁判組自動發出警示,提供自動產生的越位畫面。VAR裁判組人工判斷確認越位後,就會通知場中裁判。所有過程可在幾秒內完成,FIFA表示這可使足球關鍵判決更快且更精準。(詳全文)
圖片來源/中研院、Meta、PyTorch、史丹佛大學、哥倫比亞大學、FIFA
AI近期新聞
1. Hugging Face新添評估工具Evaluation on the Hub,容易上手用任何資料集來評估各種模型
2. Reddit收購NLP廠商MeaningCloud
資料來源:iThome整理,2022年7月
熱門新聞

2026-01-12

2026-01-12

2026-01-12
2026-01-12

2026-01-12
