
Uber公開其GPU即時分析引擎AresDB的細節,不只會對資料欄進行壓縮,提升儲存以及查詢效率,還內建GPU查詢處理功能,可支援大量平行資料處理。
Uber仰賴分析資來決策,營運團隊需監控市場健康程度,或是以機器學習預測乘客與司機的供需。過去Uber使用第三方資料庫進行即時分析,但都無法滿足Uber的所有需求。Uber主要有三種使用情境,第一種,建立儀表板以監控業務指標,第二種,根據匯總的指標,自動作出決策,像是自動定價和詐欺偵測,第三種則是進行特殊的即時查詢,以診斷和解決營運問題。

這三種情境的查詢需求都不同,特殊查詢通常是對全部資料進行查詢,可以忍受較高的延遲,而儀表板以及決策系統則都需要較高每秒查詢次數,使用新的資料子集。Uber提到,最常見的即時分析用途是,計算時間序列聚合,Uber會計算特定時間範圍內特定維度的指標,用於提升服務。
過去Uber曾用了Apache Pinot以及Elasticsearch第三方解決方案,但都有部分缺點不符合Uber的需求。Apache Pinot是一個以Java撰寫,用於大規模資料分析的分散式分析資料庫,但是其不支援使用金鑰去除重複資料的功能,也不支援插入更新(Upsert)、連接(Join)等進階查詢功能,而且因為是JVM資料庫,Pinot的查詢執行會使用更多的記憶體。
另外,Elasticsearch則是沒有針對時間範圍的儲存和過濾進行最佳化,而且其紀錄儲存成JSON檔案,會增加額外的儲存與查詢成本,也與Pinot一樣,因為是JVM資料庫,查詢執行記憶體成本相對較高。
為了解決這些問題,並且利用GPU加速資料處理,Uber自行開發了GPU即時分析引擎AresDB。AresDB會將大部分的資料儲存在主機記憶體中,使用CPU進行資料擷取,並且透過硬碟進行資料恢復。在查詢時,AresDB會將資料從主機傳輸到GPU記憶體,以便使用GPU進行處理。
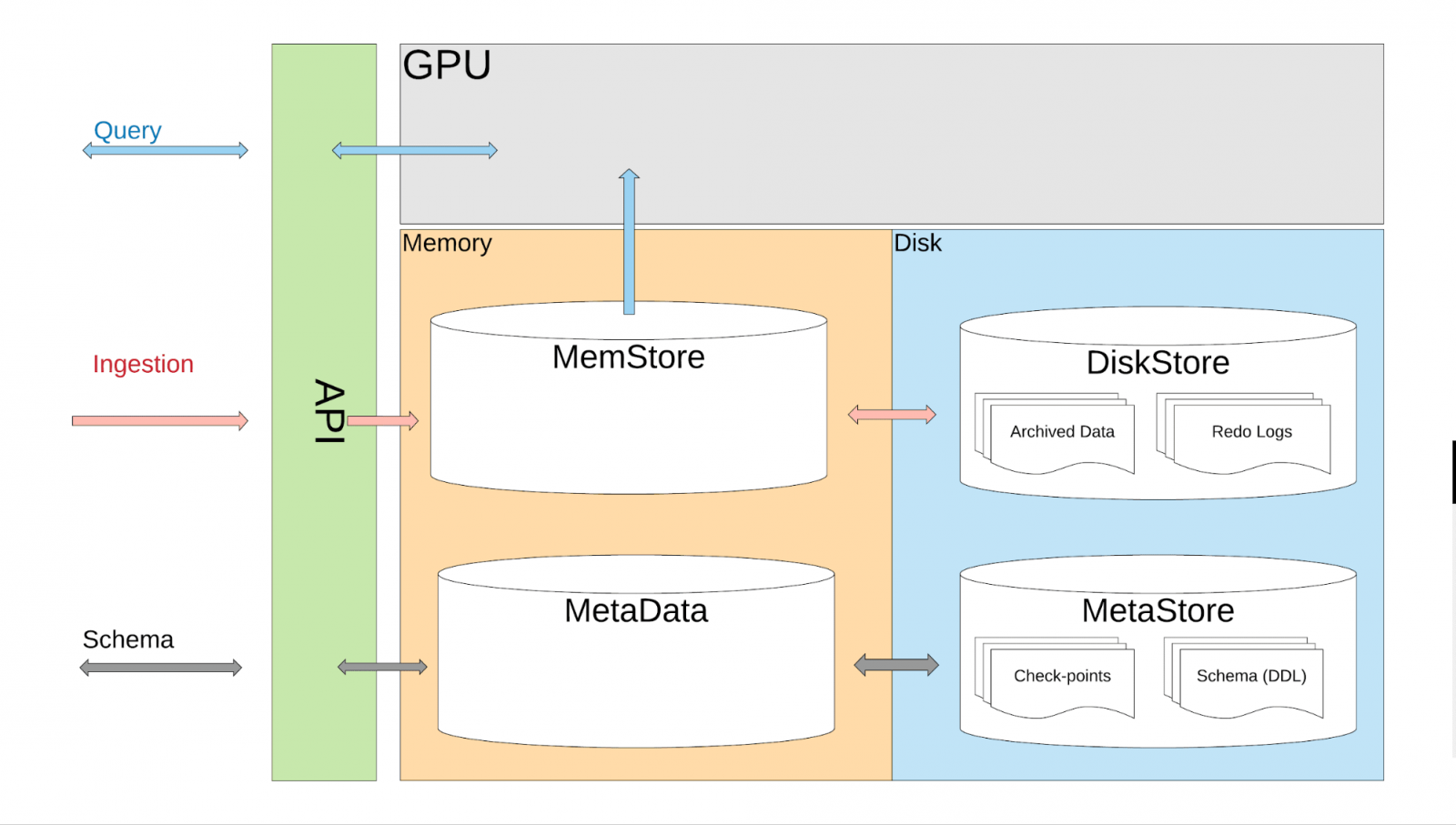
AresDB主要有三大特點,首先是壓縮資料欄儲存,如此不只因為儲存資料的位元組,使用較少的記憶體增加了儲存效率,也因為傳輸的資料較少,從CPU搬移資料到GPU的時間更短,所以增加了查詢效率。還能進行即時插入更新(Upsert)使用主鍵去除重複資料,在數秒鐘時間區間,維持高資料精確度以及資料新鮮度。而且AresDB內建GPU查詢處理,可以使用GPU進行高度平行資料處理,提供毫秒至秒的低延遲查詢。
Uber提到,字串進入資料庫前,就會將其轉換成列舉類型(Enumerated Type),以提高儲存和查詢效率,並支援區分大小寫的相等檢查。AresDB目前尚不支援Concatenation、擷取字串、Glob以及正規表示式匹配等進階功能,Uber將會在未來陸續增加。
Uber正改造AresDB採用分散式設計,提供複製、分片管理和架構管理,以提升其可擴展性並降低營運成本,Uber也計畫擴展AresDB的查詢功能集,增加包括視窗函式和巢狀循環連接(Join)等功能,在查詢引擎最佳化上,也會應用LLVM和GPU記憶體快取加速查詢效能。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02