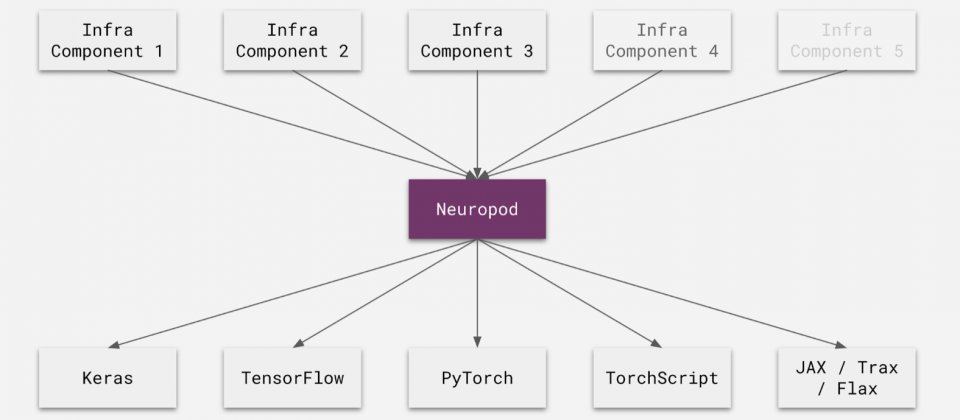
Uber為了要讓自家應用程式可以靈活使用多種深度學習框架,因此開發了抽象層Neuropod,作為開發、訓練和部署機器學習模型的介面,Uber提到,這個框架的目的,是要讓研究人員可以更簡單地應用各種框架建置模型,並簡化模型的部署。
Uber為了發展自動駕駛的軟體,因此尋求各種新方法來改進模型,而這代表研究人員要廣泛地嘗試使用各種不同的深度學習框架,包括各式新框架,以及TensorFlow和PyTorch等現有框架及其更新版本,Uber表示,他們希望研究人員可以靈活地選用適合他們的工具。不過,要在機器學習堆疊中支援新的深度學習框架並非簡單的事,需要花費大量的人力資源和時間。
因此為了簡化這個過程,Uber便開發了Neuropod,這是建立在現有深度學習框架之上的抽象層,其提供了執行深度學習模型的統一介面,簡化人工智慧應用程式開發,Uber舉例,要將TensorFlow電腦視覺模型整合到服務中,需要在服務以及其他相關工具中,添加對TensorFlow API的支援,當改天他們也想使用PyTorch模型時,便需要重複進行相同的工作,如果想要靈活使用多個深度學習框架,就必須要重複多次相同的工作。
應用Neuropod則可消除這類重複性工作,因為Neuropod是TensorFlow這類框架與應用程式之間的抽象介面,應用程式不直接使用TensorFlow API,而是與Neuropod溝通,所以開發人員只需要增加對Neuropod的支援,就能與多個深度學習框架相容。
Neuropod規範了輸入與輸出的描述,包括名稱、資料類型等,由於抽象化實作,因此只要用來解決相同問題的模型,就可以互換,即使用不同的框架和程式語言也沒關係,例如用戶想要以C++搭配使用PyTorch模型,Neuropod則會在後臺啟動一個Python直譯器,並與該模型溝通。
Neuropod會打包模型,包括原始模型、元資料、測試資料以及自定義操作,應用程式只呼叫無關框架的API,而Neuropod會把這些呼叫轉換成對底層框架的呼叫,最後,Neuropod匯出模型並建立指標工作管線,以定義基準來比較模型效能。
過去一年間,Uber已經使用Neuropod開發了數百種模型,包括預測乘車抵達時間,以及自動駕駛的物件偵測等模型,Uber提到,他們將來的版本會加入版本控制功能,在匯出模型的時候可指定框架版本,並且以容器化的方式,對模型進行更多的隔離。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02