Tesla
在今年Tesla AI Day活動上,美國電動車大廠特斯拉(Tesla)展現自家最新自駕車應用同時,首度公開揭露一款自製AI訓練晶片Dojo D1,強調擁有GPU的強大運算力,更兼具CPU的運用彈性,以及超高速傳輸頻寬,甚至在AI算力表現也優於Google的TPU v3,可提供362 TFLOPS運算效能,特斯拉不只用它加速AI訓練建立全自動駕駛汽車,未來也將作為首款人型機器人Tesla Bot的AI訓練使用。

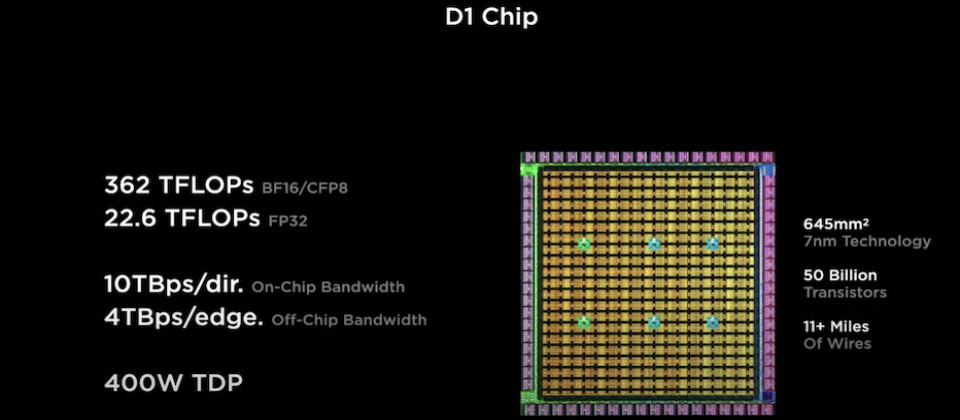
這顆自駕車AI晶片D1 ,是由Tesla工程團隊一手開發完成,從晶片架構、製作到封裝,採用先進7奈米製程,其內含高達500億個電晶體。根據Tesla的介紹,D1處理器晶片是由354個高效能訓練節點所組成的,每個訓練節點都可視為是一個個運算晶片,每個訓練晶片皆採用客製ISA指令集架構設計完成,特別對於ML工作負載執行加以優化,並內含1.25MB高速的SRAM以及低延遲和高頻寬的網路fabric,使得單一晶片,在BF16/CFP8測試基準下,其運算效能可達1.024 TFLOPS。
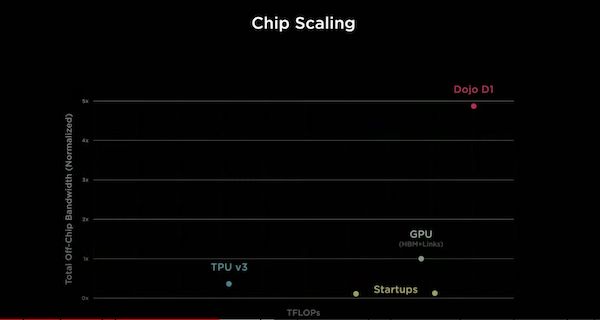
由354個訓練節點所組成的D1模組晶片,其運算力更一舉達到362 TFLOPS(每秒1兆次浮點運算) ,若以目前市面已知的ML晶片 (TPU v3、GPU(HBM+Links互連)或其他新創ML晶片)性能來做比較,Tesla指出,D1 算力表現還優於其他市面ML晶片,甚至比Google的TPU v3表現都還好。另外這顆處理器本身的熱設計功耗(TDP)僅有400瓦,相較之下,TPUv3有達到450瓦。
不只運算效能,Tesla也特別強調這顆AI處理器,在設計上採用新的晶片互連架構,可提供內部高速互連,總頻寬可達到每秒40TB的傳輸能力,而且每個D1晶片,能支援最多576線道,可用於高速I/O應用,跟當前最先進網路交換器相比,Tesla表示,D1晶片可提供高達兩倍的傳輸頻寬。
Tesla Dojo專案主要負責人Genesh Venugopa則說:「Dojo D1處理器晶片是一款純機器學習訓練機器,完全專為ML訓練和高速頻寬而設計。」
不單是自駕車AI訓練上會用到,Tesla執行長馬斯克在會中也透露,明年將展示一款人型機器人原型Tesla Bot,也將運用到這顆AI訓練晶片,做為機器人AI訓練來使用。他表示,Tesla是世上最大的機器人公司,「因為我們的汽車就像裝了輪子的半感知機器人(semi-sentient robot) ,所以運用到人型機器人身上也說得通。」
Genesh Venugopa表示,該研究團隊最新還以約1,500個D1晶片互連打造一套ML訓練引擎系統,稱為訓練磚塊 (Training Tile),每個Training Tile系統,可提供運算效能更高,達到9 petaFLOPS,等於是一臺AI超級電腦。目前他們已完成一臺Training Tile原型。
為了打造這套AI訓練系統,研究團隊費盡心思,不僅設計Dojo介面處理器作為host bridge,用於與PCIe Gen4的連接,還加入高速頻寬的DRAM共享記憶體,並以Radix網路連接建立低延遲Mesh架構。另在電源方面,則重新客製一個電力調整器模組,搭配52伏特直流電輸入,可以做到更省功耗,更省電。不只硬體,在軟體面向,他們也結合了DPU (Dojo Processing Unit)、Dojo Compiler Engine、Neural Net models等軟體套件,建立完整軟體堆疊,藉此來實現AI運算規模化。
接下來,他們還要以120個Training Tile系統建立一個超大型ExaPOD運算叢集,其運算效能更可達1.1 ExaFLOPS (每秒一百萬兆次運算),還具有多達每秒36TB對外高速頻寬。待完成以後,Genesh Venugopa表示,它將是世上最快的AI訓練超級電腦,預期在相同成本下,可提供多4倍效能,而且更省電,每瓦效能將能提升1.3倍之多。未來還會開發下一代Dojo硬體,性能更提升10倍。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02