
Naver發表GPT-3等級的韓文自然語言預訓練模型HyperCLOVA,要用來強化自家AI線產品,比如提供內容生成、搜尋/QA等功能。
Naver
重點新聞(0528~0603)
NLP GPT-3 HyperCLOVA
韓文版GPT-3!Naver發布韓文NLP模型HyperCLOVA,懂語言還要懂圖片和影片
Line母公司Naver日前在線上發表超級AI平臺HyperCLOVA,號稱是GPT-3等級的韓文版自然語言預訓練模型,可像人腦般理解語言。Naver指出,HyperCLOVA有2,040億參數,比公認是NLP世界標準的GPT-3,還要多出1,750億個參數。參數越多,就越能細緻地辨識語言。
Naver表示,HyperCLOVA的訓練策略很特別,因為HyperCLOVA用了大量資料來訓練模型,「是GPT-3的6,500倍,」而且,這些訓練資料97%是韓文語料。HyperCLOVA可用來開發語言理解相關服務,像是對話、翻譯、句子生成、摘要和機器閱讀等,Naver也補充,由於HyperCLOVA是超大型模型,因此少樣本學習能力佳,只需要少量樣本就能產出良好的結果,適合自動生成行銷短句、課本單元的摘要生成、問答等應用場景。Naver更表示,未來還要讓模型學會多模態任務,也就是不只要懂語言,還要能同時看懂圖片和影片。
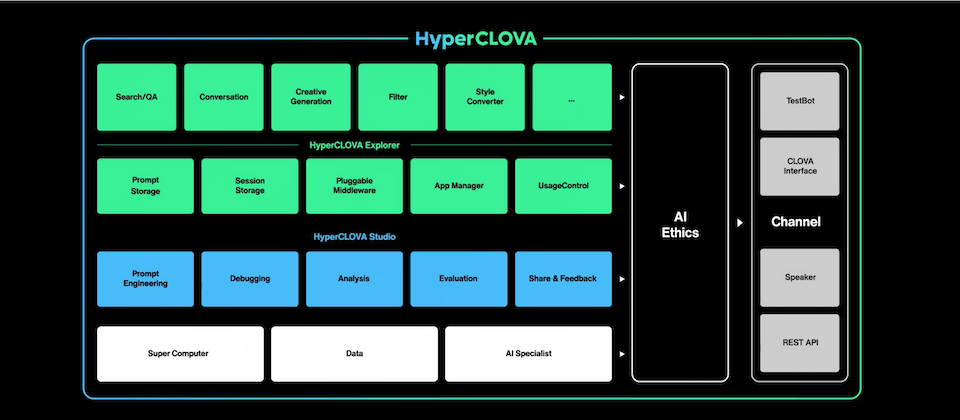
Naver會提供HyperCLOVA給想要開發AI服務的企業。從線上會議投影片可看出,Naver將HyperCLOVA應用場景劃分為2種,包括用來產生內容、優化搜尋的HyperCLOVA Explorer,以及用於分析、評估和除錯的HyperCLOVA Studio。(詳全文)
Nvidia AI開發協作 Base Command
瞄準大規模、多團隊開發需求,Nvidia推出AI開發雲平臺要加速協作
Nvidia聯手NetApp推出雲端代管AI開發平臺Base Command,瞄準大規模、多使用者和多團隊的企業開發需求,在平臺上整合了多種Nvidia AI開發工具,像是NGC目錄中的AI分析軟體、MLOps API和Jupyter Notebook等,也結合NetApp的資料管理功能,要加速AI專案從原型到量產的階段。
進一步來說,Base Command提供單一入口,來管理AI開發的各種工作流程,並加速資源分享,比如用戶可透過圖形使用者介面、命令列API和整合式的監控儀表板與報告儀表板,來分享開發狀況。用戶也可透過平臺上的AI工具,來安排工作負載、微調模型或更快得到洞察等。Google Cloud也將於今年在Marketplace中新增對Base Command的支援。
Base Command才按月訂閱制,每月費用為9萬美元起,首波試用區域僅限北美。(詳全文)
GPT-3 自然語言 Power Apps
用自然語言寫程式!微軟把GPT-3嵌入Power Apps
微軟日前在自家開發者大會Build上宣布,將可生成語言的大型自然語言預訓練模型GPT-3,嵌入自家開發應用程式Power Apps中,可直接將自然語言轉換為程式碼或公式,加速應用程式的開發。這也是微軟取得GPT-3獨家授權後的第一個商用案例。
不過,Power Apps中,目前只有Power Fx這個功能整合GPT-3。Power Fx是一種從Excel公式衍生而來的低程式碼語言,有了GPT-3加持,使用者不具備寫程式經驗,也能用自然語言輕鬆開發應用程式,比如,使用者可直接在Power Apps中輸入:「告訴我美國客戶中有多少人的訂閱過期了」,這時,系統會在下方跳出相對應的公式,並附上說明,告訴使用者這個公式如何運作。之後,使用者再將公式套用到App上即可。
微軟表示,企業員工也能用它來審查非營利機構的捐贈、管理疫情的出差事項,或減少維護風力渦輪機所需的加班時間。這項新功能,會在今年6月底前針對北美市場提供預覽版,目前僅支援英文。(詳全文)

Databricks AutoML 黑盒子
打破黑盒子!Databricks新AutoML工具有Python筆記本
由Apache Spark技術團隊所創立的資料科學公司Databricks,發布一款簡化ML開發部署的工具AutoML,可自動化進行預處理、特徵工程,以及模型訓練與調整,用戶能完全以使用者介面來選擇資料集、配置訓練,和部署模型。
但為何直到現在才推出AutoML工具?官方指出,現有許多AutoML工具都是黑盒子,用戶無法切確知道模型訓練的過程和方法,因此當需要特定修改,或受監管稽核時,就更難使用這些工具。Databricks打造的則是一款如「玻璃盒」的AutoML,每個經訓練的模型,都提供Python筆記本,資料科學家可在這些筆記本中,添加或修正單元格,還能利用這些筆記本快速開發,不需要重新編寫一些樣板程式碼。
此外,Databricks AutoML也提供資料分析功能,來提供資料集統計資訊,快速檢查資料集是否適合訓練。另外,也可與追蹤指標和參數API—MLflow整合,用戶可試驗模型,並在Databricks模型註冊表內註冊和提供模型。(詳全文)
TPU VM 模型訓練
Google發表新TPU加速器VM,訓練模型效能更好且成本更低
Google發布最新Cloud TPU虛擬機器,用戶可直接存取雲端TPU運算資源,而且,開發者能直接在TPU上使用TensorFlow、PyTorch和JAX等框架進行模型開發和部署。
過去,用戶只能遠端存取Cloud TPU,而且要設置一個或多個虛擬機器,再用gRPC網路來與Cloud TPU主機通訊。但在新的Cloud TPU虛擬機器中,用戶不必這麼做,直接在每臺TPU主機上配置自己的互動式開發環境即可。而且用戶在單一TPU虛擬機器中,就能逐行編寫ML模型並除錯,也能用Cloud TPU Pod來擴展規模,與其他TPU高速互連。Google表示,由於資料不必再透過資料中心的傳遞,模型訓練效率也因此更好。(詳全文)
PyTorch 模型搬遷 臉書
統統搬到PyTorch去!臉書揭露自家上千個模型搬遷策略
為服務數十億用戶,臉書AI模型每天要推論上兆次,這個不斷增長工作負載量,促使臉書不停改善AI框架,也因此他們決定將所有AI系統搬遷到PyTorch上。
不過搬遷過程複雜,模型要歷經離線、線上測試、訓練、推理和發布以及多項測試,來確保舊框架Caffe2和PyTorch的效能,得花上好幾周才能完成。於是,臉書開發一套內部工作流程和自定義工具,來幫助各團隊決定搬遷的最佳方式,甚至可判斷系統能否不搬遷直接更換。這個工具包括一套內部基準測試,也可比較原始模型和PyTorch模型的效能,解決個團隊最在意的新舊模型效能問題。
經過一年搬遷,現在,PyTorch已是支援臉書所有AI負載的底層平臺,工程師可在數分鐘內,部署好新模型;模型的建立、編寫、測試和除錯也更容易進行。目前,臉書總共有4,000個模型使用PyTorch,而生產環境中則有1,700個PyTorch模型,更有超過93%的新模型(如辨識和分析臉書內容等任務的模型)都在PyTorch上執行。(詳全文)

圖片來源/Naver、Google、微軟、Databricks、臉書
AI趨勢近期新聞
1.Amazon Redshift機器學習功能正式推出
2. 特斯拉北美部份車款新車將棄雷達,改用純電腦視覺、AI感測
3. 再見了Token!Google提出Byte等級的改良版Transformer架構
資料來源:iThome整理,2021年6月
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-06

2026-03-05

2026-03-06