
最左邊一行為原始影像,中間一行為手動標註結果,最右一行為採用機器學習的流體標註結果。
Google在ACM多媒體會議2018上,發表一種以機器學習驅動的圖片標註介面,讓使用者快速的為圖片中物體標記出輪廓以及標籤,提高整體標記速度達三倍。
由於現代基於深度學習電腦視覺模型的性能,取決標籤訓練資料的多寡,越大的資料集將能讓機器學習有更好的表現。Google在許多深度學習的研究都一再提到,高品質的訓練資料取得並不容易,而這個問題已經成為發展電腦視覺的主要瓶頸,對於諸如自動駕駛、機器人或是圖片搜尋等這類以像素為辨識基礎的工作更是如此。
傳統的方法需要使用者手動以標記工具,圈出圖片中物體的邊界,Google提到,使用COCO加Stuff資料集,標記一個圖片需要19分鐘,標記完整個資料集需要53,000個小時,太過耗時沒效率。因此Google探索了全新的訓練資料標記方法-流體標註(Fluid Annotation),能以機器學習幫助使用者快速找出圖片物體輪廓上標籤。
流體標註從強語義分割模型的輸出開始,使用者能以自然的使用者介面,藉由機器學習輔助進行編輯和修改,介面提供使用者需要修正的物體以及順序,讓人類能夠專心於那些機器尚無法辨識清楚的部分。為了標註圖片,Google預先以約一千張具有分類標籤和信任分數的圖片訓練了語意分割模型(Mask-RCNN),具有最高信心的片段(Segment)能被用於初始標籤中。
流體標註能夠為使用者產生一個短清單,透過點擊就能快速為物體上標籤,而使用者也可以增加範圍標記,來覆蓋沒被偵測出來的物體,並透過滾動選擇最佳的形狀。另外,除了能夠增加,也能刪除既有的物體標記或是變更物體深度順序。
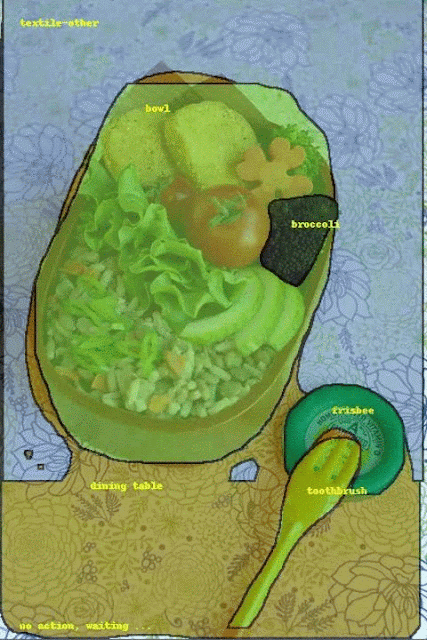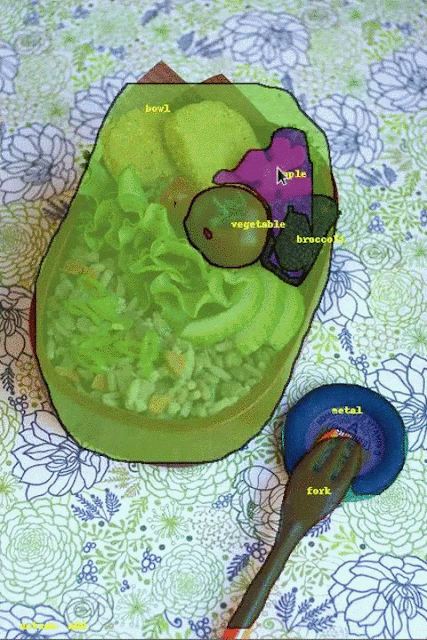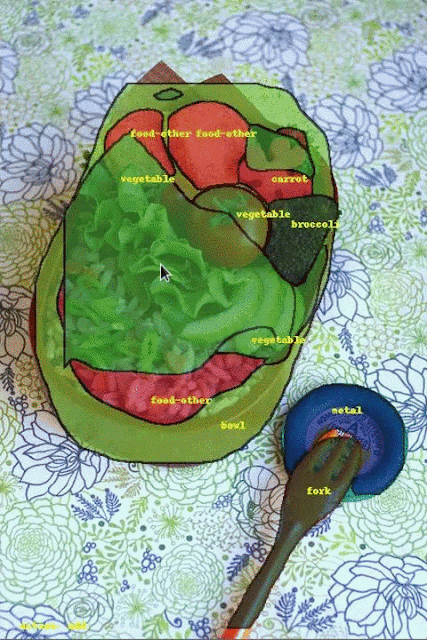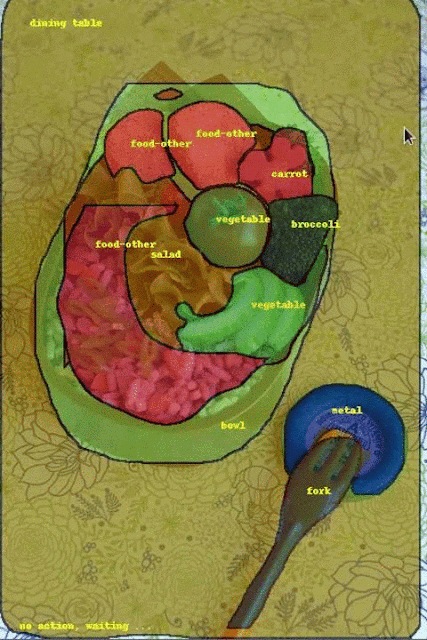
目前這一階段的流體標註的目標是讓圖像更快更容易,提高整體資料集標記速度達三倍。接下來Google要改進物體邊界標記,並以更多的人工智慧加速介面操作,擴展介面以處理現在無法辨識的類別。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02