方法。")
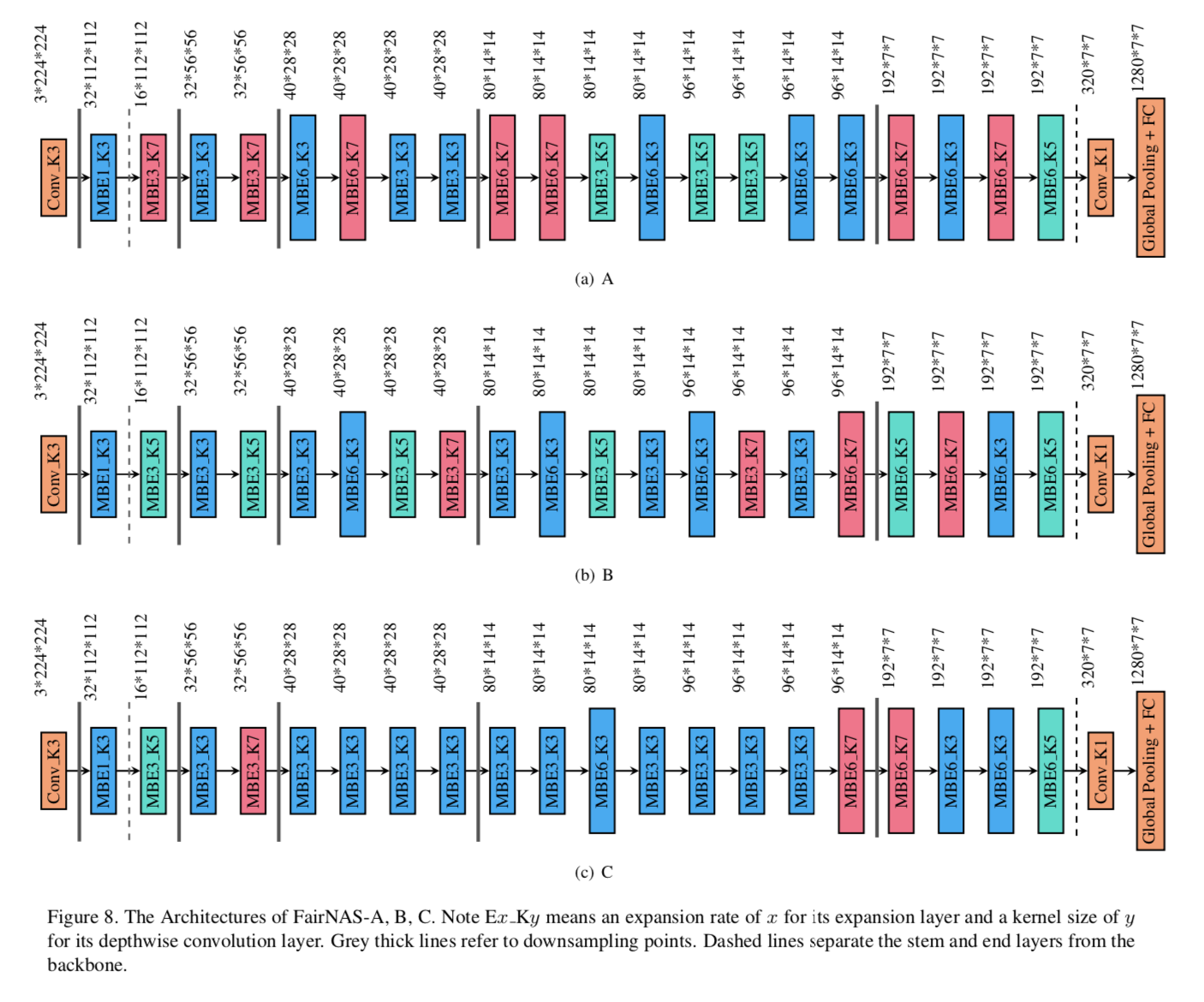
3家中國科技龍頭開源自家SOTA等級的研究,包括阿里巴巴達摩院開源準確度達94.1%的新一代人機對話模型ESIM,百度開源自駕車系統Apollo 5.0,提供進階深度學習感知模型,還有小米開源公平神經架構搜尋(FairNAS)方法。
重點新聞(0712~0718)
阿里巴巴 開源 小米
阿里巴巴、百度、小米開源自家SOTA等級的研究
近日3家中國科技龍頭開源自家SOTA等級的研究,包括阿里巴巴、百度和小米。其中,阿里巴巴達摩院開源新一代人機對話模型ESIM,曾在由微軟和卡內基美隆大學舉辦的國際對話系統挑戰賽中拿下雙冠軍,將人機對話準確度的世界紀錄提高至94.1%,也已應用於中國地鐵訂票系統。百度則開源自駕車系統Apollo 5.0,提供進階的深度學習感知模型和360度可視性,來因應複雜的道路狀況。
小米AI實驗室則開源公平神經架構搜尋(FairNAS)方法,該方法在訓練和繼承過程中給予嚴格的公平性,主張公平的採樣方式和訓練可發揮各模組優勢。結果顯示,FairNAS的超網(Superweb)展現良好的收斂性和極高的準確度,其中,FairNAS-A在ImageNet上Top-1驗證準確度為75.34%,FairNAS-B則是75.10%。
Google 資料回音 模型訓練
Google Brain發表新技術「資料回音」要加速AI模型訓練時間
Google Brain提出一套資料回音(Data Echoing)新方法,要來加速I/O和資料前處理等AI加速器無法派上用場的初期工作流程,讓整體AI模型訓練更快速。
在典型的訓練流程中,AI系統會先讀取輸入的資料並解碼,再將資料交錯運算、採用資料增強(Data augmentation),接著將樣本集合批次處理,並迭代更新參數以減少錯誤。研究團隊的資料回音方法,就是在這個流程中新增一個階段,也就是在參數更新前,重複輸出前一階段的資料,來善用閒置的運算能力。實驗時,團隊用資料回音演算法來評估以開源資料集訓練AI模型的時間,包括2個語言建模任務、2個影像分類任務和1個物體偵測任務,結果發現,資料回音可減少訓練AI模型所需的樣本,而且在工作流程中越早進行資料回音,所減少的樣本也就越多,來優化整個流程。(詳全文)

DeepMind BigBiGAN 影像生成
DeepMind打造超強影像生成模型BigBiGAN
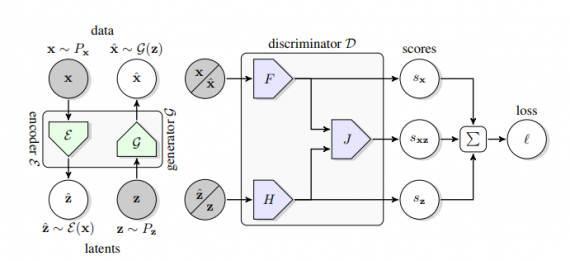
DeepMind近日發表了一款非監督特徵學習新模型BigBiGAN,也就是一款雙向GAN模型,結合了時下最先進的2種GAN模型:BigGAN和BiGAN,並以BigGAN為生成器,透過新增編碼器和修改鑑別器,來提高其特徵學習的表現,同時改善了BiGAN的DCGAN架構無法對高解析度影像建模的問題。
在實驗中,研究員利用ImageNet上未標註的影像資料來預訓練BigBiGAN,並利用標註的資料來訓練一層線性分類器。實驗結果發現,BigBiGAN可以提高非監督學習,將top-1準確度從55.4%拉升至60.8%。(詳全文)
Google Nvidia MLPerf
Google和Nvidia打破ML基準測試MLPerf紀錄
Google和Nvidia贏過40多家科技界和學術界龍頭,創下MLPerf競賽最新紀錄,在6項ML模型基準測試中拿下最快訓練時間紀錄。MLPerf是一項業界用來衡量ML模型性能的基準測試,測量類別包括影像分類、物體偵測、翻譯、下圍棋等。這次競賽吸引40多家科技龍頭和頂尖大學的AI研究員參加,像是Google、Nvidia、AMD、臉書、英特爾、阿里巴巴、百度等。
其中,在輕量物體偵測和非迴歸翻譯任務中,Google Cloud TPU v3 Pod訓練Transformer和物體偵測SSD模型的時間,比起時下最快的on premise系統,還要快上84%。而Nvidia Tesla V100 Tensor Core GPU表現也十分出色,搭配自家DGX SuperPOD,將ResNet-50影像分類的訓練時間縮短至80秒;2年前,Nvidia用DGX-1系統和V100 GPU,也要花8個小時才能完成。(詳全文)
臉書 CMU 撲克牌
心理戰沒在怕!臉書與CMU共同打造的AI機器人擊敗5名德州撲克專家
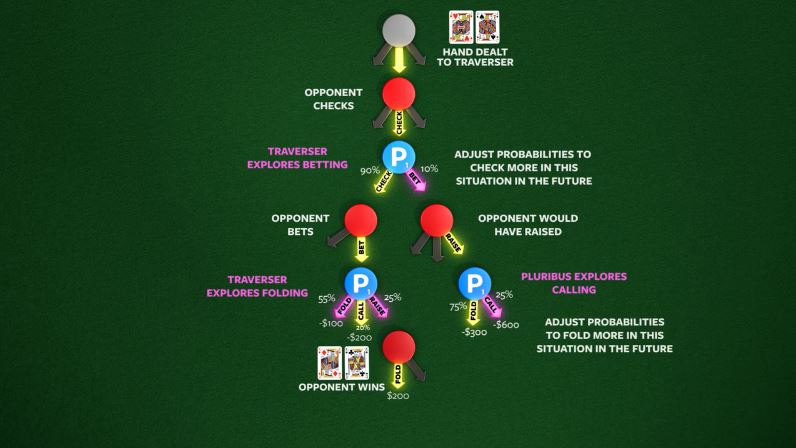
臉書近日與卡內基美隆大學(CMU)共同開發的AI機器人Pluribus,已在無限注的賽局中打敗5名德州撲克專家,立下新的AI里程碑。在德州撲克中,較勁的不只是牌運,還有牌值的機率與下注時的心理戰,過去已有AI能夠在德州撲克中擊敗單一對手,而Pluribus則是一次擊敗牌桌上5名專家,其中兩名還是世界撲克大賽冠軍。
Pluribus除了利用新的網路搜尋演算法來評估可能的選項外,也採用新的自我對奕演算法來應付隱藏資訊,這些技術讓Pluribus的訓練更有效率,只使用少量記憶體資源,換算成雲端運算資源支出才150美元。Pluribus的特別之處在於它捨棄了雙人對奕所使用的零和博弈政策,而是建立一個憑經驗持續擊敗眾多高手的AI;也創造出一個可察覺隱藏資訊的AI機器人。(詳全文)
Hadoop Cloudera 大數據
Cloudera宣布商業授權將完全採用訂閱制
Cloudera發布新的開源授權模式,將在接下來幾個月內推出。該公司目前正在進行更新授權的前置工作,在未來6個月內,Cloudera會將少量閉源授權的專案,如Cloudera Manager、Cloudera Navigator和Cloudera Data Science Workbench等轉換成開源授權,用戶需要訂閱才能獲得專業支援。而Cloudera所使用的開源授權,將採由OSI認證的授權模式,包括Apache License v2與AGPL v3兩種。
雖然Cloudera是開源專案的主要貢獻者,但是過去其商業模式仍主要是銷售授權軟體,而今年1月整併Hortonworks之後,Cloudera打算採用Hortonworks的開源商業模式,並宣布將使用類似紅帽等企業的開源戰略,提供訂閱制。Cloudera會為開發人員和試用提供無支援的免費版本,並向商業用戶提供訂閱付費的版本,訂閱協議涵蓋了支援以及維護,用戶將能存取最新的更新以及安全補丁。(詳全文)
CES 科技部 新創
前進CES 2020!科技部號召80組新創團隊,要打響臺灣新創名聲
科技部宣布明年要三度帶領臺灣新創團隊赴美參加世界科技廠商盛會CES,即日起開放新創團隊徵案,也號召地方政府新創育成計畫中的新創加入,報名截止日為8月15日,獲選結果將於9月16日公告。科技部次長許有進表示,自2018年來,科技部開始帶領臺灣新創團隊赴CES參展,更設置臺灣館來吸引國際目光;前年,臺灣參展團隊為32組,今年則是44組,範圍涵蓋車聯網、智慧零售、智慧醫療、智慧寵物等領域,其中更有8組獲得新創大獎,獲獎數全球第二,也拿下55億新臺幣訂單,科技部更決定明年要帶80組新創團隊進駐CES臺灣館。
如同以往,今年徵選結果公布後,科技部將於10月進行Boot Camp,請來矽谷業師1對1輔導新創團隊簡報技巧,以及如何將商業模式調整為符合美國市場所需。CES結束後,科技部也將帶領臺灣新創制矽谷參加臺灣Demo Day,讓團隊直接與國外創投、加速器和TA等面對面交流。(詳全文)

神經機器翻譯 Googl 即時翻譯
納入神經機器翻譯技術,Google翻譯App再升級!
Google翻譯App中的即時鏡頭翻譯功能再升級,除了將支援語言新增至100多種,還納入了神經機器翻譯技術(NMT),讓即時翻譯更精準。Google表示,Google翻譯App中的即時鏡頭翻譯,可將畫面中的文字翻譯為另一種語言,也支援離線使用。而這次功能更新,則將原本支援的88種語言新增至100種以上,包括了阿拉伯文、印度文、馬來文、泰文和越南文等,而且還可選擇英文以外的翻譯,比如將阿拉伯文譯為法文,這是舊版所沒有的。
此外,Google還在這次更新加入了NMT,提高譯文的準確性和自然性。因為,相較於傳統的片語機器翻譯(PBMT),NMT將整個句子視為1個翻譯單位,而非將句子分解為片語和單字,降低了逐字翻譯的錯誤。而Google開發的GNMT利用零點翻譯(Zero-shot),使兩種語言可直接互譯,不需要透過英語作為中介語。(詳全文)

圖片來源/小米、Google、臉書、科技部
AI趨勢近期新聞
1. 亞洲生技大會首次登臺!聚焦精準醫療、AI應用和細胞與基因治療,7/24開跑
2. 微軟發起AI救文化遺產計畫
3. 卡內基美隆大學發表Language2Pose模型,可將文字轉換為動畫
資料來源:iThome整理,2019年7月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02