,邊指的是兩個相鄰點與一組代理,也就是移動中的機器人。接著,團隊將這個問題拆解為一系列的視窗化MAPF實體,並透過一個個視窗化MAPF解決器,在特定時間內解決相撞問題。")
團隊將MAPF視為圖形問題,圖中包含了節點和邊,節點指的是不斷改變的目的定點(Location),邊指的是兩個相鄰點與一組代理,也就是移動中的機器人。接著,團隊將這個問題拆解為一系列的視窗化MAPF實體,並透過一個個視窗化MAPF解決器,在特定時間內解決相撞問題。
Amazon
重點新聞(0515~0519)
Amazon 機器人 路徑規畫
物流倉庫千臺機器人行走不碰撞!Amazon發表路徑尋找AI框架
Amazon機器人研究所聯合南加州大學,發表一套多代理路徑尋找(MAPF)框架,可讓1,000臺機器人到達不斷改變的目的地,而且不會相撞。一般來說,MAPF是許多自動化系統的核心,比如自駕車、無人機或是電玩中的AI角色,但對擁有數十萬臺揀貨機器人的Amazon來說,MAPF可能改善物流揀貨流程。
在Amazon的研究中,團隊將MAPF視為圖形問題,圖中包含了節點和邊,節點指的是不斷改變的目的定點(Location),邊指的是兩個相鄰點與一組代理,也就是移動中的機器人。在一個時間步長(Timestep)中,每個代理可選擇到鄰近的點,或是待在原地。要是兩個代理都想在同一時間步長中,到達相同的定點,就會相撞。
接著,團隊將這個問題拆解為一系列的視窗化MAPF實體,並透過一個個視窗化MAPF解決器,在特定時間內解決相撞問題。也就是說,這個方法可在每個時間步長中,更新每位代理的起始點和終點,並計算每位代理到達所有定點所需的步長。此外,該演算法也會持續分配新的目的定點給代理,並找出不會相撞的路徑,讓代理按照順序行走。後來團隊進行實驗,將物流倉庫映射到33x46的網格,其上有16%的障礙物,結果發現,團隊的方法不僅不讓機器人碰撞,其吞吐量還比其他方法高。此外,這套演算法最多還可應用於1,000位代理,且不發生任何碰撞。(詳全文)
Google 資料回音 模型訓練加速
Google改進資料回音方法,不讓GPU空等、加速AI訓練快3倍
專用加速器如TPU、GPU可提高神經網路的訓練速度,但卻無法加速上游資料處理,像是硬碟I/O和資料前處理。為解決這個問題,Google團隊改進了去年發布的資料回音方法(Data echoing),透過重複使用初期工作流程產出的資料,而非等待新資料的出現,來善用閒置的加速器資源,加速訓練時間。
進一步來說,這個方法可將資料複製到工作流程中的隨機緩衝區,只要某個環節產生瓶頸,比如批次前後或資料擴充等,就可立即使用。之後,Google針對影像分類、自然語言建模和物件辨識等三個任務,利用5個AI模型來測試資料回音表現,結果顯示,資料回音可用更少的新樣本來達到目標,且在ImageNet的ResNet-50訓練任務中,資料回音可提高訓練速度達3倍。(詳全文)

克里夫蘭醫學中心 疫情預測 武漢肺炎
美國大型醫學中心藉助AI,制定防疫計畫
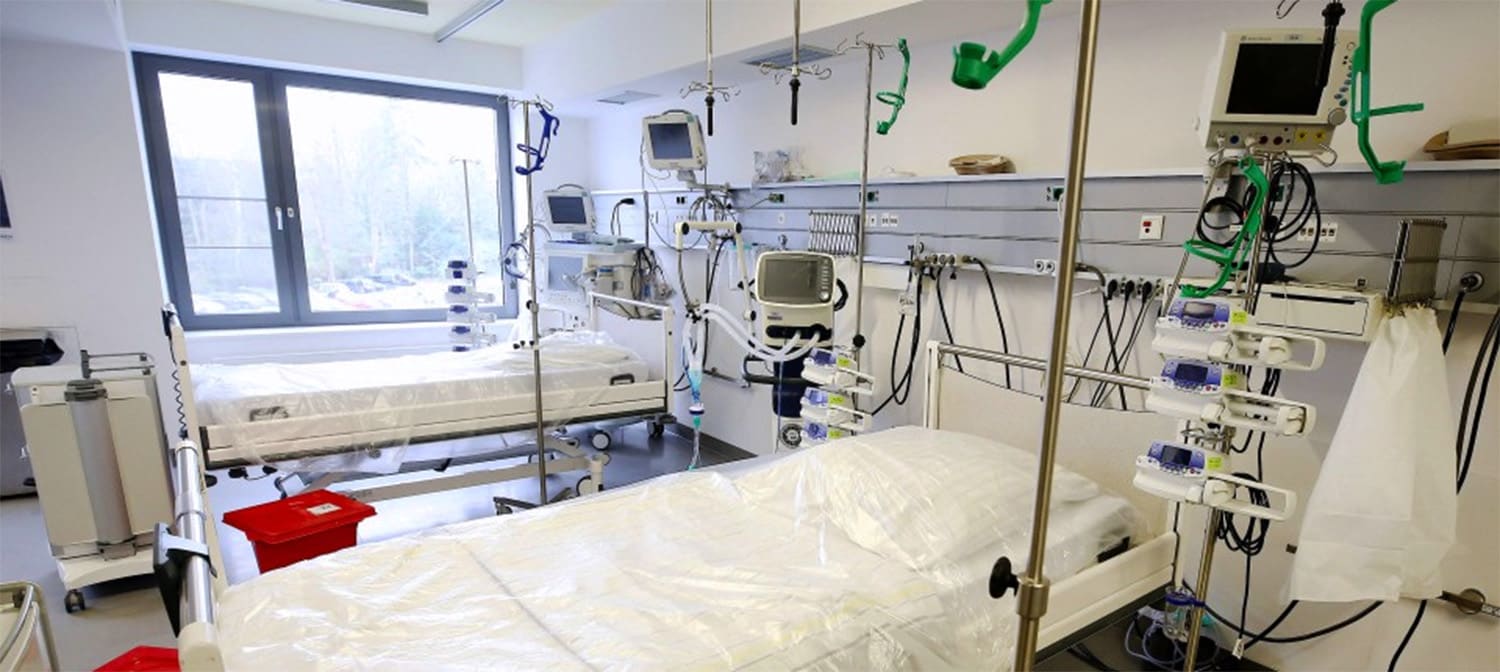
美國大型醫學中心克里夫蘭醫學中心聯手數據分析大廠SAS,以賓州大學的開源模型為基礎,來開發流行病學SEIR模型,可預測武漢肺炎(COVID-19)患者人數、所需加護床位、醫護人員防護設備和呼吸器數量等。雙方也將程式碼於GitHub上釋出。
進一步來說,雙方利用醫學中心資料來訓練這套模型,可分為最好、最壞、最有可能發生等三種情境,此外,該模型可彈性根據地區人口健康狀況、人口統計學差異和各個州政府的管控措施,來控制參數,隨時修正。而克里夫蘭醫學中心,也根據該模型的最壞情境,啟動準備計畫,在教育園區內搭建了1,000張病床給不須急救的患者。(詳全文)
影像處理 邊緣運算 AI晶片
以色列AI晶片新創聯手鴻海,要攻AI影像邊緣運算市場
以色列AI晶片新創Hailo攜手鴻海與影像應用SoC供應商Socionext,要共同打造AI邊緣運算影像處理解決方案。三方將利用自己的專長,比如鴻海負責打造高密度運算、高效能且無風扇的邊緣運算裝置,來搭載Socionext平行運算處理器,以及Hailo的深度學習處理器。
其中,高效能裝置除了低功耗,還可即時處理20多條路的串流影像,內建的高密度運算核心和VMS 影像管理系統可應用於影像分類、人體姿勢偵測等。鴻海表示,這次解決方案鎖定動態影像分析,要來強化物件偵測的處理能力。(詳全文)
智慧製造 電極鋁箔 品檢
管理YAML檔案更輕鬆,AWS開源釋出K8s開發管理工具cdk8s
AWS釋出用於Kubernetes(K8s)的雲端開發套件cdk8s,可讓使用者在K8s叢集中,更簡單地建置和維護工作。進一步來說,K8s應用程式是透過靜態YAML資料檔案來定義,YAML是一種人類可讀的檔案格式,但每次建立新應用程式,就需要編寫大量的樣板配置,因此隨著專案發展,YAML管理會越來越複雜。
為解決這個問題,AWS兩年前就推出AWS CDK,來簡化開發程序。現在,AWS將CDK的概念,擴展應用到K8s上,釋出全新專案cdk8s。cdk8s一樣可讓使用者利用熟悉的程式語言,來定義K8s應用程式和可重複使用的元件,產生標準的YAML檔案;不管用戶在地端或任何雲端部署,都可以利用cdk8s來定義Kubernetes叢集應用程式。(詳全文)

Cloud 超級電腦 臺灣AI雲 科技部
持續提供超級算力!國研院將TWCC半數資源技轉成為新創
為了讓科技部與民間業者共同建置的臺灣AI雲(TWCC),在超級電腦計畫結束後能繼續提供服務,國研院決定將一半的運算資源與軟體服務,技轉成立為一家新創公司,交由專業的開發與維運團隊來發展雲服務,以商業模式提供業界租用:而另一半,則同樣透過國網中心提供給學研界來使用。
臺灣AI雲是國研院國網中心以超級電腦臺灣杉二號的運算資源為基礎,所推出的雲端運算服務,可支援OpenStack、Kubernetes和Slurm等架構。TWCC從去年商轉至今,已有350多組產學界專案使用。而這家正在籌辦的新創公司,將由國研院、華碩、廣達、臺哥大成立,預計今年底正式成立並提供服務。(詳全文)
Meta-Dataset 少樣本學習 基準測試
Meta-Dataset提供多元的少樣本學習基準測試
Google釋出一款少樣本(Few-shot)學習資料集Meta-Dataset,提供大規模且多樣的基準,用來量測不同圖像分類模型的表現,此外也附上用來研究少樣本學習的框架。
Google指出,雖然目前有不少少樣本的研究,但其中的基準測試,都難以有效評估每個模型的優點。為解決這個問題,Google利用10個公開圖像資料集建立Meta-Dataset,並公開程式碼和筆記本,展示如何透過TensorFlow和PyTorch來使用資料集。此外,Meta-Dataset還包括對現存少樣本圖像分類模型,進行初步研究的成果。(詳全文)

Nvidia GPU 模型訓練
跨界合作!開發者可在Spark上用GPU加速模型訓練
Nvidia聯手開源社群Spark,在即將發布的資料運算引擎Apache Spark 3.0中,支援端到端GPU加速功能。Nvidia指出,Spark 3.0建立在開源GPU機器學習平臺RAPIDS上,可大幅提升資料提取、轉換和載入資料的效能。
Spark 3.0可讓資料科學家和工程師在SQL資料庫中運用GPU資源,進行ETL資料處理工作負載;此外,AI模型訓練,也可在同一個Spark叢集上處理,不必在獨立的基礎設施或程序中執行。Nvidia表示,這樣的改進可以提升整個資料科學工作管線效能,使用者不需要更改現有企業就地部署或雲端平臺上的Spark應用程式,就能從資料湖的ETL到模型訓練都獲得加速。(詳全文)

圖片來源/Google、克里夫蘭醫學中心、AWS、Nvidia
AI趨勢近期新聞
1. 效能可達5 Petaflops!Nvidia新一代AI超級電腦系統問世
2. 臉書最新TTS系統可只用CPU即時生成語音
3. 微軟釋出Cosmos DB Cassandra API原生殼層CQLSH
4. 靠AI挖掘新口味!百年美國食品商用AI分析數十億個資料點,從40萬種配方開發出3款新調味品
資料來源:iThome整理,2020年5月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02