
臉書打造一套臨床試驗標準分析器,以美國國家醫學圖書館的臨床試驗開放資料庫來訓練,可加速找到合適的受試者。
臉書
重點新聞(0605~0611 )
臉書 臨床試驗 函式庫
臉書開源臨床試驗分析器函式庫,研究單位可快速找出受試者
隨著市面上越來越多因應疫情的臨床試驗出現,像是疫苗、藥物、療法等,臉書AI團隊也設計一套方法,能把尋找受試者的篩選標準轉換為機器可讀的格式,來自動搜尋複雜的試驗條件,加速尋找適合受試者的過程。
一般來說,藥廠要進行藥物或疫苗試驗時,必須尋找合適的受試者,但在美國,這個過程卻困難重重,根據塔弗斯大學研究,幾乎8成臨床試驗因找不到足夠或適合的受試者,而延遲或取消。特別是受試者的多元性不足,如種族等背景因素。為解決問題,美國國家醫學圖書館(NLM)建立了開放資料庫ClinicalTrials.gov,收集美國國內外33萬多筆試驗資料,包括受試者的篩選條件,如年齡、性別、種族、受試地點、採用的技術等。但臉書團隊指出,這個資料庫的文本為任意形式(Free text),而且包含複雜的醫學語言,每天還會新增3萬2千多例新資料,要整理非常複雜。
為此,臉書團隊利用NLM的資料,來訓練一套自然語言處理模型,可從試驗文字敘述中,抽取命名實體(如慢性病、過敏等)並進行分類。接著,他們再用另一套受試標準的模型,來找出命名實體與知識庫的關聯,最後再透過第三套模型,來辨識、預測知識庫中的受試標準屬性,並判斷該試驗適不適合特定受試者。經測試,這些模型都達到高階(SOTA)表現。(詳全文)

DeepMind 文字轉語音 EATS
DeepMind發表文字轉語音EATS,大幅降低監督式的標註工作
DeepMind最近以端到端的對抗學習方法,開發一套文字轉語音(TTS)模型ETAS,號稱媲美多階段和需大量標註來訓練的高階模型,此外還能克服傳統TTS模型的訓練問題。一般來說,TTS指的是將自然語言當作輸入值,再產出合成的人聲,但TTS的工作流程很複雜,需處理文字規範化、語言特徵統一、質譜圖合成和音波合成等。此外,在合成語音的過程中,還需要大量實際值(Ground truth)標註,來監督輸出值,無法直接利用文字或音素(Phoneme)來合成聲音。
而EATS的任務,就是要映射音素或字符序列,映射到24kHz的原始音訊。此外,EATS也有兩個子模型,來處理常見的文字語音長度不對稱問題,也就是透過對齊器來預測每個輸入值的持續時間,並產生音訊對齊的特徵,再透過解碼器處理對齊器的輸出值,取得完整的音訊。另一方面,EATS還利用生成器來學習較弱的訊號,大幅降低標註的需求。
後來,團隊用平均評價分數(MOS)來衡量EATS的語音質量,發現比起其他模型,EATS所需的監督工作大幅降低,表現也達4.083分,相當於GAN-TTS和WaveNet等高階模型。(詳全文)

工研院AIdea 荒野保護協會 海洋廢棄物
荒野保護協會開放海洋廢棄物快篩數據,徵求高手打造海洋廢棄物預測AI
荒野保護協會藉著工研院人工智慧共創平臺AIdea,在平臺上提出了臺灣海洋廢棄物的預測議題,吸引國內外211組AI好手來解題。進一步來說,這個議題是要讓參與團隊,透過AI來分析全臺海岸121個觀測站的海洋廢棄物分布狀況,為未來淨灘選址提供參考地點;此外,還要根據單一個測站的快篩調查數據,來預測鄰近測站的洋海廢棄物分布狀況,方便各站的人力調配。
工研院指出,目前的海洋廢棄物快篩調查抽樣,多以人工目測為主,十分耗時,因此荒野保護協會希望借助AI影像辨識,來掌握海洋廢棄物分布,把快篩調查、淨灘的人力分配到污染較嚴重的海岸。這次荒野保護協會在平臺上提出議題,透過AIdea團隊清洗去年海洋廢棄物的快篩調查資料,放到平臺上,讓不同團隊來解題。自去年11月上架至今,已有211組國內外AI團隊參與解題,AIdea也將準確度達75%以上的7位好手,推薦給荒野保護協會,以便日後的合作。(詳全文)
三軍總醫院 聯合學習 武漢肺炎
三總加入國際聯合學習計畫,要打造跨國武漢肺炎X光片AI判讀模型
三總日前參與Nvidia與麻州最大醫院系統合作健保Mass General Brigham的武漢肺炎聯合學習計畫(Federated Learning for COVID-19 Initiative)。這項計畫旨在聯手全球20多家醫療機構,利用聯合學習,在不分享患者資料和保護病患隱私的前提下,來打造醫療AI模型。
三總這次計畫將使用Nvidia提供的AI軟、硬體技術,來整合跨系統的醫療資訊數據。三總將收集武漢肺炎患者的胸部 X 光片,先訓練一套AI模型,來自動判讀病情嚴重程度,並判斷是否需提供氧氣和呼吸治療,作為緊急醫療決策的輔助資訊。(詳全文)
深度學習模型開發 Uber 抽象層
大幅簡化多框架深度學習模型開發,Uber開源深度學習框架抽象層Neuropod
Uber為了要讓自家應用程式可以靈活使用多種深度學習框架,因此開發了抽象層Neuropod,作為開發、訓練和部署機器學習模型的介面,讓研究員可更簡單應用各種框架、簡化模型部署。
Uber表示,要在機器學習堆疊中支援新的深度學習框架,需花大量人力和時間。為簡化這個過程,Uber開發了Neuropod,提供執行深度學習模型的統一介面,來簡化開發流程。進一步來說,Neuropod可消除重複性工作,因為Neuropod是TensorFlow這類框架與應用程式之間的抽象介面,應用程式可直接與Neuropod溝通,所以開發者只需增加Neuropod的支援,就能與多個深度學習框架相容。但如果只使用單一種框架,Neuropod就發揮不了簡化的作用。(詳全文)

Motion2Vec 機器人視覺 縫合手術
Motion2Vec強化深度空間學習,機器人看影片就學會縫合手術
Google大腦、英特爾和柏克萊大學合作開發一套Motion2Vec演算法,讓機器人看影片來學習外科手術相關任務,完成縫合、穿針和打結等動作,更實際應用於達文西手臂外科手術系統,在實驗室中成功穿針引線。
這套Motion2Vec演算法,是一種半監督式學習演算法,從影片中學習動作,在孿生神經網路中,將相似動作分割和度量學習結合在一起,習得一個深度嵌入特徵空間。實驗結果顯示,Motion2Vec的表現比目前最先進的方法都還要好,它在JIGSAWS資料集的公開影片中模仿手術縫合動作,達到了平均85.5%的分割精準度,而在對手術縫合影片進行模擬時,每個測試集觀察到的位置誤差為0.94公分。(詳全文)
Cloud 反向翻譯 Google 資源稀缺
反向翻譯讓少資源語言翻譯品質更上層樓!
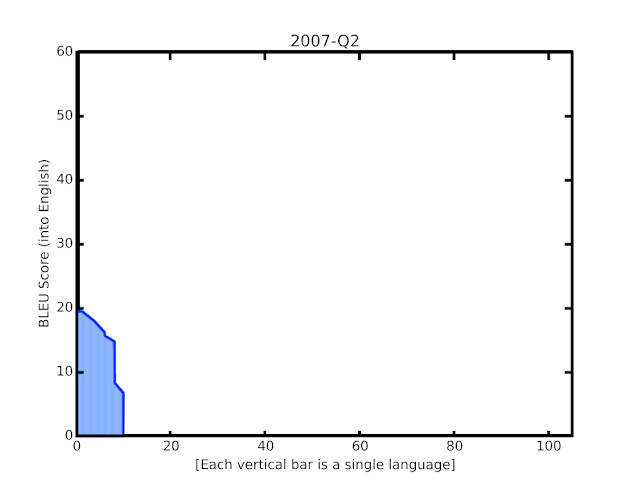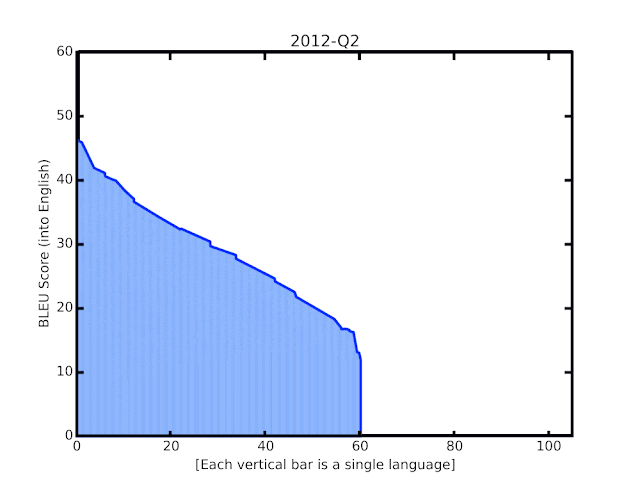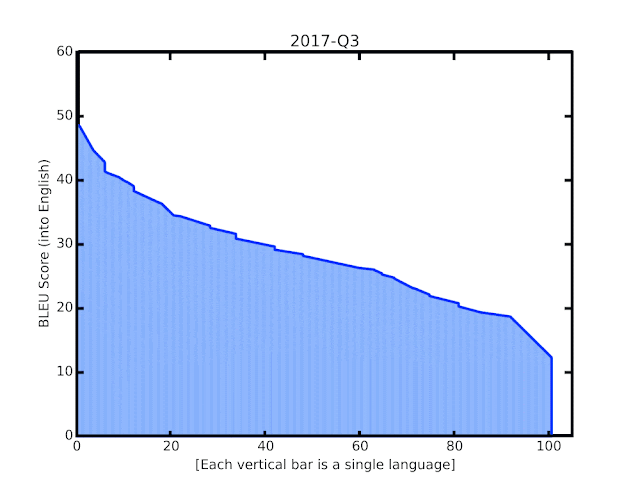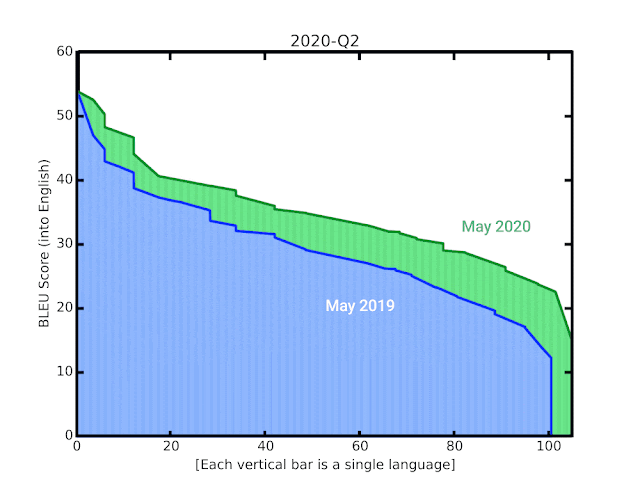
Google近期多項自動翻譯的技術改進,不只更換模型,也讓模型能透過網路上抓取的雜訊的資料來訓練,因此大幅提升翻譯品質,讓100多種語言翻譯到英文的的BLEU分數,平均提高5分,特別是低資源語言的翻譯。
進一步來說,Google採用反向翻譯技術,利用合成的平行資料,也就是將人類編寫的句子,來搭配神經翻譯模型生成的句子,作為模型訓練資料,來強化訓練。反向翻譯可使網路資源較少的語言,有更好的翻譯模型輸出。此外,Google也採用M4建模,來克服少資源的障礙;M4利用單一大型模型,進行所有語言和英語間的翻譯,可實現大規模遷移學習。這些技術改善了機器翻譯自動評估指標BLEU的分數,Google翻譯新模型的BLEU,比最初的GNMT模型平均高出5分,而50種少資源語言的BLEU分數,平均更是增加7分。(詳全文)
Amazon 對抗生成網路 虛擬換裝
Amazon靠AI新方法讓模特兒的服裝合成更自然
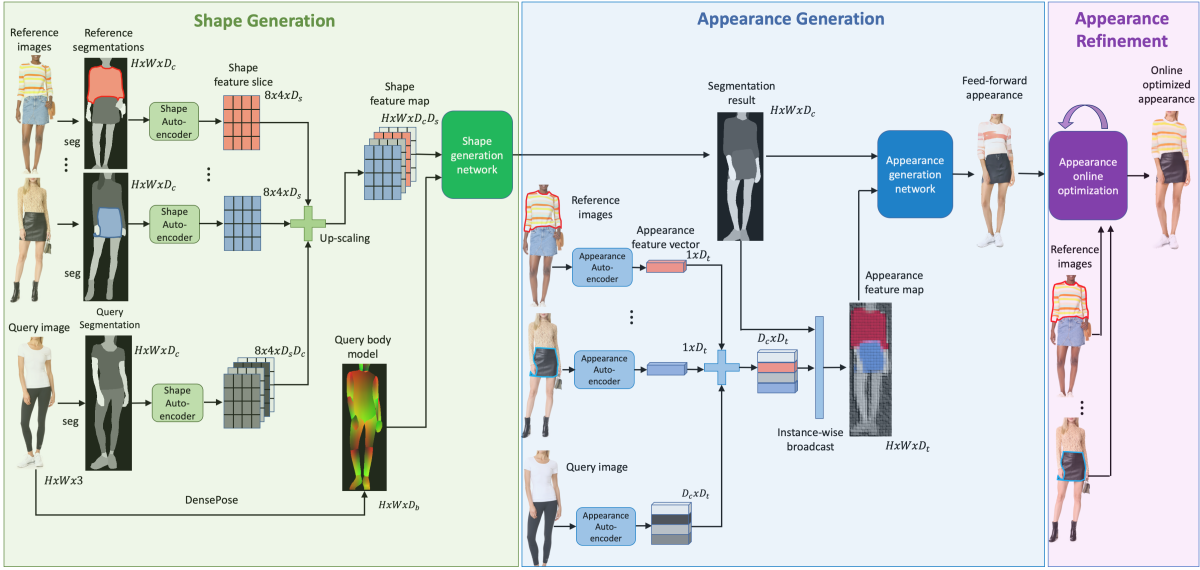
Amazon在電腦視覺和圖形辨識重要年度會議CVPR中,發表了一篇能合成服裝到模特兒身上的AI論文。這套系統名為Outfit-VITON,相當於虛擬試穿系統,可將參考照片中人物的穿著,合成到另一張照片的模特兒身上,研究人員指出,Outfit-VITON採對抗網路,由生成網路和判別網路的競爭產生最佳結果。
Outfit-VITON由三部分組成,形狀生成模型、外觀生成模型以及外觀修正模型,形狀生成模型會圈出要試穿的衣服形狀,並計算試穿模特兒的身材和動作。接著再輸出至外觀生成模型,來結合這個輸出的結果,成為模特兒穿著指定服飾的照片;再來才由第三個模型微調,保留商標和特殊圖案。團隊表示,這個系統比以前的系統產生更自然的結果。(詳全文)
圖片來源/臉書、Google、DeepMind、Amazon、Uber
AI趨勢近期新聞
1. SAS釋出免費AI環境,要加速科學家尋找防疫策略
2. Google釋出Android 11測試版,同時更新Android Studio如機器學習匯入功能
3. OpenAI發表超大自然語言模型GPT-3的API,要促進商用價值
4. 臉書Deepfake人臉辨識挑戰賽得主達82%準確率
資料來源:iThome整理,2020年6月
熱門新聞

2026-03-06





2026-03-06

2026-03-09