機器人Fuchikoma,融合了社群偵測、異常偵測、NLP和機器學習,來揪出異常事件。")
奧義團隊開發一套ML威脅獵捕(Threat hunting)機器人Fuchikoma,融合了社群偵測、異常偵測、NLP和機器學習,來揪出異常事件。
攝影/王若樸
奧義資深研究員CK在臺灣資安大會上,分享自家團隊如何打造威脅獵捕(Threat Hunting)系統。他們從零開始,用事件資料訓練一套ML模型,經過4個版本發展,克服命令列(Command line)資訊不足、訓練資料不均衡、缺乏標註資料和沒有攻擊時序圖(Storyline)等4大難題,打造出能自動揪出異常事件,還能順藤摸瓜掌握完整攻擊來龍去脈的威脅獵捕機器人Fuchikoma。
為何選擇威脅獵捕?怎麼用機器學習自動獵捕威脅?
「我們想用機器學習做到自動威脅獵捕,而不是傳統的IR,」CK說。IR(Incident response)是指資安事件應變,著重於事件後的分析、調查和鑑定;有別於事後作業,威脅獵捕聚焦於預防,透過每天、每周定期分析,來找出可疑活動、描繪駭客攻擊的完整時序圖。這個做法比IR更全面,更能找出惡意程式的來源全貌,而非只揪出單支惡意程式。
但,為何要用機器學習來做威脅獵捕呢?CK表示,機器學習可自動排除大量錯誤警示,只篩選出嚴重的資安事件,來給人類專家分析。不過,團隊嘗試時發現,威脅獵捕十分複雜,不可能只靠單一機器學習模型完成,而是要整合不同機器學習演算法、「兜成一個ML Pipeline,才能解決問題。」
從零打造機器學習系統Fuchikoma,自建資料集來訓練
於是,CK團隊開始設計這個威脅獵捕機器人Fuchikoma。他指出,會取名為Fuchikoma,是因為這個名字符合奧義的設計哲學;Fuchikoma是日本動畫攻殼機動隊中的AI機器人,它與人類合作後戰鬥力大增,因此,「這套系統就是來輔助人類,要幫助專家更快找出威脅。」
在這個研究中,CK團隊將Fuchikoma要偵測的問題,鎖定在Windows新處理序事件上(也就是Process creation events,事件識別碼4688),並輔以命令列資訊作為訓練資料。
接下來,團隊利用2套攻擊情境腳本來建立了2套資料集來訓練Fuchikoma。第一個腳本Playbook APT3,利用Empire等滲透攻擊工具,依據MITRE ATT&CK資安框架所定義的APT 3階段攻擊情境來產生大量模擬的攻擊事件,再加上MITRE ATT&CK Evaluation第一回合所產生的資料,一共有6,786個新處理序事件資料。
再來,第二套攻擊場景腳本Playbook Dogeza Metasploit,則是用滲透攻擊框架Metasploit模擬APT攻擊,來建立第2個資料集,內有近6萬9千個事件。(如下圖)

Fuchikoma v.0誕生,但有4大問題要解決
於是,團隊用這些資料訓練一個分類器,來從事件日誌中(log)分辨該事件是否為惡意。Fuchikoma第0版因此誕生,但CK發現,這個方法還有4大問題。
首先,每個事件中的信號(Signal)十分微弱。因為,每個事件由每個命令列組成,但每個命令列只含少量訊息,難以判斷是否為惡意,「不像惡意程式,光是一支就含有大量訊息。」
而且,在不同情境下,命令列的訊息也有可能不是惡意。CK舉例,像whoami或netstat這種命令,很難一概而論是否為惡意,得看上下文才行。
第2個問題是訓練資料不均衡。CK解釋,和正常資料相比,只有非常少量資料與惡意攻擊有關。這個特性,讓純監督式機器學習模型沒法有效判斷。
比如,在一次測試中,團隊統計發現,正常資料多達1萬多筆,而惡意攻擊相關資料只有100多筆,整整差了100倍。再來,就算團隊將重複的資料刪除,還是發現正常資料將近2,000筆,而惡意相關資料只有35筆,差距太大。(如下圖)

第3個問題是缺乏高品質標籤。這是因為,標註資料十分耗時耗力,而且,標籤通用性不足,比如在某個環境下產生的標籤,很難在另一個環境應用。
最後一個問題則是缺乏時序圖,「我們希望不只抓出一個惡意程式,而是找出完整的攻擊時序和原因,」如此才能讓分析人員掌握更多資訊。
以上這些問題,都是Fuchikoma第0版無法解決的。因此CK團隊著手改善,開發出第1版。
Fuchikoma v.1:整合分群和分析單元兩大概念
第1版Fuchikoma的特性是分析單元分群(Clustering analysis units),也就是將事件資訊分群。簡單來說,Fuchikoma會先聚合不同事件的資訊,再由一個分析單元建立器(Analysis unit builder),將這些事件重組為一個個分析單元。
再來,Fuchikoma將性質類似的分析單元分群,並加入相關的命令列資訊,當作補充參考訊息。分群後,系統會發出通知,讓分析員來標註這些群。
如此一來,透過連結不同分析單元中的命令列、增加參考資訊,就解決了單一事件中信號微弱的問題。而且,透過分群辨識相似事件,分析員就不必一一手動檢查每個事件,連帶改善標註資料缺乏的問題。
在分析單元方面,團隊參考人類分析師經驗,設計一套進程樹(Process Tree)方法,讓系統自動搜尋特定命令列鄰近的命令列,接著將這些命令列資訊彙整為一篇文字檔,再用自然語言處理(NLP)演算法TF-IDF,將這些文字轉換為向量,然後分群。
因此,第1版的系統運作就會是:事件輸入系統後,轉換為分析單元,接著再轉換為向量來分群,最後由資安人員從分群中找出惡意事件。(如下圖)

雖然第1版解決了每個事件中信號微弱的問題,但仍有3個問題待解決,像是不均衡的訓練資料、缺乏攻擊時序圖,以及難以取得標註資料。CK解釋,雖然第1版能產出分群後的事件,來讓分析員標註,但仍需要人工作業來分析。
Fuchikoma v.2:用異常偵測來提高偵測準確度
為此,團隊進一步改良,開發出第2版Fuchikoma。這個版本採用了異常偵測(Anomoly detection),來提高偵測準確度。這是因為,攻擊事件占訓練資料集的少數,因此與正常資料相比,它的特性就是異常。這一點解決了原本訓練資料不均衡的問題。此外,這個特性也改善了標註人力問題,分析員只需查看系統產出的異常事件即可。
在這個版本中,團隊還用3種演算法來進行異常偵測,包括孤立森林(Isolation forest)、DBScan和離群點(Local Outlier Factor,簡稱LOF)。其中,CK認為DBScan效果最好,甚至在奧義後續的研究中,表現依然突出。
DBScan的特點是,假設給定距離ε,它能將在ε範圍內的每個節點,視為一個群(Cluster)。要是不在ε範圍內,就會視為異常。(如下圖)

因此,第2版Fuchikoma會是這樣運作:當事件資料輸入系統後,會轉換為分析單元,再轉換為向量來分群。有別於第1版,轉為向量後會執行2個步驟的運算,一是異常偵測,二是分群。其中,異常偵測標示出的異常事件,會顯示在向量分群中,分析員再分析這些異常事件即可。(如下圖)
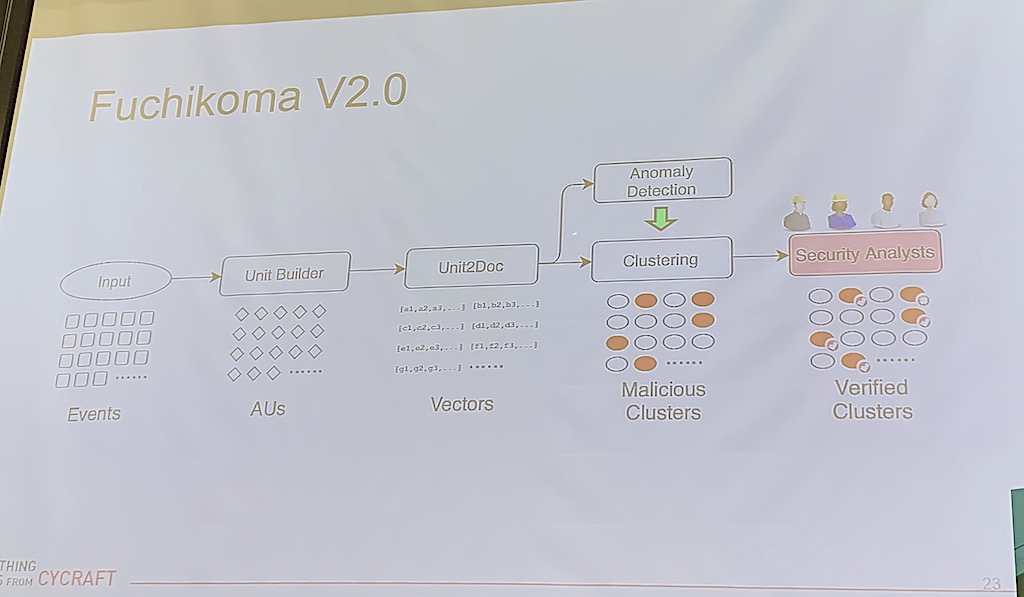
這個版本解決了每個事件中信號微弱的問題,也解決了訓練資料不均衡的問題。接著,就只剩下難以取得標註資料和缺乏時序圖的問題待克服。
Fuchikoma v3:用圖演算法補足惡意攻擊的來龍去脈
接下來,團隊用圖演算法(Graph algorithm)來進行社群偵測(Community detection),要從社群中找出與異常事件相關的事件,並用這個特性來建構時序圖。但圖分析怎麼發揮作用呢?
簡單來說,由於攻擊者一開始只能控制少數處理序,因此勢必會在這些處理序下,做出大量行為,因此形成一個高度密集的圖社群(Graph community)。這種特性,就十分適合社群偵測。(如下圖)

接著,團隊使用一種圖演算法Louvain,來將圖中相對密集的處理序框起來,形成一個社群。
因此,Fuchikoma第3版的運作,就會是:輸入事件後,形成不同的圖,再分為3個運算步驟。首先是從圖中歸納出分析單元,再轉換為向量,接著進行異常偵測;第2是進行攻擊分數計算;第3是進行社群偵測,再透過主題模型找出每個社群的關鍵字,再結合步驟1和步驟2產生的異常偵測結果、攻擊分數計算結果,來標註異常的社群,最後再交給分析人員確認是否為惡意攻擊。(如下圖)
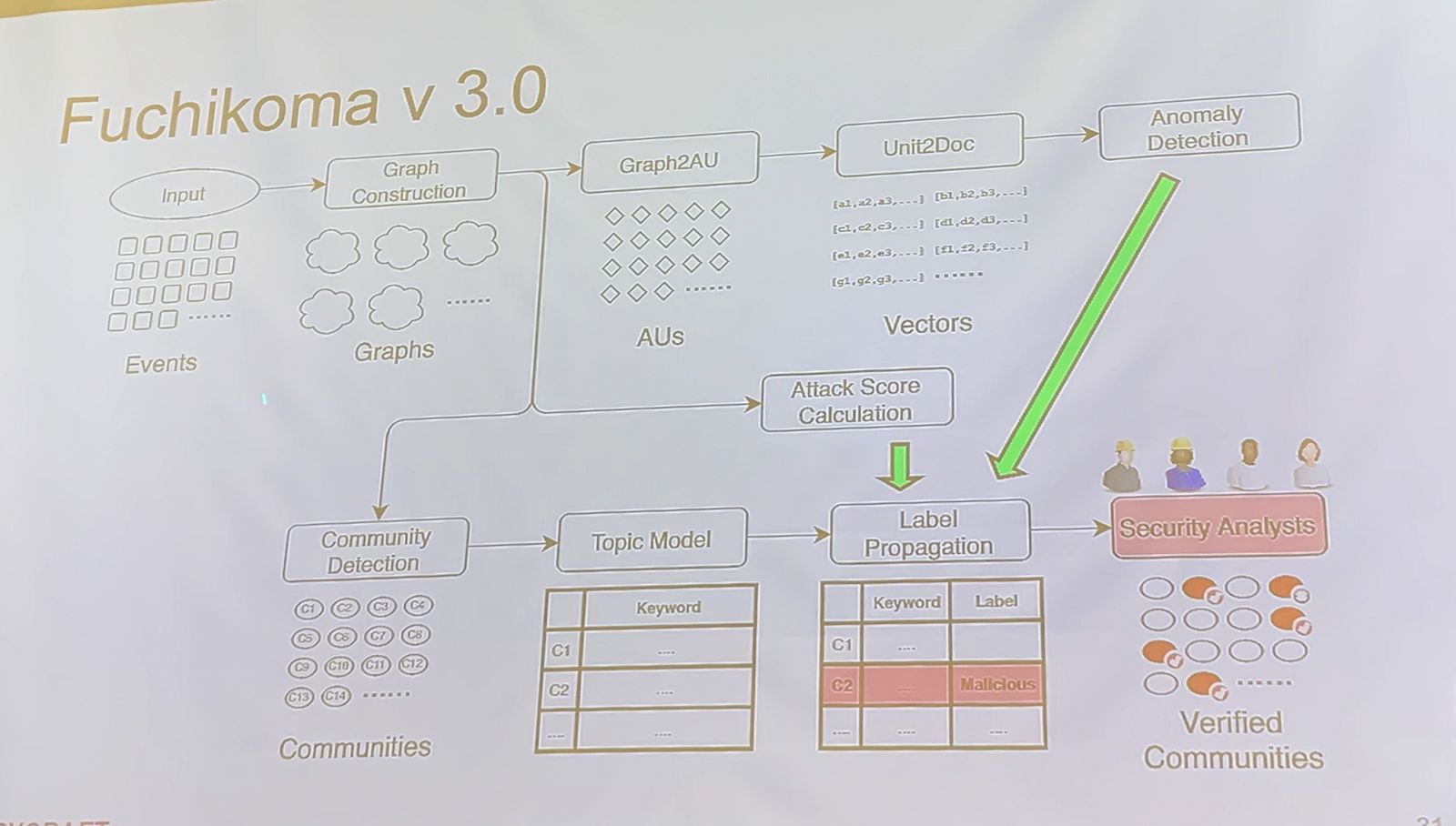
不過,CK也坦言,光是利用資料本身,模型難以區分出正常或惡意,只能分辨正常事件和異常事件(也就是較少出現的事件)。「這種異常事件可能是攻擊,也有可能是環境更新。」因此,要準確分辨正常和異常事件,還是需要外部資料輔助,特別是外部標籤。
而在測試上,Fuchikoma第3版能將APT 3資料集中的6,786個處理序事件,分類為540個社群,並從這540個社群中,找出223個含有異常訊息的社群,再從中分析出異常風險過半的176個社群,交給人類分析員確認。(如下圖)

總的來說,Fuchikoma v.3融合了機器學習、圖演算法、NLP和異常偵測,已能解決奧義團隊最初面臨的4個難題,也能有效獵捕威脅。CK指出,開發者也能用開源工具,輕易開發這種威脅獵捕ML模型,來輔助人類分析員揪出惡意事件。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02