Google在其最新的人工智慧研究,發表了一種用於加速大型模型推理的方法TaskMoE(Task-level Mixture-of-Experts),也就是說,使用該方法,在模型擴大的情況下,推理的成本不會顯著增加,因此能繼續提供有效率的服務。
由於擴展大型語言模型,能夠使像是T5、GPT-3和M4這類語言模型的結果,獲得明顯的提升,因此在追求更高品質結果的目標下,研究人員無不盡可能擴展模型。建構更大模型的常用方法,通常是增加層數,或是增加層的維度,使模型更深更寬。
這類密集模型採用輸入序列,序列會被切分成更小的元件,稱為令牌(Tokens),這些令牌會傳遞給整個網路,活化每一層和參數。Google提到,雖然這些大型且密集的模型,在多自然語言處理任務上獲得很不錯的結果,但是訓練成本也會隨著模型規模線性增加。
因此為了降低成本,研究人員開始採用混合專家(Mixture of Experts,MoE)方法,建構稀疏活化模型。與密集模型方法不同之處,在於傳遞給網路的每個令牌,會藉由跳過部分的模型參數,依循被稱作專家的獨立子網路,藉此減少計算量。
而將輸入令牌分配給各子網路的決定,則由一個小型的路由網路決定,混合專家方法讓擴增模型大小所付出的成本,不會成比例地線性增加,進而提升效能。
但Google提到,雖然這是一個有效的訓練策略,但是將長序列令牌發送給多個專家,會再次使推理計算成本增加,因為專家會分散在大量的加速器中,像是1.2T參數的GLaM模型,就需要用到256個TPU-v3晶片。因此又會與密集模型遭遇到相同的問題,混合專家模型提供服務所需要的處理器數量,與模型大小成線性關係增加,因而增加計算需求,並導致明顯的通訊開銷和工程複雜度。
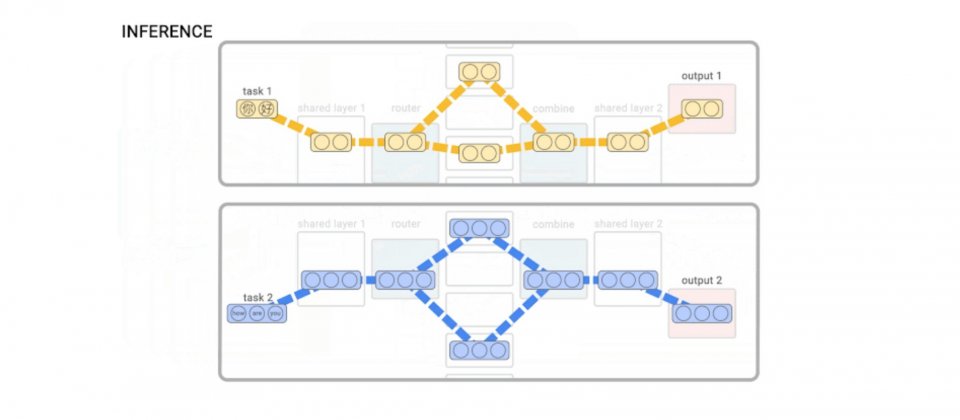
因此Google發展了一種成為TaskMoE的方法,在模型擴展的同時,仍然能夠有效率地提供服務。Google的方法是訓練一個大型多任務模型,並在推理時,丟棄每個任務未使用的專家,從中萃取出更小、獨立的任務子網路,能夠適用於推理,又不會損失模型品質,並且顯著降低推理延遲,與其他混合專家模型以及使用知識蒸餾壓縮(Distillation)的模型相比,Google證明,他們的方法在多語言神經機器翻譯方面更為有效。

Google比較TaskMoE、典型混合專家模型TokenMoE和基準密集模型的吞吐量和每秒解碼令牌數,TaskMoE模型比TokenMoE模型小達7倍,可以直接在單個TPU-v3晶片上運算,不需要像是TokenMoE使用64個TPU-v3晶片,且TaskMoE吞吐量峰值是TokenMoE的2倍,Google提到,TokenMoE模型花了25%的推理時間在裝置間的通訊,而TaskMoE幾乎沒有通訊成本。
以結果來看,在多語言翻譯任務中,TaskMoE模型的分數,硬是比經蒸餾的TokenMoE模型平均高了2.1 BLEU。
熱門新聞

2026-03-06

2026-03-06

2026-03-06

2026-03-06

2026-03-09

2026-03-06
2026-03-06