Linkedin現在將人工智慧用在配對求職者與招聘者,透過讓合格申請(Qualified Applicant,QA)模型,學習招聘者過去與應徵候選者的互動,了解招聘者認為應徵者該具備的技能與經驗,推薦應徵者適合的工作,並為招聘者依適合程度排名申請人。
Linkedin使用這個模型,協助應徵者找到最有可能獲得回應的工作,同時也為招聘者標出適合的申請人選。在部署QA模型後,Linkedin平臺各項指標都獲明顯的提升。
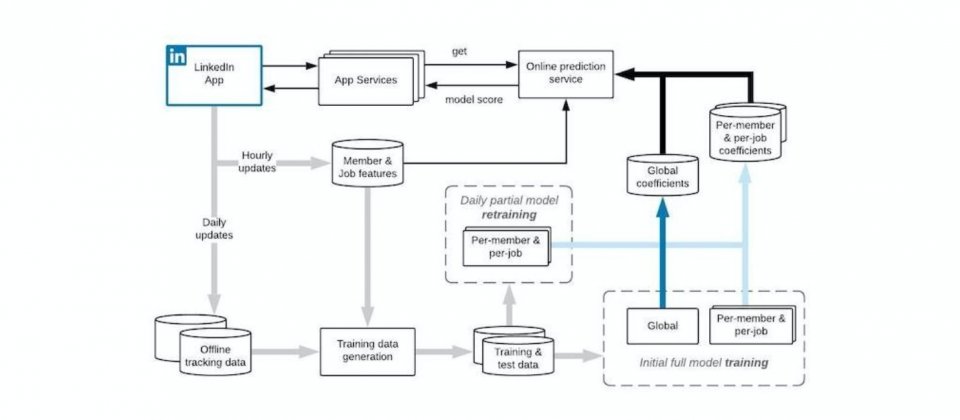
官方提到,求職者積極的申請了許多工作,但通常只有少數得到回應,另一方面,招聘者需要利用有限的時間,篩選大量的申請,因此常會忽略真正適合的人選。因此Linkedin決定用人工智慧來解決這個問題,而這需要考慮幾件事,首先是需要創建一個模型,要能夠同時適用於所有應徵者與招聘者,另外則是因為職位發布與申請的時效很短,因此需要不停訓練模型避免過時,還有則是個人化模型的訓練規模,QA模型擁有高達數十億個係數,因此訓練的可擴展性非常重要。
QA模型目的,是要預測成員申請某項工作後,能夠獲得回應的可能性,也就是說,QA模型會預測招聘者積極採取行動的機率,積極行動包括查看應徵者的個人資料、發送訊息、邀請參加面試,或是最終提供應徵者工作。由於Linkedin求職市場龐大又多變,因此單一的全域模型可能不夠理想,無法捕捉到足夠的特質,所以模型需要針對每個應徵者和每個職位進行調整,加入QA模型個人化元件來解決這個問題。
由於平臺資料變動快速,模型可能很快就會過時,因此必須要頻繁地重新訓練模型。官方提到,每3周個人化模型的效果就會減半,而針對每個工作調整的個人化效果衰退得更快,因此模型需要頻繁地進行訓練,才能維持應有的效能,但求職者可能只花幾周的時間積極尋找工作,而職缺釋出的速度也很快,因此Linkedin必須用很快的速度更新模型,才能跟得上求職招聘節奏。
全域模型不需要頻繁的訓練,但QA模型個人化元件卻可以經常更新,Linkedin每天都會產生新的訓練標籤,自動重新訓練每個求職者與職位的個人化元件,並將其部署到生產中。
系統會收集招聘者每天與新的應徵候選人互動的事件,並將這些事件轉為訓練標籤,用來更新個人化元件。通常事件發生後,需要等上一段時間,系統才能得出正向標籤或是隱性的負向標籤,不過官方認為,最理想情況,還是將事件迅速地轉成訓練標籤,才能減少合併到模型的時間。
一般的做法是在應徵者申請工作一段時間後,根據參與度將其標記為正向或負向,另外,Linkedin也分析典型招聘者的反應,約在第一天就能確定30%為正向標籤,而當招聘者回應了多數職缺應徵者,剩下的申請人便會被系統標上負向標籤,要是14天後還是沒有任何參與,便會得出負向的結論。這樣的方法讓QA模型可以不斷更新資料集,確保模型品質。
Linkedin使用資料串流處理工具Apache Samza和Apache Kafka,建立接近即時的資料收集與訓練工作管線,能夠非同步訓練和更新個人化模型元件,花費的時間從原本需要數小時,降低到數分鐘就能完成更新。每天個人化模型都會使用新收集到的參與度資料重新訓練,以確保模型維持更新狀態,而全域模型因為變化慢,則是數周才會訓練一次。
目前LinkedIn已經將這個模型用於Job Seekers、Premium和Recruiter三個使用者等級,對Job Seekers使用者來說,只要有符合的職位,系統便會特別標示出來,對於Premium等級的使用者,還會顯示比其他求職者更具競爭力的工作,而Recruiter使用者,系統則會為招聘者依適合程度,排名申請人,並且在有高度符合需求的求職者應徵時,主動發出通知。
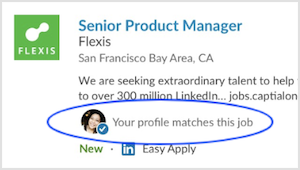
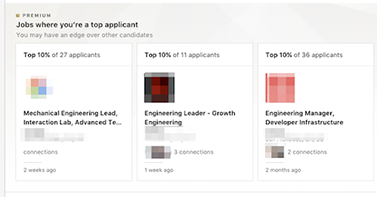
新模型部署之後,根據各項指標變化,該模型確實發揮作用,Linkedin提到,招聘者與應徵者的互動率有兩位數成長,而且確認招聘的比例提升,這代表應徵方與招聘方配對品質良好,另外,Premium等級的使用者的點擊率(CTR)也獲得提升。
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10