松果購物除了用AI來強化商品搜尋與推薦功能,接下來還要用來提高客戶留存率和忠誠度。
松果購物
重點新聞(0927~1003)
松果購物 商品搜尋 推薦模型
用深度學習抓緊隱式回饋,松果購物推薦專區交易額翻倍
成立3年的平臺電商松果購物近日公開AI策略與成果,今年鎖定搜尋和推薦兩大AI應用,首先在搜尋部分導入機器學習排序(Learning to rank),利用商品和對應搜尋關鍵字的點擊量、收藏量、購買量和商品描述等特徵,來訓練、測試數十種模型,像是隨機決策森林、LightGBM、ListNet等,用來優化商品搜尋的結果排序。改進後,透過搜尋而購買的商品中,超過4成來自搜尋結果前10項商品,而這10項商品的點擊率更提高了40%。
至於推薦部分,松果購物結合了傳統矩陣分解和深度學習來建立用戶的個人化推薦商品清單。因為用戶的使用行為屬隱式回饋,比如瀏覽、搜尋、收藏、購買等,松果購物採自動編碼、深度學習推薦模型(DeepFM)、深度興趣網絡(DIN)和加權矩陣分解(WMF)等方法來訓練模型,成果超過原有推薦系統的演算法模型,讓推薦清單中的購買召回率達3、4成,也一併帶動推薦專區「猜你喜歡」的交易額,成長了200%。接下來,松果購物要將AI用來提高顧客忠誠度和留存率。(詳全文)
DeepQ KG-GAN 醫療小數據
臺灣DeepQ發表新知識型AI模型KG-GAN,要讓醫療小數據也有高準確度
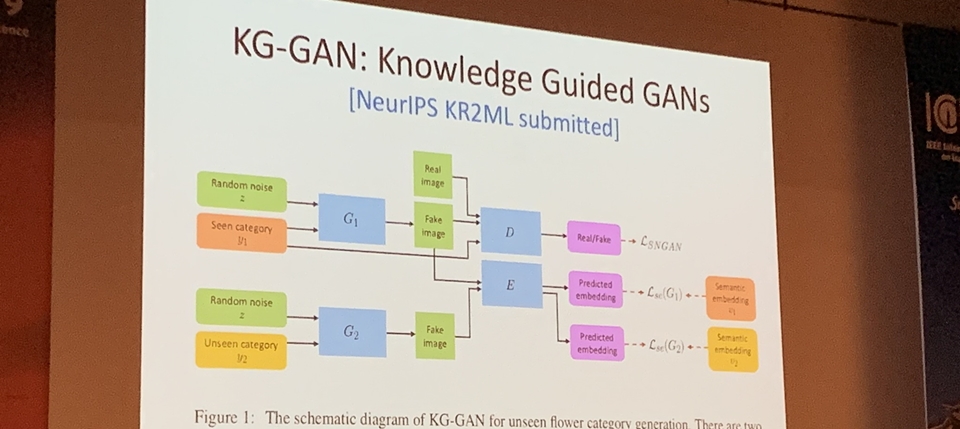
HTC健康醫療事業部DeepQ總經理張智威日前在國際旗艦型影像處理會議ICIP中,揭露了自家研發的知識型AI模型KG-GAN,要整合專業知識與GAN框架,來提高生成影像的多元性和精準度。一般來說,在訓練資料數量充足且多元的情況下,GAN可產生逼真多元的影像;但要是訓練樣本不足,就難以產生真實度高且具代表性的影像。
為改善這個問題,DeepQ團隊歷時一年開發出KG-GAN,整合AI最擅長的影像與自然語言。KG-GAN包含兩種生成器,一種是來學習影像資料,另一種來學習專業知識的語言。其中的原理,就是將專業知識化為約束函數,來導引生成器的學習,同時使鑑別器合理容忍生成影像的多元性。(詳全文)
iPhone AI研發中心 仿生晶片
臺灣微軟AI研發中心擴增,持續鎖定電腦視覺、使用者意圖認知和AI垂直產業應用
微軟日前宣布臺灣AI研發中心擴建落成,微軟雲端計算與人工智慧事業部全球資深副總裁郭昱廷表示,微軟十分看重電腦視覺領域的研究,去年在臺成立AI研發中心後,臺灣團隊短短一年就拿下了微軟總部的核心AI研發專案,包括3D人臉防偽辨識、文字OCR等電腦視覺應用,並交出漂亮成績單。也因此,微軟總部決定擴大在臺AI研發中心的規模。
除了持續鎖定電腦視覺應用,臺灣微軟AI研發中心未來還要發展使用者意圖認知和AI垂直產業應用。使用者意圖認知是要打造精準的使用者偏好模型,來開發更多貼近使用者行為的應用。臺灣團隊目前進行的專案中,其一就是關於使用者意圖認知的Bing廣告預測。而AI垂直產業應用則是臺灣微軟AI研發中心的長期目標,鎖定行政院5+2產業創新計畫中的智慧製造、智慧醫療,發展工業4.0,同時也要結合臺灣硬體產業,發展AI生態圈。(詳全文)

腦中風 AI資料庫 智慧醫療
臺美聯手建置全球腦中風AI資料庫,目標3年百萬筆來加速判讀AI的研發
負責建置美國國衛院(NIH)主要IT系統和大型資料庫的神經異常暨中風研究中心(NINDS)資訊科技與生物資訊部門主任范揚政指出,美國去年啟動醫療AI資料庫建置計畫,其中包括了與臺灣合作的全球腦中風影像資料庫(GSDR),要透過不同國家的腦中風資料集,來打造腦中風AI工具,提高急診準確率。
目前,這套資料庫有3大資料集,其中2個來自NINDS,約有6萬1千筆腦中風影像資料。另一個資料集則來自臺灣,收集了臺灣中風登錄(TSR)中14萬筆資料。范揚政指出,今年將與更多單位合作來擴增資料集,如美國醫療保險服務中心和英國政府,預估未來2、3年後,總資料量將超過100萬筆。今年中研院也聯合交大、陽明,共同成立數位醫學聯盟要打造腦中風資料集,並與NIH合作取得他們的腦中風分析資料,未來甚至包括歐洲、日本的資料,要打造因地制宜的腦中風AI模型。(詳全文)
Google 洪水氾濫預報 印度
Google打造洪水氾濫區域預測AI,要讓洪水預報更精準
Google日前針對印度巴特那地區,發表了一套可預測洪水氾濫區域的AI模型,要建立更準確的洪水預報系統。首先,這套模型需要準確的地面即時狀況,才能預測洪水範圍,因此Google與印度政府合作,由中央水利委員每小時收集印度各地的數千個水位高度表資料,並根據上游測量結果來預測洪水範圍,而Google就利用這些資料和預測結果,當作模型的輸入值。
接下來,Google利用Google Maps建立地形高程圖,透過地形變化來加強預測洪水的流向。有了這些資料,Google開始建立水力模型,並採用物理模擬的建模方法,透過物理定律來計算水流的位置和速度,Google表示,當輸入資料非常精確且經高解析度運算,則得到的結果也會非常準確。不過,這也讓運算時間隨之倍增,為此,Google利用TPU加速運算,也使用機器學習代替部分物理模擬演算法。除了水力模型,Google還使用歐洲太空總署累積的歷史資料集來修正預測模型。(詳全文)

Google Deepfake 偵測
Google貢獻Deepfake資料集助社群發展偽造影片偵測技術
AI造假影片的問題日益氾濫,臉書和微軟共同發起Deepfake偵測挑戰大賽,祭出上千萬獎金,要吸引高手幫忙開發辨識造假影片的技術,而Google現也於GitHub上釋出視覺化Deepfake資料集,要幫助社群共同開發偵測技術。
為製作這個資料集,Google與演員合作,拍攝了數百個影片片段,並且使用已公開的Deepfake技術,產生數千個Deepfake影片,這些真實與假造的影片都包含在Deepfake資料集中,並免費提供給社群研究使用,以促進開發偵測合成影片的技術。此外,Google也將持續擴增該資料集,並與其他組織一起於該領域合作。(詳全文)

科技部 人工智慧科研發展指引 AI科研環境
科技部發表人工智慧科研發展指引,要完善臺灣AI科研環境
歷經數月與各領域專家的討論,科技部日前與臺大、清大、交大、成大等4個AI創新研究中心共同發表「人工智慧科技研發指引」,以以人為本、永續發展、多元包容為核心價值,延伸出8項指引,包括共榮共利、公平性與非歧視性、自主權與控制權、安全性、個人隱私與數據治理、透明性與可追溯性、可解釋性和問責與溝通等,要來定調臺灣AI科研的發展環境。
其中細節包括了AI研究人員應遵依資料來源,並明確記錄、保存與追蹤原始碼,此外也應注重程式碼與演算法等需具可解釋性,而且要能在應用介面有問題時介入或中止。科技部也期望獲得各界建議、凝聚共識,來精進這項指引。(詳全文)
臺北市警察局 影像辨識 違規停車
臺北市警察局將啟動科技執法,要靠影像辨識開單違停車輛
臺北市警察局日前宣布將利用影像辨識系統,來自動針對違停車輛開單,首波瞄準市府轉運站前公車停靠區,要改善公車難以貼近人行道靠站、輪椅族難以上下公車和機車鑽行的現象。
臺北市警察局表示,目前已針對該區域展開測試、演練科技執法,24小時無間段監控公車停靠區域的違停車輛,只要停止超過3分鐘,就會自動執行違規蒐證並舉發。違規者可處新臺幣600元以上1,200元以下罰鍰。(詳全文)

攝影/王若樸 圖片來源/Google、jo6bj03、微軟
AI趨勢近期新聞
1. GitHub發布CodeSearchNet語料庫以及挑戰賽,推動自然語言程式碼搜尋技術發展
2. 微軟正式推出雲端SIEM服務,新增機器學習模型偵測惡意SSH存取
3. AWS推出採用Nvidia T4 GPU的EC2實例,加速AI應用及圖形運算
資料來源:iThome整理,2019年10月
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-06


2026-03-09