
微軟和Nvidia合作研究語言模型,發表了目前最大的單體Transformer語言模型MT-NLG(Turing Natural Language Generation Model),具有5,300億個參數,作為Turing NLG 17B和Megatron-LM的後繼者,MT-NLG的規模是目前這類最大模型的3倍,能在完成預測、閱讀理解、常識推理、自然語言推理和詞義消歧等自然語言任務,提供極高的準確性。
近年來自然語言處理領域,得利於Transformer語言模型的大規模運算、大資料集,和進階的訓練演算法,使得語言模型能夠具有大量參數,進行更豐富、細緻的語言理解,因此語言模型也能更有效地作為零樣本或是少樣本學習器,應用在更廣泛的自然語言任務中。
現在訓練大型語言模型,仍具有不小的挑戰性,研究人員解釋,即便是最大的GPU記憶體,也難以放下這麼大量的參數,而且如果不對演算法、軟體和硬體堆疊進行最佳化,過長的運算時間將會使得訓練模型變得不切實際。
微軟和Nvidia密切合作,應用GPU和分散式學習軟體堆疊,實現超高效率模型訓練,並且使用數千億的令牌,建構高品質自然語言訓練語料庫,共同開發訓練配置,以最佳化效率和穩定性。
模型訓練使用基於NvidiaDGX SuperPOD的Selene超級電腦,以混合精度訓練完成,該超級電腦搭載560臺DGX A100伺服器,這些伺服器使用HDR InfiniBand以全胖樹拓墣連接,每臺DGX A100擁有8顆A100 80GB Tensor Core GPU,之間以NVLink和NVSwitch相互連接。
研究人員解釋,只有這種能夠在數千個GPU間實現平行性的架構,才能在合理的時間,訓練具有數千億個參數的模型。但就現有的平行策略,包括資料、工作管線和張量切片,還是無法用於訓練這種模型。
因此研究人員結合Megatron-LM和PyTorch深度學習最佳化函式庫DeepSpeed,創建了高效且可擴展的3D平行系統,將資料、工作管線和基於張量切片的平行性結合在一起,來克服訓練大型語言模型所遭遇的困難。
Megatron-LM的張量切片能夠擴展節點內的模型,並藉由DeepSpeed工作管線的平行性,來跨節點擴展模型。就5,300億個參數的MT-NLG來說,每個模型副本需橫跨280個A100 GPU,具有8路張量切片和跨節點的35路工作管線並行性,並且透過DeepSpeed的資料平行性,擴展模型至數千個GPU。
MT-NLG在多種類型的自然語言任務,都達到了目前最佳的結果,以少樣本預測來說,比較或是尋找兩句子間的關係,通常是對語言模型較具有挑戰性的任務,但是MT-NLG能夠使用更少的令牌訓練,也就是說,更大型的模型訓練速度更快。
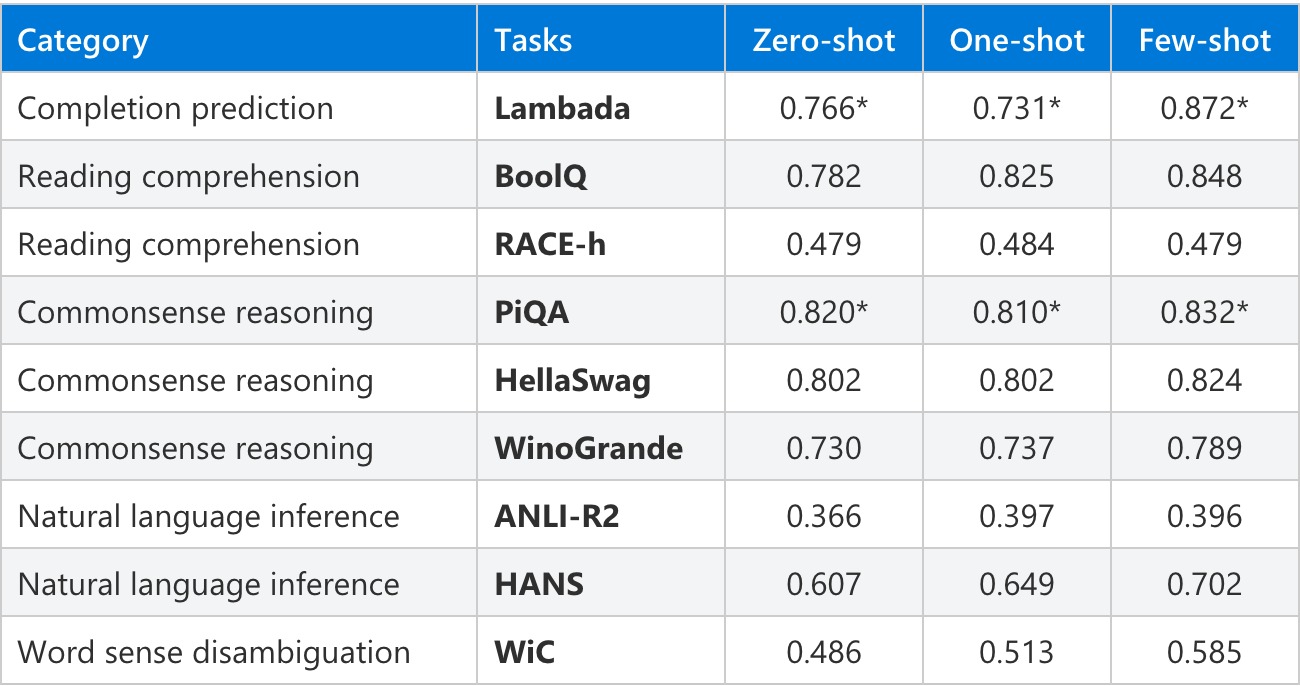
除了一般自然語言任務都已經難不倒MT-NLG,MT-NLG還具有基本的數學運算能力,研究人員提到,雖然離真正具有算術能力還有一段距離,但該模型展現了超過記憶算數的能力。
另外,研究人員還在HANS資料集測試MT-NLG,藉由向模型提供包含簡單句法結構的句子作為問題,並且提示模型給予答案,過去這樣的用例,即便結構相當簡單,但是自然語言推理模型仍會對於這類輸入感到苦手,但是MT-NLG在不需要微調的情況下,就能表現良好。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09

2026-03-06