
微軟
微軟研究院最近介紹了透過知識蒸餾法(distillation),來改善多任務深度神經網路(Multi-Task Deep Neural Network, MT-DNN)的研究,打造出更穩固且通用的自然語言理解模型,微軟將多個整體(ensembled )模型,透過知識蒸餾法,訓練出單一個穩固且通用的MT-DNN。
微軟表示,整體學習是改善自然語言處理模型最有效的方法之一,目前已被廣泛地應用在NLU任務中,不過,整體學習通常由數十至數百種不同的神經網路模型組成,因此運算和部署成本相當昂貴,微軟結合了Google AI開源的雙向語言轉換模型BERT,並採用了知識蒸餾法來解決這個問題。
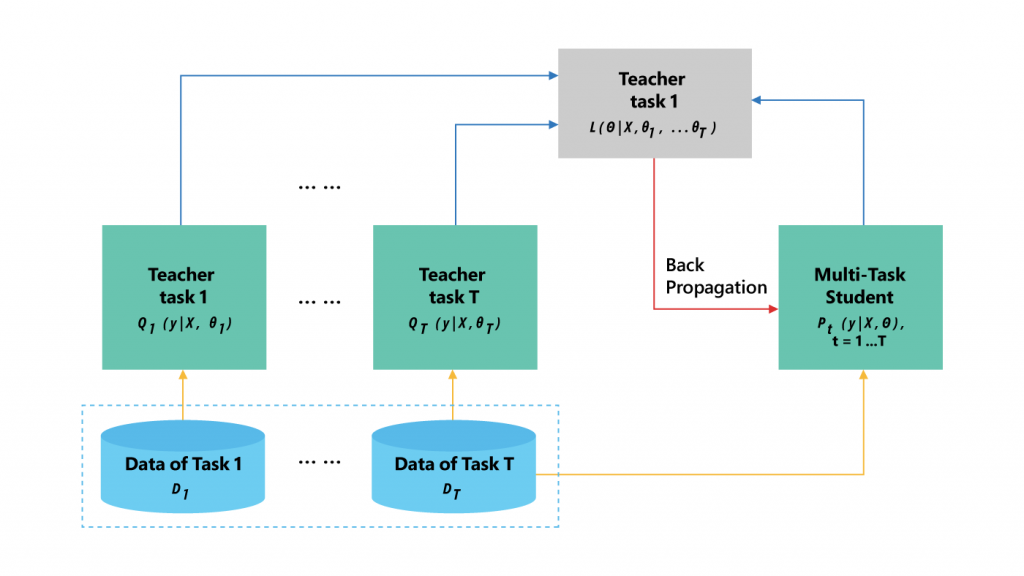
知識蒸餾法是從訓練好的大型模型中,將學習到的知識遷移到更適合推理的小型模型,微軟首先利用整體模型,訓練出每個訓練樣本的預測輸出soft targets,soft targets是來自大型模型的預測結果,包含的訊息量較大,擁有不同類型之間的訊息,舉例來說,「我與Tom進行了一場有趣的對話」這句話的情緒分類可能為正面,也有可能是負面,必須依據上下文來判斷,接著,再用橫跨不同任務輸出的soft targets和正確的targets,透過多任務學習來訓練單一個MT-DNN,此時MT-DNN就是扮演學生的角色。
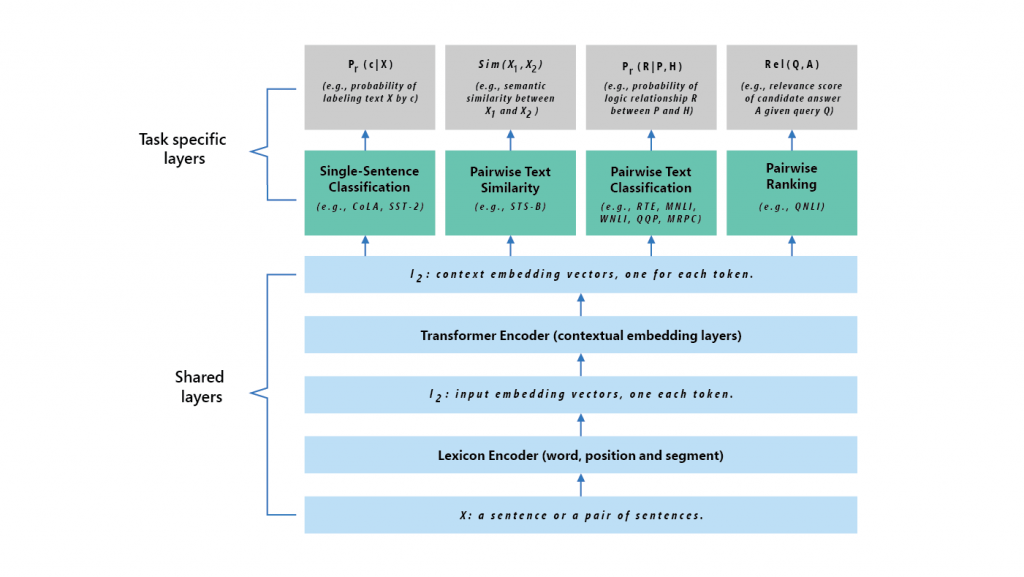
MT-DNN學生模型的實驗架構分為共享層和特定任務層兩個部分,輸入一個語句後,會先將語句轉換為詞向量表示法,接著轉換編譯器會針對每個字擷取上下文的資訊,並產生共享的上下文詞向量,最後,針對每個任務,特定任務層會根據必要的處理,像是分類、相似度評分、關係排序等,生成特定任務的表示法,MT-DNN共享層一開始是用Google雙向語言轉換模型BERT訓練,接著再用多任務學習共同訓練。(圖片來源:微軟)
而多任務學習的知識蒸餾過程,不同神經網路會針對不同任務分別訓練,神經網路擔任教師的角色,這些教師神經網路會為每個特定任務,生成soft targets,MT-DNN學生網路就透過多任務學習來學習特定任務。(圖片來源:微軟)
相比BERT模型和一般MT-DNN模型,經過知識蒸餾法訓練的MT-DNN模型,在常用自然語言理解評估標準GLUE有較佳的表現,顯示該模型更加的穩固且通用,微軟也計畫在6月於GitHub上開源釋出MT-DNN模型,釋出的模型將包含預先訓練的模型、程式碼,以及步驟式的解說。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02