
臺灣IBM雲端運算暨認知軟體事業部資深技術顧問李維倫現場示範AutoAI,指出系統可進行整體學習,將數個模型集結訓練,以得到更好的預測結果。訓練完後,AutoAI也會顯示模型排名和分析報告,讓專業資料科學家和素人資料科學家各取所需。
攝影/王若樸
IBM在臺展示幾個月前推出的雲端AI模型自動化服務AutoAI測試版,臺灣IBM雲端運算暨認知軟體事業部資深技術顧問李維倫指出:「AutoAI就像AI訓練師,使用者完全不需要撰寫任何程式碼,就可開發和部署AI模型。」
AutoAI涵蓋了前置作業、AI模型開發、訓練、調校和部署,大幅縮短AI模型的工作流程(pipeline)。李維倫指引用IBM研究部今年3月發表的一份報告,指出機器學習工作流程不是一次性運算,而是要不斷累積新資料並進行優化,但這個優化維運工作就需要1至6位專業資料科學家來維持。因此,「透過程式自動維運、不斷調校AI模型,就可加速AI周期。」
從資料準備到部署模型,都能自動優化
AutoAI整合了IBM自家AI開發工具Watson Studio和AI模型執行工具Watson Machine Learning,後者可用來部署、執行AI模型。李維倫表示,AutoAI的核心概念是為AI而AI(AI for AI),可細分為3大重點:以AI設計AI、以AI優化AI、以AI治理AI,在建模階段,AutoAI可搜尋神經網路架構、挑選適合的模型,接著在訓練階段,能夠自動調整參數和特徵值來優化模型表現,而模型部署後,還可以隨時調校、管理AI模型。
AutoAI在流程上,可分為前置準備、模型選擇、超參數調整和優化(HPO)、特徵工程、再次調整和優化超參數,以及整體學習(Ensemble Learning)、模型評估與部署。
進一步來說,在前置階段,當使用者將經標註的原始資料集輸入AutoAI後,系統會利用內建的演算法,來清理、分類這些資料,然後根據資料屬性和預測目標,來找出最佳的預處理策略。策略制定好後,就進入模型選擇階段,系統會根據輸入資料特性,來找出前幾名合適的演算法模型(Top-K Estimator);AutoAI提供的演算法模型,可分為分類模型和回歸模型兩大類,其中,分類模型包括了決策樹、XGBoost等30種分類器,而回歸模型則包括了Lass、線性回歸等44種模型。
選完模型之後,AutoAI會根據這些模型,來選定超參數(Hyperparameter),並進行模型訓練、調整參數。之後,隨著新資料加入,AutoAI會針對新資料進行特徵工程(Feature Engineering),找出最佳的資料轉換序列、產生新特徵值。李維倫強調,過去,找出新特徵值仰賴專業資料科學家多年經驗,而AutoAI可自動從資料中尋找影響模型表現的關鍵特徵,大幅縮減AI工作流程時間。
特徵工程完成後,系統會再次進行超參數調整和優化。再來,AutoAI會開始執行整體學習,集結訓練中的多個模型,來提升最後的預測能力。
IBM近日也推出IBM Cloud Pak for Data平臺,重整AI產品組合,要讓企業透過該平臺在任何雲端實作AI,擴展Watson Anywhere的策略,也將AutoAI工具納入這個平臺。
李維倫指出,使用者可透過AutoAI的模型評估和排行榜來檢視模型表現(下圖1),比如模型準確度、召回率和F1量測值等。而對專業的資料科學家來說,更可從模型評估的分析報告中(下圖2),找出影響模型表現的關鍵。
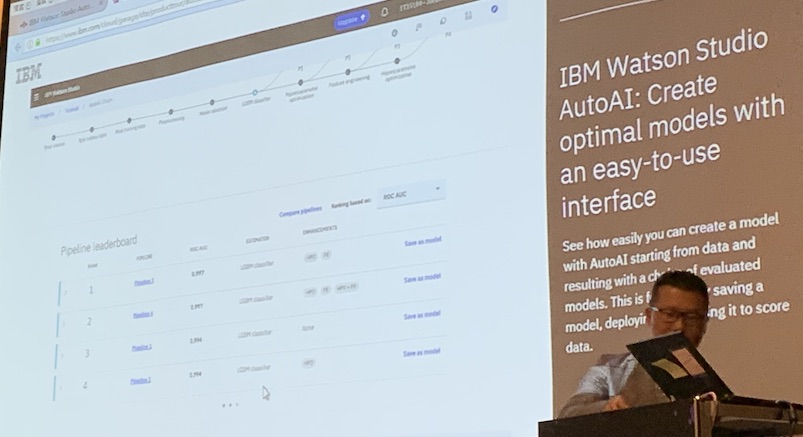
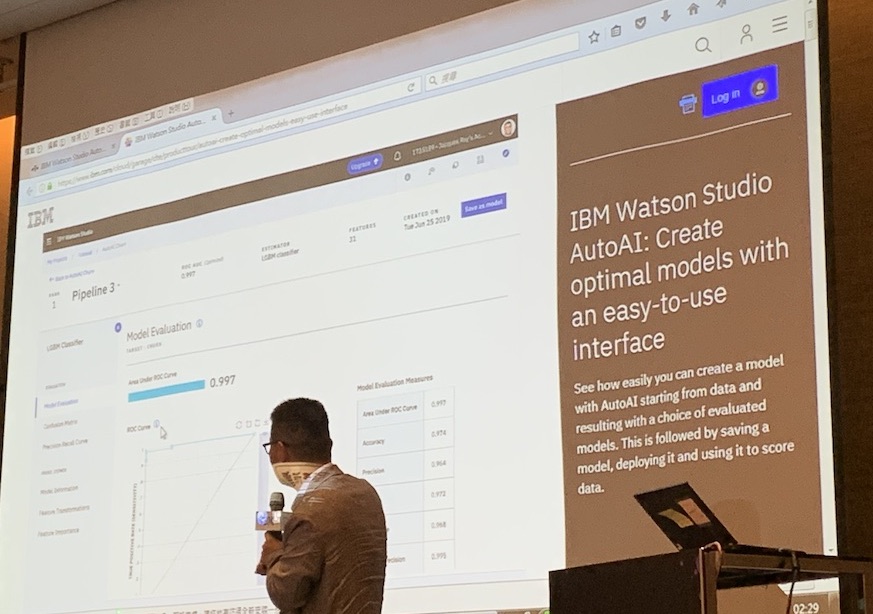
最後,使用者可將表現最好的模型存檔,並利用存檔後產生的API,來直接部署模型。雖然AutoAI目前只有雲端版,但IBM將於近期釋出CP4D v2.5本地版。文◎王若樸
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02