
InfluxData釋出其開源時序資料庫InfluxDB 2.0 Alpha測試版,這個版本最大的更新,便是增加了新的資料腳本和查詢語言Flux,不只能提供跨平臺時序資料操作,還能將TICK元件堆疊整合成一個更加一致的平臺。
InfluxDB是一個以Go語言開發的開源時序型資料庫,由InfluxData重頭開始打造,專門用來處理高寫入和查詢負載,InfluxDB專為時間戳記資料設計,可應用於DevOps監控、應用程式指標、物聯網感測器資料和即時分析等使用情境。InfluxDB提供類似SQL的查詢語言,供使用者操作資料。
InfluxDB 2.0最大更新的部分,是新增了資料腳本和查詢語言Flux。InfluxData在收集了社群的意見,以及盤點了當前查詢語言InfluxQL,和Kapacitor合作的語言TICKscript之後,他們決定建構一個全新的查詢語言。
Flux支援驅動圖形使用者介面,讓使用者不需要實際學習語言,就可完成工作。Flux還能跨不同資料來源,包括資料庫、第三方API、檔案系統或其他資料來源,進行時間序資料操作。Flux能與其他分析工具和環境無縫整合,支援多種查詢語法,包括Jupyter以及使用Apache Arrow作為底層資料交換的格式,以便和其他大資料分析系統整合。
InfluxData提到,Flux是第四代程式開發語言,是專為資料腳本、ETL、監控和通知而設計。Flux不僅是一個查詢語言和程式語言,其中還包含了Planner以及Optimizer,可以無縫的提供開發者查詢以及程式開發能力。
而Flux最大的特點在於能夠交叉編譯,InfluxData希望使用者可以使用不同的語言,像是InfluxQL、PromQL以及Flux等,操作時間序列的資料與相關查詢工作,InfluxData表示,他們希望這項工作可以在單一Optimizer進行,並對許多不同的來源進行規畫。由於開發者使用的語言很多種,因此支援更多的語言將有助於擁抱更廣的生態系。
Flux具圖靈完備性(Turing Completeness),且不僅可用於查詢和處理時間序列資料,也可以用於操作一般資料。在這個版本中,官方專注於嵌入式InfluxDB 2.0資料儲存的查詢能力,包括跨量測的數學功能、Top N、時間偏移、欄位聚合,以及排序。官方提到,要為語言增加新功能並不容易,在接下來的幾個月會繼續釋出更多Flux的特殊功能。
InfluxData平臺由4個元件組成,分別是資料收集器Telegraf、時間序列資料庫InfluxDB、視覺化介面Chronograf以及監控服務Kapacitor,取字首簡稱TICK。由於這四個元件在功能劃分以及對用戶的友善程度,於社群中一直存在不同的看法,因此Flux的出現可以用來解決這些問題,也簡化InfluxQL和TICKscript這兩種查詢語言的功能操作。
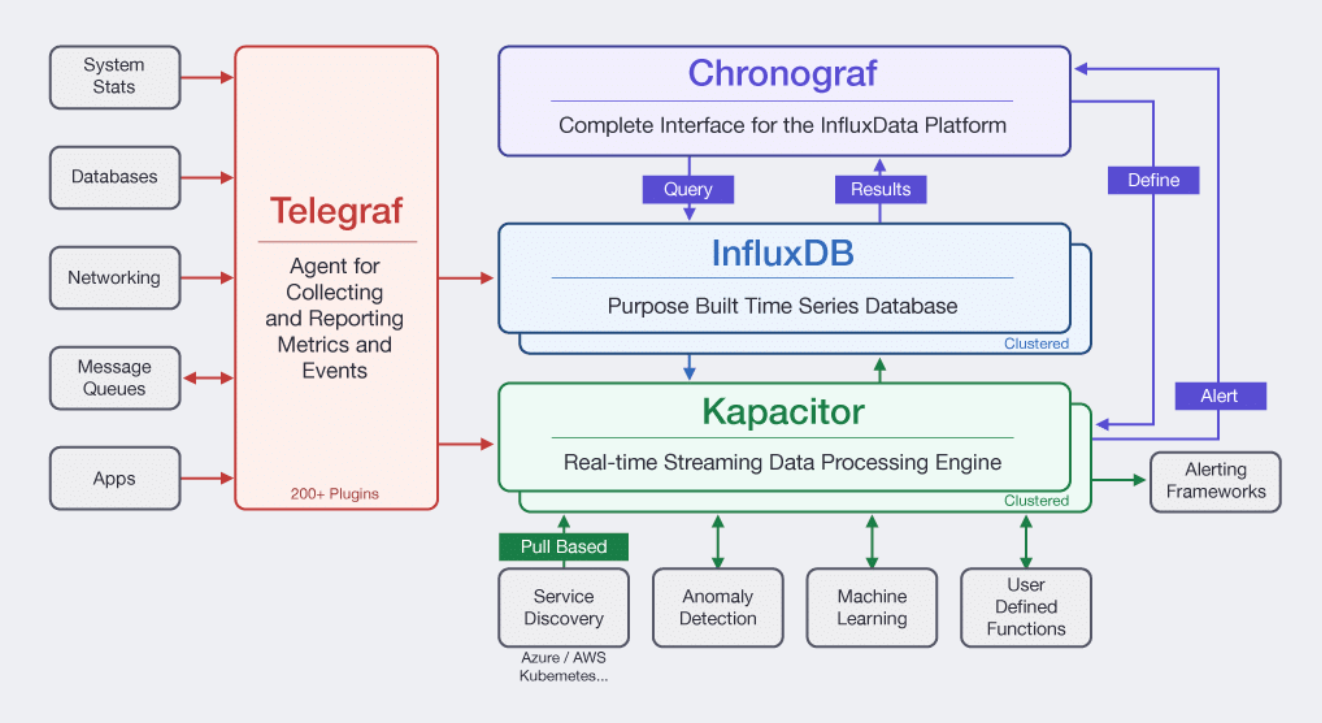
另外,在InfluxDB 2.0中,InfluxData創建了一個統一整個平臺的API,其目的是要讓InfluxDB成為一個多租戶的時間序列服務,由於TICK這些元件,InfluxDB不只是一個資料庫,同時還提供了監控、儀表板引擎、資料分析以及事件和指標處理器。隨著Flux的功能擴展,InfluxDB的功能和範圍,也將隨之擴大。
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-06

2026-03-05

2026-03-06