
Google之前就推出適用於Pixel手機的新型錄音應用程式Recorder,這個錄音程式不只可以將語音轉譯成文字,還可以視覺化地顯示聲音類型的分類,另外,在錄音結束用戶要輸入標題時,Recorder也會提供建議標籤。這些功能,都是Google應用裝置上機器學習技術開發,現在揭露了背後的細節。
將語音轉錄成文字的功能,其應用的技術在早前就已經趨於成熟,Recorder可以使用裝置上自動語音辨識模型,即時地轉譯語音,Google提到,除了增加模型穩定度,使其能可靠地轉錄數小時的錄音之外,他們還將單詞對應到時間戳記以索引對話,用戶可以點擊轉錄出來的單詞,並且從對應時間點開始播放錄音,用戶也能搜尋單詞,並精確地跳到錄音提到該單詞的時間點。
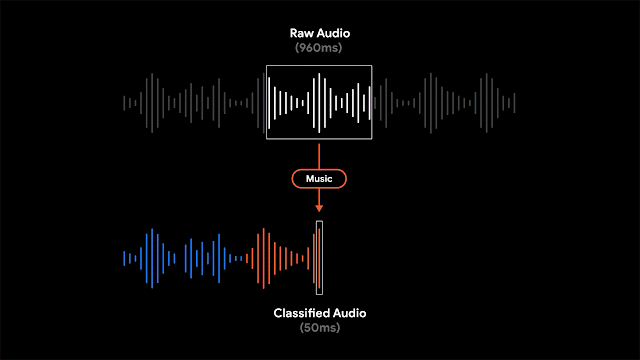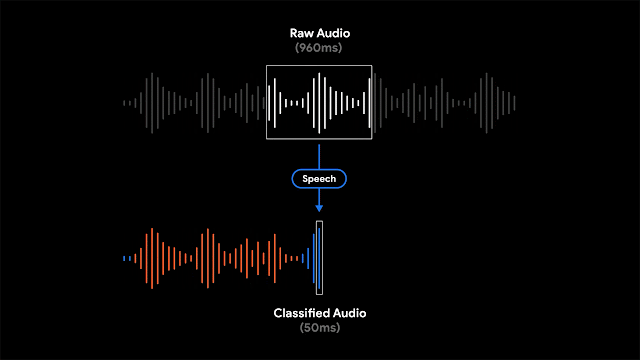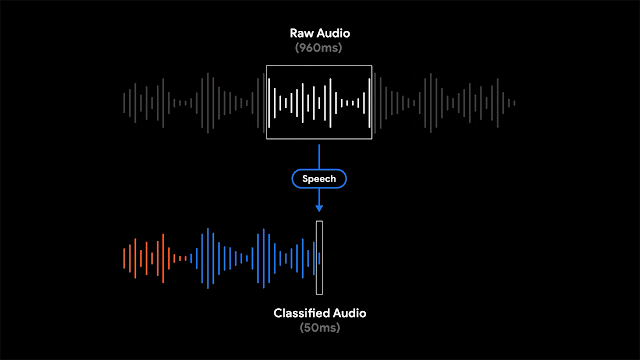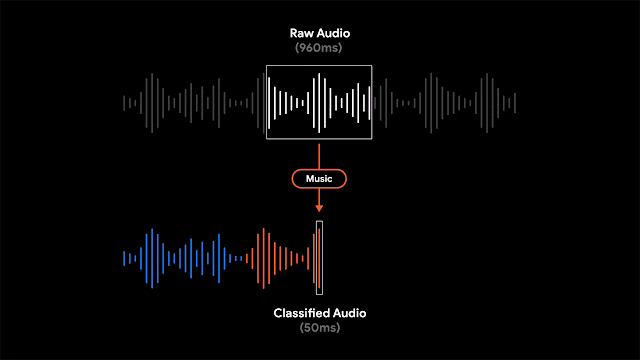
雖然顯示錄音的文字紀錄,可讓使用者搜尋特定單詞,但Google提到,以視覺化標示特定時刻或是聲音的錄音段落,對於長時間的錄音來說,用戶能更容易進行搜尋。因此Recorder會將聲音以波型表現,並且用不同顏色來表示不同的聲音類型,像是狗叫聲或是樂器演奏就會以不同的顏色區分。
實際情況通常是同一個時間點,Recorder可能會錄到多種聲音,Google會將波型以最具代表性的聲音顏色著色。Recorder辨識聲音類型的方法,會偵測部份重疊的960微秒聲音音框(Frame),來判斷50微秒區間的聲音類型,Google提到,以較小50微秒偏移量分析處理960微秒視窗中的內容,不容易出錯且能精確的找出視窗開始時間與結束時間。
另外,當音訊錄製完成之後,Recorder會挑選最具記憶性的內容作為建議標籤,用戶可以快速地應用這些標籤撰寫成標題。而為了能夠在音訊錄製結束之後,馬上能夠提供建議標籤,Recorder在轉錄音訊的時候,便會即時進行分析。
Recorder會計算單詞出現的次數以及在句子中的語法作用,並且大寫專有名詞,接著會使用詞性標記程式,這是一個根據句子文法標記每個單詞的模型,來偵測用戶更容易記住的一般名詞與專有名詞,Recorder以對話資料以及字詞頻率和特性等文字特徵訓練決策樹,計算單詞和雙字詞分數,在濾掉禁用詞與髒話,最後輸出前三名的結果。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02