圖片來源:
AWS
AWS近日更新了自然語言理解服務Amazon Comprehend,推出客製Entity辨識模型的功能,讓不懂機器學習的開發人員,也能訓練自家的Entity辨識模型,來自動萃取特定的字詞,AWS強調,這項服務不需要ML背景,透過自家現有的資料,即可用該功能輕鬆創建客製化模型,像是各個機構需要的客戶編號、序列號碼等。
Amazon Comprehend是AWS在去年AWS開發大會上發布的一項自然語言處理服務,能夠分析98種語言,並辨識這些語言所指稱的內容,像是人名、地點、品牌或產品等,也能理解語言中的關鍵句子與情緒,以於大量的文件或內容中依照主題加以建模或分類。
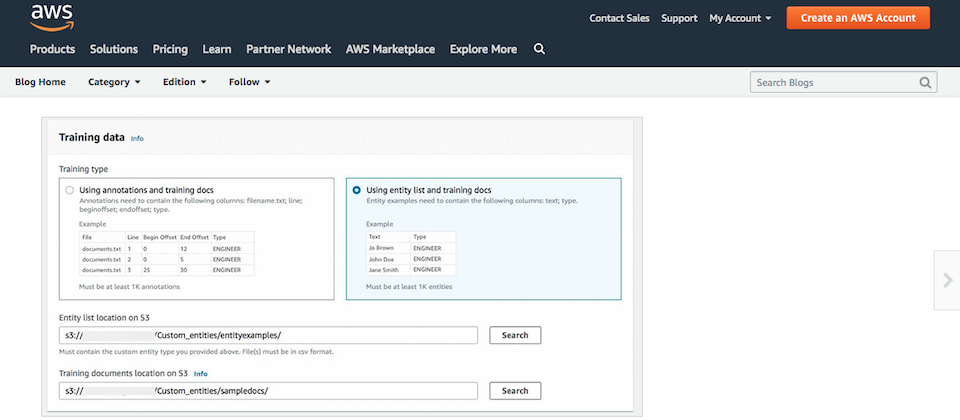
企業要使用這項客製化模型服務,首先,要準備包含Entity和Entity類別的清單資料庫,並至少用1,000個包含一個以上Entity的文件,作為訓練資料集,配置訓練模型的過程,則是先讀取清單中的Entity資料,再用其他文件來訓練模型,訓練過程可能需要幾分鐘,或是幾小時的時間,視訓練資料的大小和複雜度而定,透過自動化的機器學習,Amazon Comprehend會選擇正確的演算法,優化模型找出最適合的組合,當訓練完成後,開發者就可以使用客製化的模型。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09

Advertisement