,然而,若要提升與使用者互動的體驗,需要支援多種模態的整合應用,而Nvidia在這部份的技術研發,則是Jarvis這套應用程式框架,10月進入公開測試階段。")
目前交談式AI的應用最常見於聊天機器人(Chatbot),然而,若要提升與使用者互動的體驗,需要支援多種模態的整合應用,而Nvidia在這部份的技術研發,則是Jarvis這套應用程式框架,10月進入公開測試階段。
在10月的GTC大會上,Nvidia創辦人暨執行長黃仁勳介紹完一系列AI推論的應用成效,以及TensorRT這套針對Nvidia推論伺服器使用的編譯器將推出7.2版的消息,在這之後,隨即宣布,他們發展的對話式AI的軟體應用Jarvis,進入開放公開測試的階段。
事實上,Nvidia在今年5月的GTC Digital大會,已揭露更多Jarvis應用架構與方式,他們將其定調為多模態交談式AI服務框架(Multimodal Conversational AI Services Framework),能讓企業運用影音與語音資料,建構先進的語音交談式AI服務,而且可針對本身的產業、產品與客戶特性來進行自定。
Nvidia表示,隨著在家工作、遠距醫療、遠距學習應用大增,企業自行開發交談式AI服務需求量也跟著提升,應用範圍相當廣泛,從客戶支援,到即時翻譯、語音視訊通話的摘要,有了這些服務,可讓身處不同地方的人們,保持工作效率與彼此聯繫。
黃仁勳當時展示了兩個作法,首先是將AI模型結合語音與臉部的應用,他們將一段饒舌歌曲結合一個人頭塑像動畫來展現,就像這個虛擬人物正在唱頌的樣子。
類似的應用他們先前也曾展示,例如,在2017年的語音驅動式臉部3D動畫(Audio-Driven Facial Animation),當中結合了關於動作與情感的全面機器學習技術。
2019年Nvidia AI實驗室(NVAIL)也展示他們發展的語音操作型角色動畫(Voice Operated Character Animation,VOCA)。
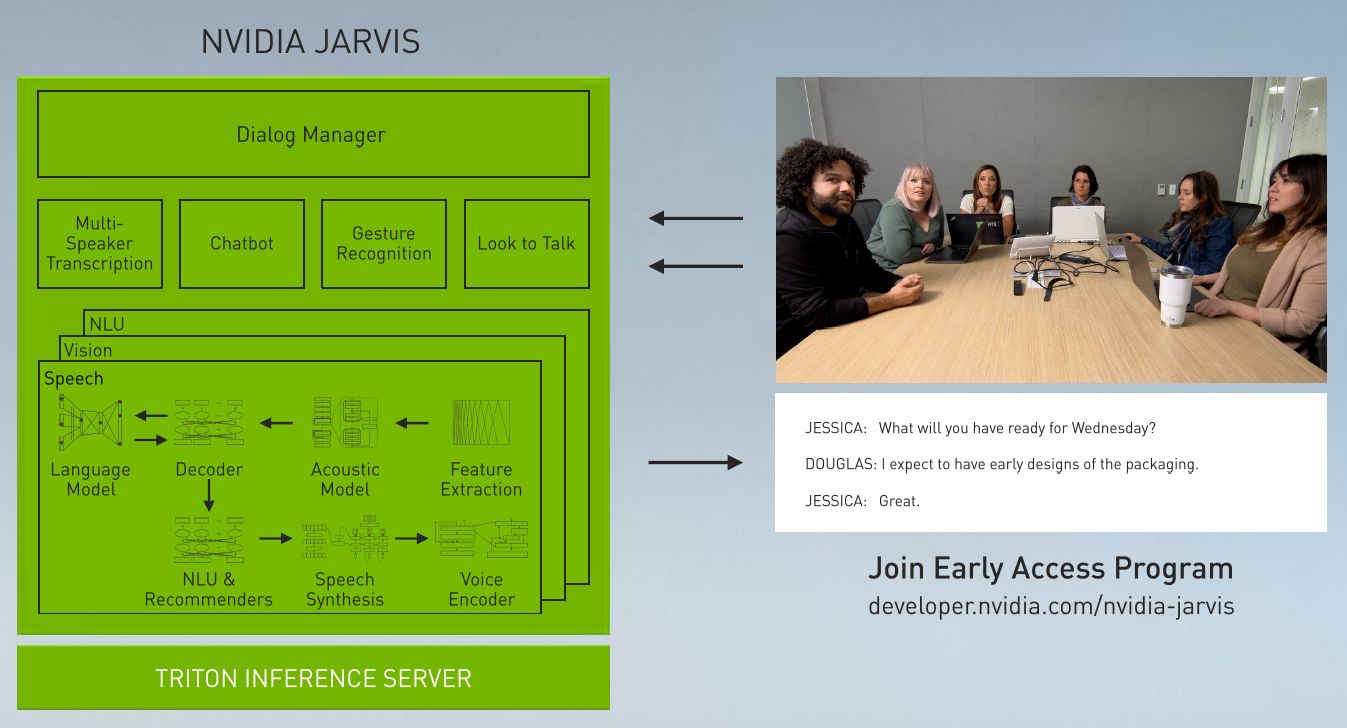
第二個應用則是氣象資訊對話機器人,名為Misty。黃仁勳不只與這個機器人進行天氣資訊的雙向語音問答,機器人本身的動畫也會跟隨所回答的內容而自動變化,例如,面部表情、嘴型說話動作、眼神注視動作,以及呈現不同天氣下的自身狀態。
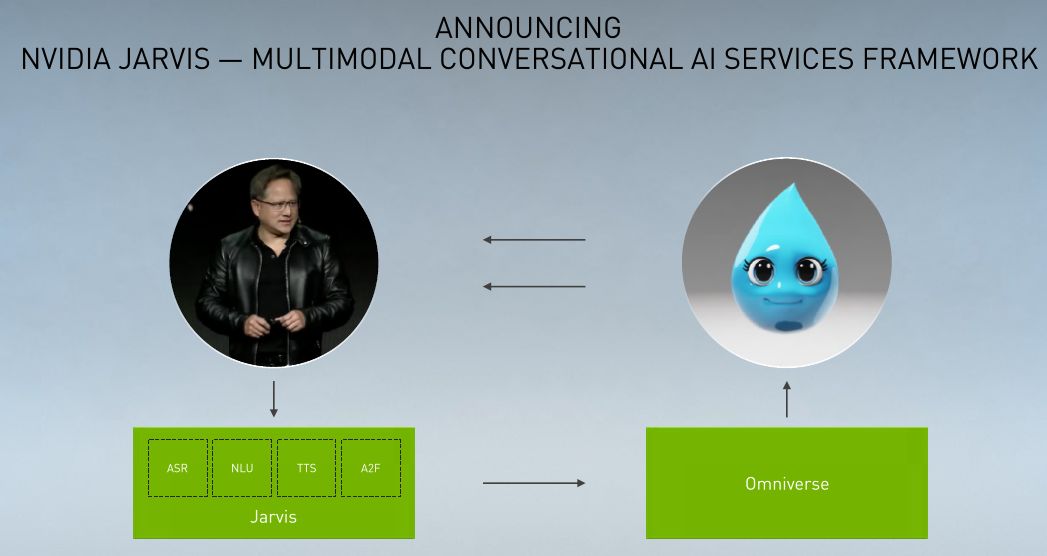
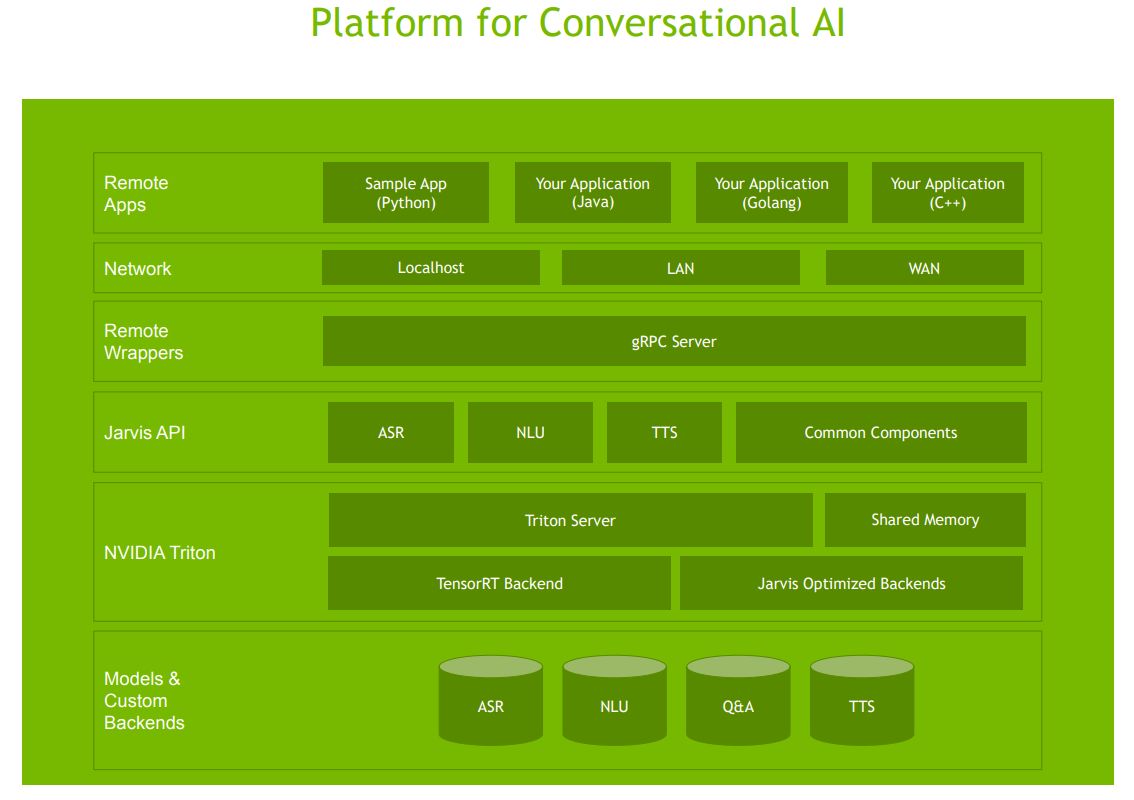
他們運用Omniverse與Jarvis建立了AI驅動的3D數位分身。這當中使用的Jarvis,包含了預先訓練的交談式AI模型,針對語音辨識(ASR)、電腦視覺(CV)、自然語言理解(NLU)、文字轉語音(TTS)等多種AI服務,也涵蓋了Audio2Face語音驅動式的AI技術,能夠從Jarvis合成語音,快速而自動建立即時的臉部動畫,而涉及即時圖像渲染的部份,則交由Omniverse這套即時模擬與協作平臺,來進行3D內容的生產與處理。
值得一提的是,Jarvis包含了幾套先進的深度學習模型,像是Nvidia發展的Megatron BERT,可用於自然語言理解。Nvidia表示,這是世界最大型的BERT(Bidirectional Encoder Representations from Transformers)模型,可理解39億個參數,在進行訓練處理時,可支援數百個GPU的線性擴展,並可隨著模型規模擴大而增加精準度。

企業若要進一步在他們的資料上,更妥善地調校AI模型,可運用Jarvis整合的另一個開放原始碼軟體工具包Nemo,它是用於開發交談式AI模型的工具,當中包含了Python模組集,能簡化模型組建,以及支援混合精度運算,加速訓練與調校,之後也可部署至Jarvis services當中。
除此之外,Jarvis還整合了TensorRT 7.1,可支援今年新推出的A100 GPU,來運用INT8精度來加速BERT推論,獲得6倍的效能提升(相較於搭配V100)。
而在10月Nvidia宣布Jarvis公開測試的消息當中,也首度提及這套解決方案的成效。他們表示,若採用Jarvis這套用來建構多模態交談式AI服務的加速軟體框架,搭配GPU且用於執行深度學習的交談式AI應用時,延遲度將可低於300毫秒,並提供7倍的吞吐量(相較於純粹仰賴中央處理器的作法)。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02