")
Atlassian也公開了這次當機事件中,動員數百名工程師和客服支援人員所用的大規模事件流程示意圖。日後計畫在災難復原計畫中,建立一個大宗客戶發生多網站、多產品刪除事件的自動化修復機制。(圖片來源/Atlassian)
在今年4月5日,Atlassian發生大當機事件,波及旗下Jira 產品系列、Confluence文件協作平臺、Atlassian Access登入機制、Opsgenie 事件應變服務,甚至是網站狀態查詢頁Statuspage,受影響企業家數達775家。造成四月大當機事故的起因不複雜,Atlassian也的確在事故發生後1個多小時,就釐清了根本原因,但是資料復原成了他們最大的考驗。
為了提供99.9%的可用性服務水準,這是雲端供應商常見的標準SLA承諾,Atlassian原本就有一套災難復原做法。但是,Atlassian坦言,過去的DR計畫主要聚焦在基礎架構失敗的復原,或是從備份資料中復原企業所用服務儲存空間的做法,而少了一個關鍵環境,就是以顧客專屬入口網站(網站ID)視角的復原計畫。換句話說,Atlassian的DR計畫是以自己工程維運角度來思考,而少了從顧客視角,從企業所用專屬網站的角度來設計復原機制。
舊有DR計畫有能力來因應基礎架構層級的失效情況,如整個資料庫失效、AP服務或AWS 可用區域遺失的復原,也可以因應勒索軟體事件、惡意程式、軟體缺失,甚至是因人為操作錯誤而導致的服務儲存資料損毀,都可以單獨將資料復原到30天內的任何時間點。換句話說,Atlassian的DR計畫涵蓋了基礎架構出錯、資料損毀、單一服務活動或單一網站的刪除。但是,在這起事故中,Atlassian遭遇到多網站、多產品的自動復原挑戰。在Atlassian的網站等級維運手冊中,沒有建立快速自動執行的腳本程式和程序,就得人工處理和協調跨所有產品和服務的復原工作。
可是,Atlassian的技術架構採取了分散式架構,不只在雲端基礎架構採取分散架構來提高可用性,在應用系統層次,也採取了多租戶微服架構設計來兼顧彈性和可用性。一位企業客戶的網站,不只會部署到單一資料庫或儲存空間,也會部署到分散式基礎架構中,可能涵蓋了多個實體位置與邏輯位置,來儲存中繼資料、配置資料、產品資料、平臺料或是其他有關相的網站資訊。這是為何需要一套高度自動化的PaaS部署和建置平臺的緣故。不過,要復原一整個網站,就得重建這個的高度自動化作業的過程,Atlassian因為因為沒有事先考慮到這個情況,就帶來了龐大的人工驗證的確認程序。
這正是為何在第一個復原方法中,需要高達70個步驟,因為建立新的網站、授權、雲端ID來啟用正確的產品清單後,還得將網站資料轉移到正確的AWS區域中,並且要復原和重新對應網站的核心中繼資料和配置、網站的身分識別資料,然後才能復原網站的主要產品資料庫,還要重新對應網站的相關媒體關聯、附件,也要重新對應網站所有服務的資料。甚至要復原和重新對應一個企業用戶網站所用到的每一個第三方應用程式,告訴第三方應用的供應商,新的網站ID與舊有網站ID之間的關聯,來取得合法串接授權。這中間有不少是因為新舊ID轉換而需要的確認和驗證,而這些都沒有事先完成的自動化腳本工具可用,得邊做邊人工處理。這正是為何第一個復原方法花上48小時的緣故。
後來改良後的第二個復原方法,放棄使用新網站ID,而直接沿用企業用戶遭刪除的舊網站ID,就少了許多需要驗證的動作,尤其,第三方應用的串接,不需要再次確認就能繼續使用,再加上後來完成了自動化復原工具和驗證工具,才把復原時間縮短到12小時以內。
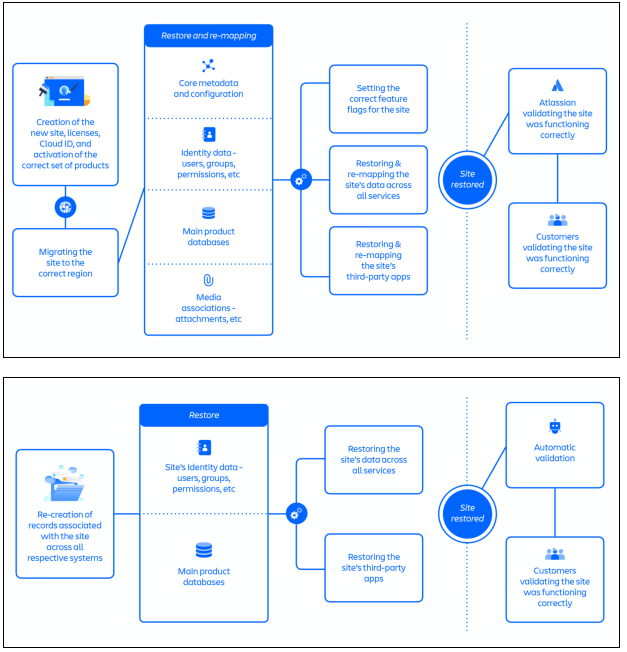
Atlassian第一個復原方法中,需要高達70個步驟,而且沒有事先完成的自動化腳本工具可用,得邊做邊人工處理。這正是為何第一個復原方法花上48小時的緣故。後來改良後的第二個復原方法,放棄使用新網站ID,而直接沿用企業用戶遭刪除的舊網站ID,就少了許多需要驗證的動作,來簡化了一半驗證程序,再加上後來完成了自動化復原工具和驗證工具,才把復原時間縮短到12小時以內。圖片來源/Atlassian
為何顧客遲遲無法取得支援,從失敗的顧客溝通學到教訓
不只資料復原時間延宕,在這次當機事件中,Atlassian還遭遇了另一個問題,就是顧客抱怨無法取得官方的聯繫和說明。導致顧客溝通失利的關鍵,也是因為企業網站全站資料遭到刪除的緣故。因為Atlassian的核心系統(負責支援、授權和計費)下達了客戶網站刪除指令後,不只刪除了企業網站ID資訊,也會刪除聯絡資訊,例如網站系統管理員的聯絡方式。因為,Atlassian是利用網站ID(網站URL網址)和系統管理員聯絡清單,作為安全驗證、優先順序等用途的識別清單,因此,刪除指令會一併刪除這些資料,也讓Atlassian無法系統性的識別受到影響的企業顧客,以及保有顧客直接互動的能力。
再者,Atlassian的線上聯絡表單或是工單申請,都要求要提供有效的網站URL網址,但是受影響企業的網站ID已經失效,就無法送出表單或申請工單,除非該企業有另一個可正常使用的網站ID。當Atlassian要開始聯繫顧客時,只能透過業務團隊手上的聯絡名單,但其中不少聯絡資料已經異動失聯,Atlassian只能從其他可用資料,例如帳單,歷史工單等來源,重建完整的聯絡人清單,這就大大拖慢了Atlassian對顧客的回應速度,也難怪有企業用戶抱怨,好幾天都沒有得到任何聯繫或事故說明。
再加上,因為架構的複雜性,帶來了這次事故復原的挑戰,Atlassian遲遲無法確定影響範圍和準確估算解決時間,Atlassian採取了錯誤的做法,決定等到了解事故全貌後,才要告知顧客,這就讓顧客長時間處於資訊不明的不確定狀態,而引發的大量抱怨。
Atlassian坦言,失去聯絡清單而無法聯繫顧客,再加上採取了解全貌才說明的策略,讓他們沒有更早採取公開回應的做法。一直到事故發生一周後,才在技術長部落格上公開復原進度,而在這個過程中,失去聯絡資料的企業顧客,遲遲無法獲得來自官方的私下說明。
Atlassian從四月大當機學到的4個教訓
在這起事件事後,Atlassian在報告中歸納出4個教訓,第一項就是要在所有系統中普遍採用「軟刪除」的做法,也就是避免直接刪除資料,而是先停用資料,經過一段保留期才真正刪除。這起事件是來自合法的刪除指令,因此工程團隊沒有收到任何事前警告,而在刪除程式的事前測試中,也因為用對了正確的AP ID而非後來實際提供的錯誤網站ID,而沒有發現刪除目標的改變。
Atlassian決定,必須徹底採取軟刪除,也要設計多層保護機制來避免錯誤或誤刪,並建立一套標準化的驗證審查流程。
而第二個教訓則來自這次辛苦復原的過程,日後必須在災難復原計畫中,建立一個大宗客戶發生多網站、多產品刪除事件的自動化修復機制。而他們也發現,過去靠多年累積的事件管理計畫中,只會針對較小規模、短期影響的事件進行模擬演練,但這次事件中,動員了數百名工程師和客服支援人員,而且動員超過2周。日後需要在產品層級事件教戰守則中,建立一個可讓數百人協作的大規模事件流程來演練。最後一項教訓是與顧客溝通管道的改良,一方面既有事件溝通教戰守則,沒有透過多種管道,尤其是社交媒體這種更公開、廣泛的做法,來承認事件的發生,也與顧客溝通說明後續進展,另一方面,也要改進現有關鍵聯絡人的維護方式和顧客通報流程的盲點。Atlassian也公開了這次大規模事件管理流程的運作示意圖。
在SRE實務中,事後分析報告(Postmortem)是精進網站可用性的關鍵,現在也有越來越多雲端供應商,願意公開自家大當機事件的事後分析報告,來向外界說明。不只Atlassian,過去也有多起重大當機事件,業者都也揭露事後分析報告。
儘管Atlassian這份報告仍遭到批評,沒有更完整地揭露這次事件所影響的實際使用者人數,而只公布了受影響的企業家數,但在報告中,Atlassian對於事故發生原因,到如何因應複雜資料復原的過程,都提供了種種細節和詳細說明,仍是值得臺灣企業參考的一次經典SRE事後分析報告,也是SaaS服務維運團隊必須了解的一起重大當機事件。
熱門新聞

2025-06-02

2026-03-13

2026-03-14

2026-03-13

2026-03-13

2026-03-13

2025-04-15
2026-03-16