
人工智慧實驗室OpenAI正式發布GPU程式語言Triton,這個語言是專門用來開發機器學習演算法,讓開發人員以類似Python程式碼撰寫方式,在即便沒有CUDA程式開發背景下,也能夠撰寫高效能GPU程式碼,而且大部分程式碼都能與專家撰寫的程式碼效能相當。
官方提到,深度學習領域的研究方向,通常需要使用原生框架運算子來實現,但這種方法需要創建許多臨時張量,而這會損害神經網路的效能。雖然可以透過編寫專門的GPU核心來解決這個問題,但是因為GPU程式碼開發很複雜,因此增加了開發門檻。
雖然現在有許多系統來簡化這個過程,但OpenAI認為,這些系統通常過於冗長,或是缺乏靈活性,甚至產生的程式碼效能,明顯低於手動調整的基準。因此他們為了解決這個GPU程式開發痛點,因而擴展並且改進了Triton,現在發布最新版本Triton 1.0。
Triton原本的創造者Philippe Tillet,在2年前發表論文,首次公開了Triton初始版本,而現在Philippe Tillet在OpenAI工作,與其他研究人員一起改進Triton,使其成為適用於企業的機器學習專案。
當前大部分企業人工智慧模型,都在Nvidia的GPU上執行,開發人員使用Nvidia提供的軟體建構這些模型,而Nvidia重要的框架CUDA,提供人工智慧程式使用GPU進行運算的基礎模塊。而現在OpenAI所推出的Triton,擁有編寫簡單且執行高效能的優點,比起CUDA框架普遍被認為撰寫具有挑戰性的問題,Triton對開發人員來說更加友善。
OpenAI研究人員解釋,現在GPU架構大致可以分成3個重要元件,DRAM、SRAM和ALU(算術邏輯單元),而最佳化CUDA程式碼必須同時考慮這三者。來自DRAM的記憶體傳輸,必須要合併成為大型交易,以妥善利用記憶體介面的最大頻寬,而這些資料在重新使用之前,必須手動儲存到SRAM中,並且管理最大容量,來減少檢索時共享記憶體庫的衝突,而且運算必須要在串流複合處理器(Streaming Multiprocessors)間,仔細分區和調度,來善用指令和執行緒平行運算,或是增加專用ALU的使用率。
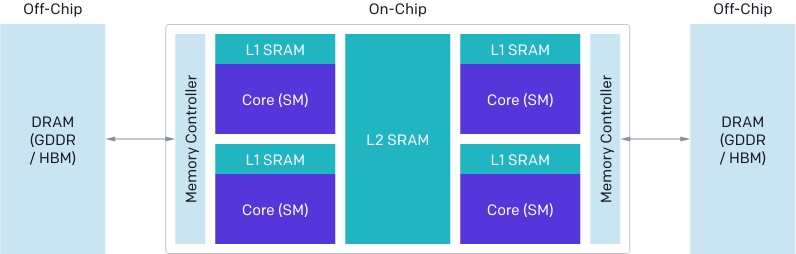
撰寫程式碼時,考慮這些要素需要許多經驗,即便對擁有多年開發經驗的CUDA開發者來說,也並非一件簡單的事,而Triton的目的是要能自動進行最佳化,讓開發人員可以專注在開發高級邏輯上,不過,Triton也保有了一些靈活度,為了使Triton廣泛適用,因此不會跨串流複合處理器自動調度任務,Triton把這些重要的演算法考量留給開發人員決定。
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10