Netflix釋出內部專為資料科學家設計,以人為本的資料科學應用開發框架Metaflow,除了可讓使用者靈活地進行模型開發之外,也與AWS服務良好整合,可快速存取在S3上的資料,而資料科學家除了可自行開發演算法之外,也能結合使用AWS上的機器學習服務。
Metaflow框架已經在Netflix內部應用兩年,被拿來開發了數百個資料科學專案,案例包括應用於自然語言處理以及操作搜尋等。
Metaflow來自機器學習基礎設施團隊,對內部資料科學家進行調查的結果。他們發現過去所提供的工具,已經足夠讓資料科學家創建出各種應用,但比起底層的架構,資料科學家更在意建模方法的自由度,包括模型的運作、特徵工程以及模型的開發,在許多情況下,資料科學家希望可以在生產中操作模型,以快速地進行除錯或是迭代。
機器學習基礎設施團隊歸納資料科學家的需求,開發語言Python是他們的基本配備,是資料科學的通用語言,而且他們也希望以Python來表達邏輯想法,像在Jupyter Notebook編寫程式碼的方式,另外,資料科學家也不在意物件的階層、封裝問題,或是與目標無關的API工作。
為此,機器學習基礎設施團隊開發了Metaflow,並將Metaflow設計成簡單的Python函式庫,資料科學家可以將工作流程表達為有向無環圖(Directed Acyclic Graph,DAG)。(下圖)機器學習開發流程的範例,該流程會訓練兩個版本的模型,並選用得分最高者。
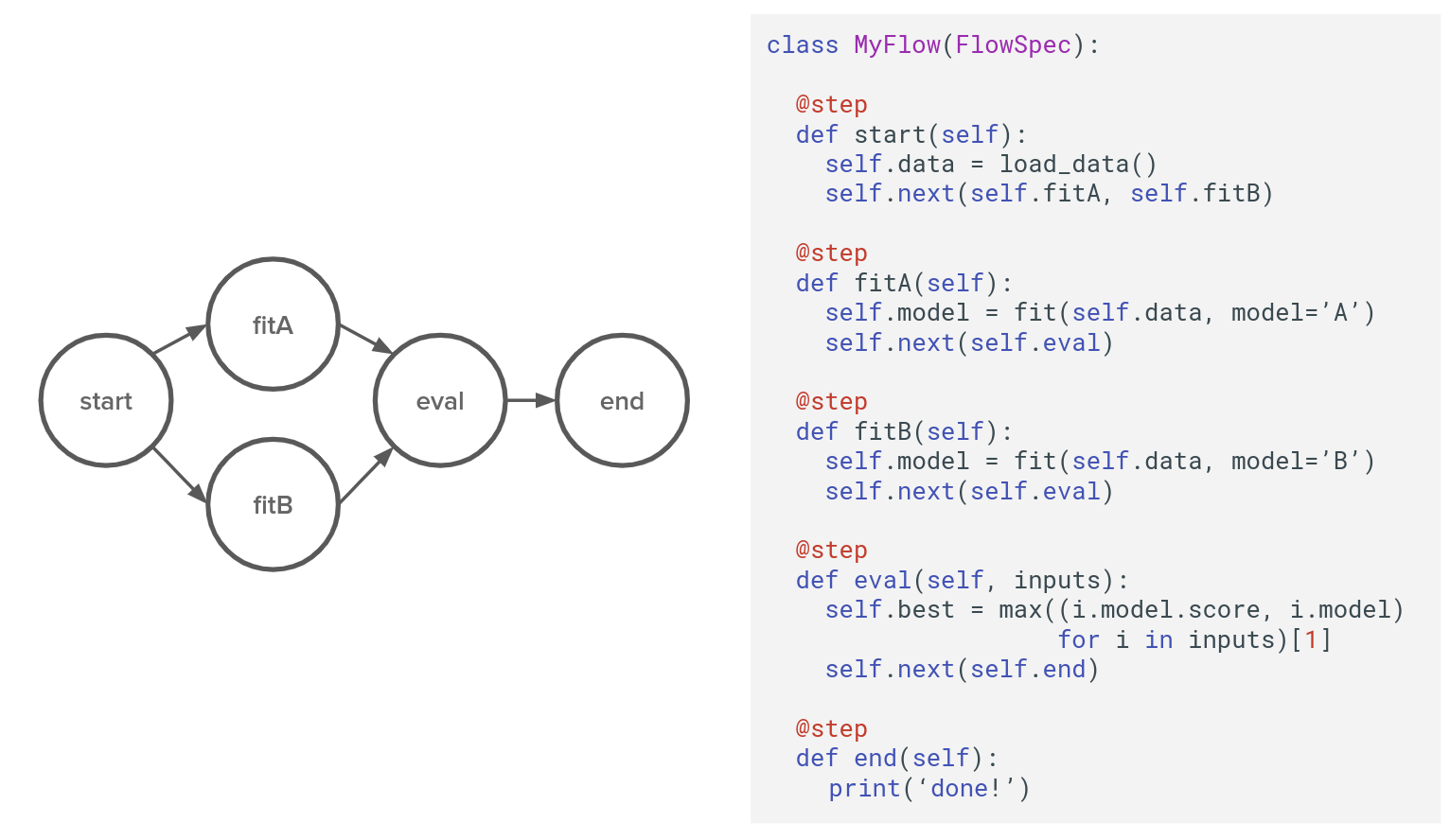
Netflix提到,Metaflow充滿以人為本的細節,雖然Apache Airflow或Luigi等工具,也可以執行由任意Python程式碼所構成的DAG,但是在Metaflow中,資料和模型是以普通的Python實例變數儲存,而且即便是在分散式運算平臺上執行也沒問題。另外,在其他框架,將物件載入以及儲存交由使用者控制,也就是說,使用者需要決定保留與捨棄的內容,Metaflow則消除了這些決定的負擔。
而Metaflow本身就為雲端設計,能夠彈性的使用雲端運算以及儲存資源,由於Netflix長期為AWS的大用戶,因此Metaflow與AWS服務良好整合,包括可為Amazon S3中的所有程式碼和資料自動產生快照,提供版本控制和實驗追蹤的解決方案。
Metaflow還綑綁了一個高效能S3客戶端,可快速地將資料載入到資料科學工作流中,快速進行開發迭代。而且除了資料科學家自己編寫的功能之外,也可以使用AWS機器學習服務Sagemaker,以取用各種模型的高效能實作,或是應用分散式訓練。
Metaflow良好地支援本地端開發,讓資料科學家像是撰寫Python腳本一樣,快速地在本地端電腦開發並進行測試。Netflix提到,通常最終資料科學工作流程開發結果,最終會寫入到表格中,由其他儀表板取用,部分時候將最終模型部署成微服務,以進行即時的預測,甚至也會把該資料科學工作流程鏈結其他流程,成為大流程的一部分,而Metaflow可支援各式的生產部署。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02