
清大研究團隊提出了新的CNN架構HarDNet,由於HarDNet的資料搬運次數較少,所以可以在低錯誤率、高運算量的情況下,保持快速的推論速度。
攝影/翁芊儒
自駕車上路的關鍵是,得先快速、準確分辨出路上人、車和物體,能夠更快更準確地進行影片的圖像語義分割 (Semantic Segmentation),決定了操控AI安全駕駛的反應能力,如何單靠車上AI主機提供到毫秒級辨識推論,是自駕車AI的一大挑戰。清大一個研究團隊,最近開源了自己改良的新CNN架構,找到了能加快推論速度的關鍵作法。
最近清大資工系教授林永隆帶領的研究團隊,以DenseNet為基礎,開發了一個低記憶體資料流(Low Memory Traffic)的CNN架構,稱為HarDNet。研究團隊指出,運用該架構訓練的模型進行影像分類任務,推論時間比常用的ResNet-50架構縮短了30%,若是進行物件偵測與識別的任務,則比SSD-VGG縮短了45%。而這個架構在今年10月底的ICCV會議發表,且已在GitHub開源。
清大研究團隊成員阮郁善表示,Memory Traffic是指資料進出記憶體的次數。以DenseNet來說,會造成大量資料進出記憶體,是因為該架構中每一層都有捷徑(Shortcut)的連結,這也意味著,每一層擷取的特徵值(Feature),都會保留到最後一層來運算,而且,保留下來的特徵值也會到下一層擷取更細節的特徵值,如此一來,造成資料搬運次數多,就會耗費許多運算時間。
因此,研究團隊減少了DenseNet架構中,層數(layer)之間的捷徑,來降低資料搬運次數、加快運算時間,不過,捷徑減少後,由於擷取的特徵值變少,模型準確率也會下降。於是,研究團隊也改變了DenseNet每一層的權重數,也就是針對捷徑連結更多的layer,來增加運算量、擷取更多的特徵值,藉此維持模型準確率。而這個改良版的DenseNet模型,也被重新命名為HarDNet。

如圖所示,由於DenseNet的捷徑連結多,造成資料搬運次數多,所以需要較長的運算時間,但改良後的HarDNet,減少了捷徑的同時,也調整了每一層的權重數,能在維持辨識準確率的同時加快運算速度。
研究團隊也將U-HarDNet70模型運用在高解析度(1024*2048)的即時影像分割工作上,來驗證該架構的高推論速度。比如在Nvidia GTX 1080ti的環境下,能達到53 fps(Frame per second,每秒幀數)的推論速度,且達到76%的準確率。阮郁善表示,儘管還有可以達到更高準確率的架構,但如果將運算速度也納入考量,「U-HarDNet70的綜合表現更好。」
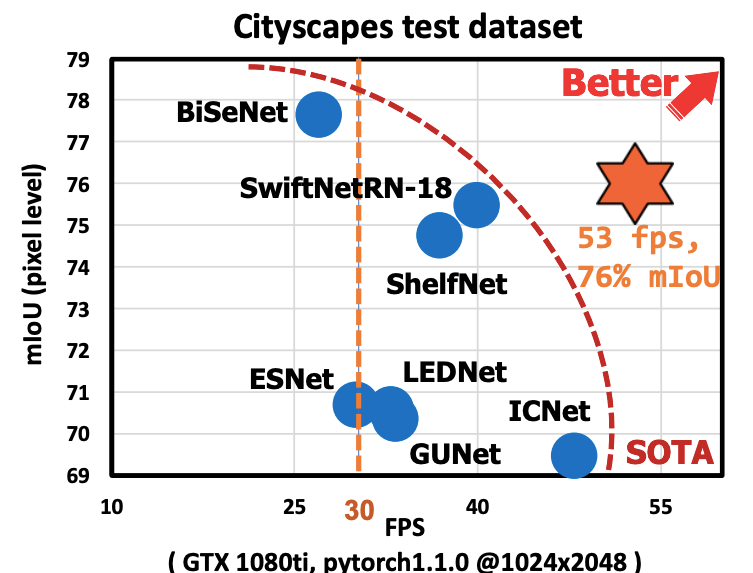
與其他架構相比,U-HarDNet70能在53 fps的推論速度下,達到76%的準確率。
研究團隊也將HarDNet與一般常見CNN架構相比較,HarDNet可以在低錯誤率、高運算量的情況下,仍然保持快速的推論速度。阮郁善表示,「其他研究者可能想追求,運算量不要太大,模型推論可以跑更快,但我們是點出來說,一直追求較低的運算量不一定跑比較快,就像HarDNet的運算量高,但是因為資料搬運次數較少,所以推論速度比DenseNet快了三成以上。」
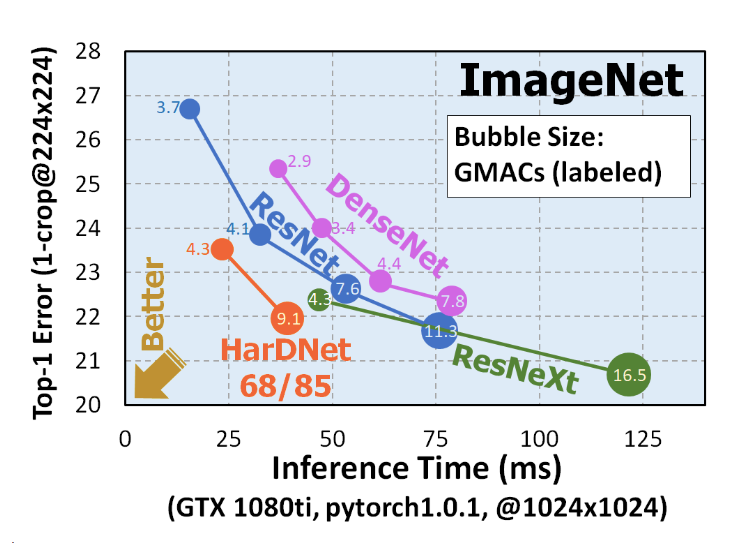
如圖所示,左側Top-1 Error是指辨識錯誤率,數值越低越好;Inference Time是指推論時間,數值越低越快;而圖中圓圈的數值,是指運算量(單位:Giga MACs)。而HarDNet的表現,可以在低錯誤率、高運算量的情況下,保持快速的推論速度。
因此,HarDNet適合如高解析度、即時影像分析等運算量大的應用,如自動駕駛、醫療診斷、安全識別、人機互動等。 而該架構也已經在GitHub上開源。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-25