臉書改善其無障礙瀏覽體驗,讓視覺障礙的使用者,能夠更容易地理解照片內容,其最新自動替代文字(Automatic Alternative Text,AAT)技術,能夠偵測和辨識的概念擴大10倍,因此可以對更多類型的照片加上描述,而且描述也多了許多細節,能夠提供相對位置,還有主要和次要物體等額外資訊。
螢幕閱讀器可以使用合成語音,唸出臉書上圖片的替代文字,讓視覺障礙者理解圖片的內容,但是有許多照片並沒有被加上替代文字,所以為了解決這個問題,臉書在2016年引入AAT技術,使用物體辨識功能按需求生成照片描述,改善視覺障礙理解圖片的能力。
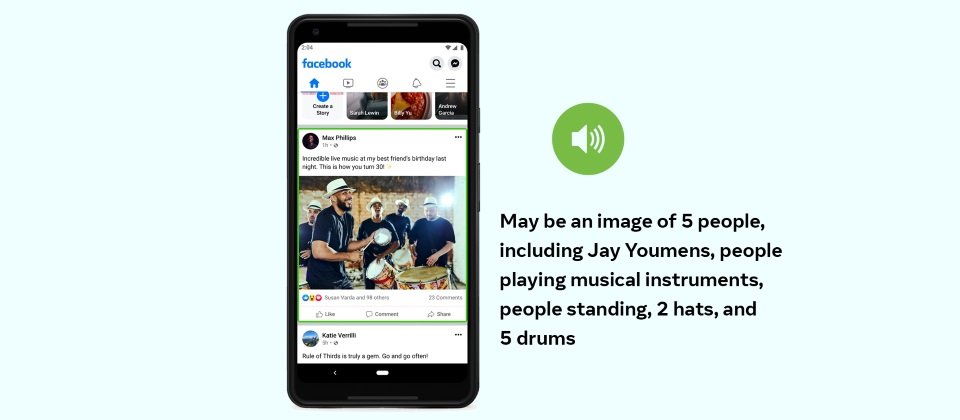
新的AAT擁有非常先進的技術,可以生成包含相對位置資訊等額外描述,生成的資訊不再只是照片中可能有5個人,而是照片中心有兩個人,其他三人分散於邊緣,這暗示著中間兩人是照片的焦點,臉書還舉例,過去照片描述可能簡單地以一棟房子和一座山,來描述風景優美的照片,而新AAT技術能夠強調山和房子的相對大小,來強調山才是照片中的主體。
過去臉書使用監督式學習方法,用數百萬個樣本來訓練深度卷積神經網路,讓AAT模型可以辨識常見的100個概念,諸如樹、山和室外等。但為了要擴大可辨識物件的數量,並且完善AAT模型的描述方式,臉書放棄使用需要人工標記資料的完全監督式學習,臉書提到,雖然這個方法可以提供高精確度結果,但是標記資料耗費大量的人力資源,而這也是原始AAT模型只能辨識100種物體的原因,這是一個無法擴展的方法。
而最新的AAT技術使用了一個強大的模型,該模型是以數十億張Instagram公開照片,和Hashtag組成的弱監督資料訓練而成,臉書對其進行了微調,從所有地理位置採樣訓練用照片,並且使用多種語言的主題標籤,同時臉書還評估了性別、膚色和年齡來評估概念,使得模型更加準確,也在文化等各方面更具包容性,像是模型會盡可能以各地的傳統服飾,來辨識婚禮,而不是只有穿著白色婚紗才是婚禮照片。
現在AAT模型可以辨識1,200多種概念,是2016年版本的10倍多,即便AAT模型僅會提供高閾值的結果,但是仍存在一定的誤差,因此臉書會在每個描述的開頭,都加上「可能」字樣,並且忽略AAT模型無法可靠辨識的概念。
新的AAT模型還能提供細節,除了預設的簡潔描述之外,用戶可以選擇取用具有更多細節的描述,包括照片中元素的數量,以及新增一些預設描述未提及的元素,而且詳細說明也會包括簡單的位置訊息,包括上下左右等,而對於物體的突出程度,也會以主要、次要和附屬等詞彙,來描述圖片元素的重要性。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09