Nvidia宣布開源用於其GPU與深度學習加速器上的高效能推理函式庫TensorRT,這個函式庫以C++撰寫,建構於平行可程式化模型CUDA之上,提供精度INT8和FP16的最佳化之外,也支援多種平臺,包括嵌入式、自動駕駛以及GPU計算平臺,同時也讓用戶可以將神經網路部署到資料中心,以容器化微服務技術同時執行多個模型。
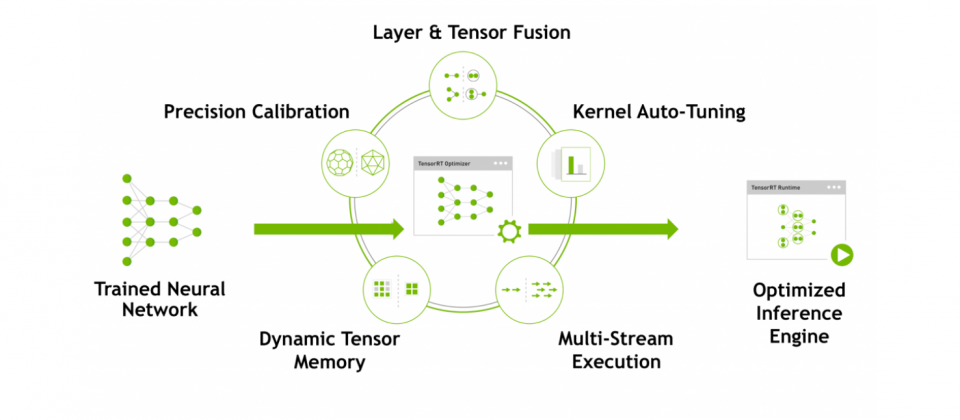
TensorRT是一個高效能的深度學習推理平臺,使用者可以將訓練好的神經網路輸入TensorRT中,產出經最佳化後的推理引擎。TensorRT主要包含兩部分,有用來進行調校的深度學習推理最佳化工具,以及能執行深度學習推理應用程式的Runtime,Nvidia提到,使用TensorRT的應用程式,比起CPU平臺的執行速度還要快40倍。
TensorRT建構在CUDA之上,因此開發者可以使用CUDA-X AI中的函式庫以及開發工具,開發無人機、高效能運算以及圖學等應用。TensorRT提供了精度INT8和FP16最佳化,可用於加速圖像串流、語音辨識、推薦以及自然語言處理等深度學習推理應用,Nvidia表示,低精度推理能夠大幅地減少應用程式延遲,符合更多即時服務、自動化與嵌入式應用程式的需求。
TensorRT支援熱門框架訓練出來的神經網路模型,無論TensorFlow和MATLAB,或是ONNX模型格式都可進行最佳化,並將模型導入TensorRT進行推理。TensorRT在去年就整合了TensorFlow,版本是TensorFlow 1.7分支,這項整合為開發者提供了簡單使用的API,提供FP16與INT8最佳化,官方表示,這項整合可為TensorFlow在ResNet-50基準測試,提高8倍的執行速度。
熱門的多範式數學計算環境和語言Matlab,透過CUDA程式碼產生器GPU Coder整合了TensorRT,因此使用Matlab的開發人員,也可以將程式碼轉成嵌入式平臺Jetson、自動駕駛平臺DRIVE與Tesla GPU平臺的高效能推理引擎。
而對於開放的神經網路格式ONNX,TensorRT提供開發者ONNX解析器,讓開發者將ONNX模型從Caffe 2、Chainer、微軟認知開發工具、MxNet和PyTorch等框架中輸入到TensorRT中。由於TensorRT也與ONNX Runtime整合,因此為ONNX格式的機器學習模型,帶來簡單就能實現高效能推理的方法。
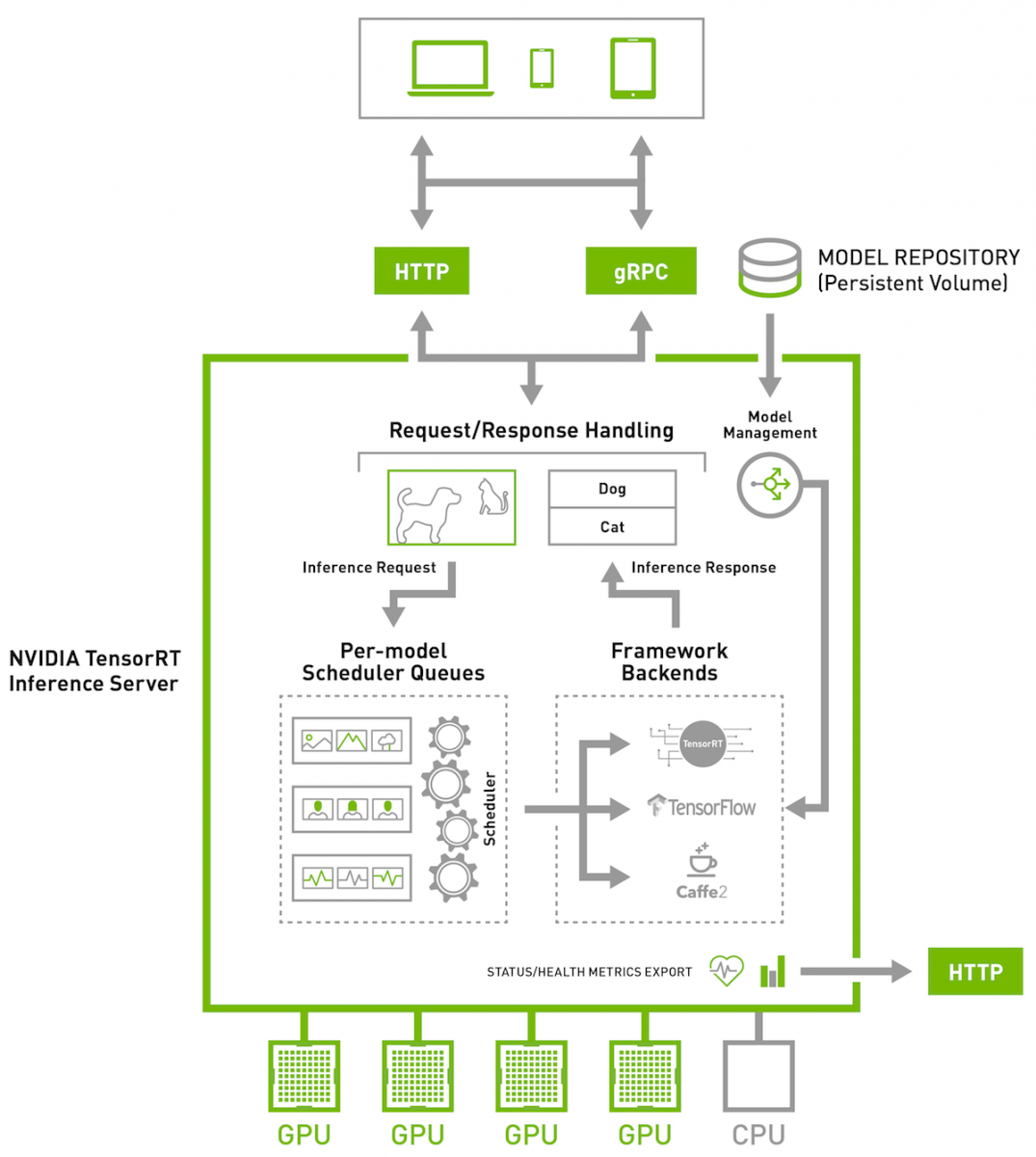
TensorRT除了讓開發者可以將神經網路最佳化,在Jetson、DRIVE與Tesla平臺上執行外,也最大程度的支援大規模資料中心。為支援在資料中心執行的人工智慧模型,TensorRT使用稱為推理伺服器(下圖)的容器化微服務技術,利用Docker以及Kubernetes,不只可以最大化GPU使用率,也能無縫整合DevOps部署,讓使用者可在多節點同時執行來自不同框架的多個模型。
熱門新聞

2026-03-06





2026-03-06

2026-03-09